 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Text Generation by Seeding Large Language Model Prompts
Feb 18, 2025



We explore how private synthetic text can be generated by suitably prompting a large language model (LLM). This addresses a challenge for organizations like hospitals, which hold sensitive text data like patient medical records, and wish to share it in order to train machine learning models for medical tasks, while preserving patient privacy. Methods that rely on training or finetuning a model may be out of reach, either due to API limits of third-party LLMs, or due to ethical and legal prohibitions on sharing the private data with the LLM itself. We propose Differentially Private Keyphrase Prompt Seeding (DP-KPS), a method that generates a private synthetic text corpus from a sensitive input corpus, by accessing an LLM only through privatized prompts. It is based on seeding the prompts with private samples from a distribution over phrase embeddings, thus capturing the input corpus while achieving requisite output diversity and maintaining differential privacy. We evaluate DP-KPS on downstream ML text classification tasks, and show that the corpora it generates preserve much of the predictive power of the original ones. Our findings offer hope that institutions can reap ML insights by privately sharing data with simple prompts and little compute.
Explaining a machine learning decision to physicians via counterfactuals
Jun 10, 2023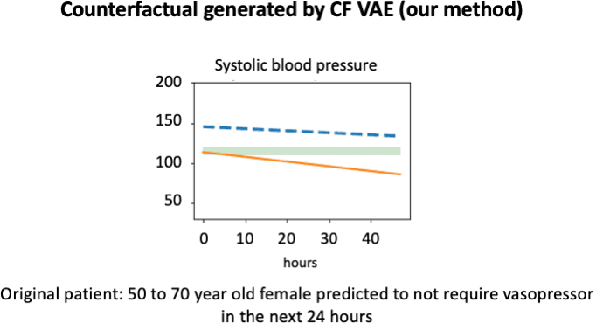
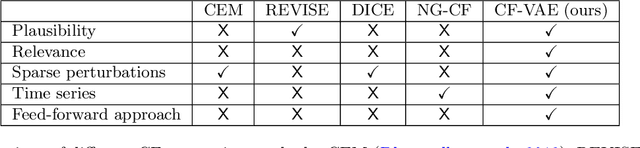
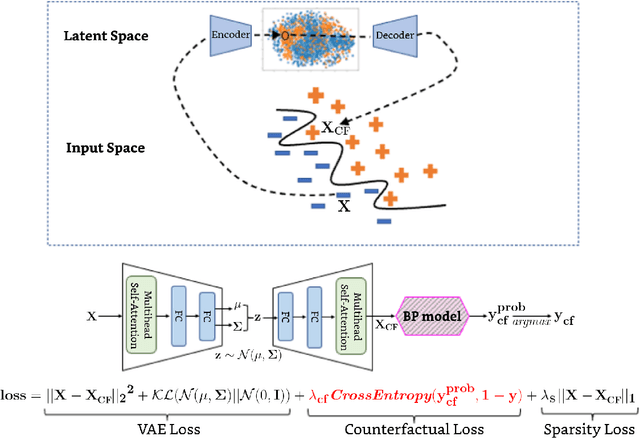

Machine learning models perform well on several healthcare tasks and can help reduce the burden on the healthcare system. However, the lack of explainability is a major roadblock to their adoption in hospitals. \textit{How can the decision of an ML model be explained to a physician?} The explanations considered in this paper are counterfactuals (CFs), hypothetical scenarios that would have resulted in the opposite outcome. Specifically, time-series CFs are investigated, inspired by the way physicians converse and reason out decisions `I would have given the patient a vasopressor if their blood pressure was lower and falling'. Key properties of CFs that are particularly meaningful in clinical settings are outlined: physiological plausibility, relevance to the task and sparse perturbations. Past work on CF generation does not satisfy these properties, specifically plausibility in that realistic time-series CFs are not generated. A variational autoencoder (VAE)-based approach is proposed that captures these desired properties. The method produces CFs that improve on prior approaches quantitatively (more plausible CFs as evaluated by their likelihood w.r.t original data distribution, and 100$\times$ faster at generating CFs) and qualitatively (2$\times$ more plausible and relevant) as evaluated by three physicians.
PulseImpute: A Novel Benchmark Task for Pulsative Physiological Signal Imputation
Dec 14, 2022The promise of Mobile Health (mHealth) is the ability to use wearable sensors to monitor participant physiology at high frequencies during daily life to enable temporally-precise health interventions. However, a major challenge is frequent missing data. Despite a rich imputation literature, existing techniques are ineffective for the pulsative signals which comprise many mHealth applications, and a lack of available datasets has stymied progress. We address this gap with PulseImpute, the first large-scale pulsative signal imputation challenge which includes realistic mHealth missingness models, an extensive set of baselines, and clinically-relevant downstream tasks. Our baseline models include a novel transformer-based architecture designed to exploit the structure of pulsative signals. We hope that PulseImpute will enable the ML community to tackle this significant and challenging task.
Kernel Deformed Exponential Families for Sparse Continuous Attention
Nov 12, 2021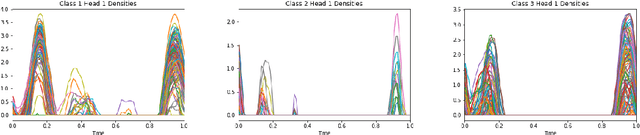
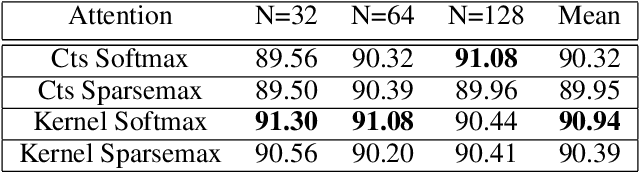
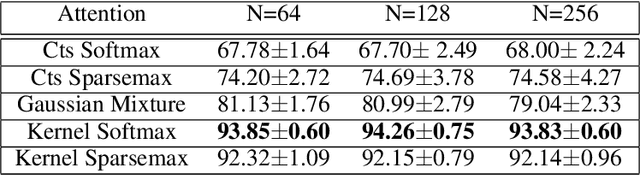
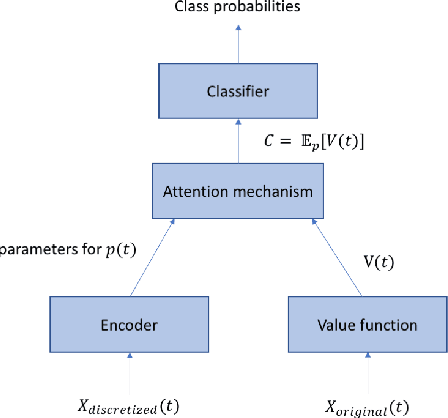
Attention mechanisms take an expectation of a data representation with respect to probability weights. This creates summary statistics that focus on important features. Recently, (Martins et al. 2020, 2021) proposed continuous attention mechanisms, focusing on unimodal attention densities from the exponential and deformed exponential families: the latter has sparse support. (Farinhas et al. 2021) extended this to use Gaussian mixture attention densities, which are a flexible class with dense support. In this paper, we extend this to two general flexible classes: kernel exponential families and our new sparse counterpart kernel deformed exponential families. Theoretically, we show new existence results for both kernel exponential and deformed exponential families, and that the deformed case has similar approximation capabilities to kernel exponential families. Experiments show that kernel deformed exponential families can attend to multiple compact regions of the data domain.
Transformers for prompt-level EMA non-response prediction
Nov 01, 2021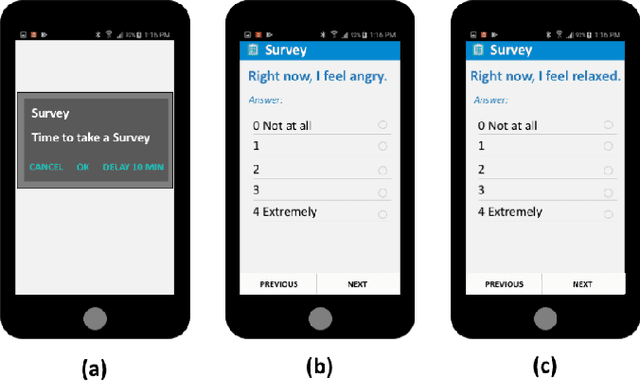
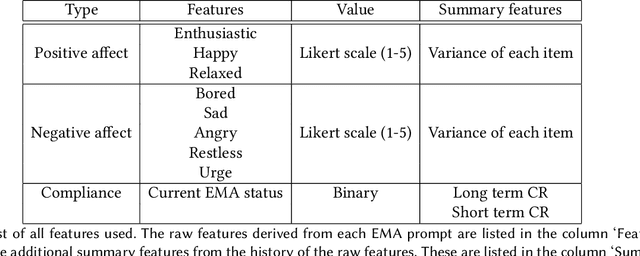
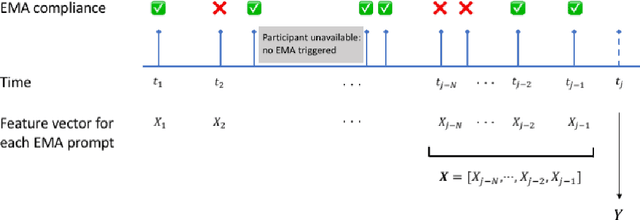

Ecological Momentary Assessments (EMAs) are an important psychological data source for measuring current cognitive states, affect, behavior, and environmental factors from participants in mobile health (mHealth) studies and treatment programs. Non-response, in which participants fail to respond to EMA prompts, is an endemic problem. The ability to accurately predict non-response could be utilized to improve EMA delivery and develop compliance interventions. Prior work has explored classical machine learning models for predicting non-response. However, as increasingly large EMA datasets become available, there is the potential to leverage deep learning models that have been effective in other fields. Recently, transformer models have shown state-of-the-art performance in NLP and other domains. This work is the first to explore the use of transformers for EMA data analysis. We address three key questions in applying transformers to EMA data: 1. Input representation, 2. encoding temporal information, 3. utility of pre-training on improving downstream prediction task performance. The transformer model achieves a non-response prediction AUC of 0.77 and is significantly better than classical ML and LSTM-based deep learning models. We will make our a predictive model trained on a corpus of 40K EMA samples freely-available to the research community, in order to facilitate the development of future transformer-based EMA analysis works.