 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEnet: A Metric Expression Network for Salient Object Segmentation
May 15, 2018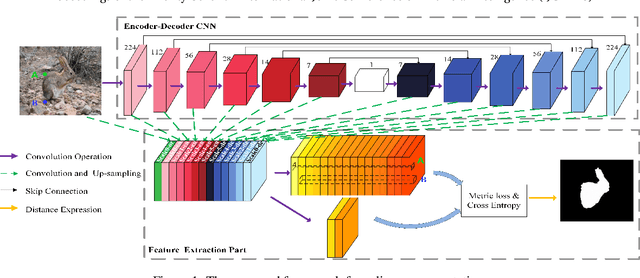



Recent CNN-based saliency models have achieved great performance on public datasets, however, most of them are sensitive to distortion (e.g., noise, compression). In this paper, an end-to-end generic salient object segmentation model called Metric Expression Network (MEnet) is proposed to overcome this drawback. Within this architecture, we construct a new topological metric space, with the implicit metric being determined by the deep network. In this way, we succeed in grouping all the pixels within the observed image semantically within this latent space into two regions: a salient region and a non-salient region. With this method, all feature extractions are carried out at the pixel level, which makes the output boundaries of salient object fine-grained. Experimental results show that the proposed metric can generate robust salient maps that allow for object segmentation. By testing the method on several public benchmarks, we show that the performance of MEnet has achieved good results. Furthermore, the proposed method outperforms previous CNN-based methods on distorted images.