 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining a machine learning decision to physicians via counterfactuals
Paper and Code
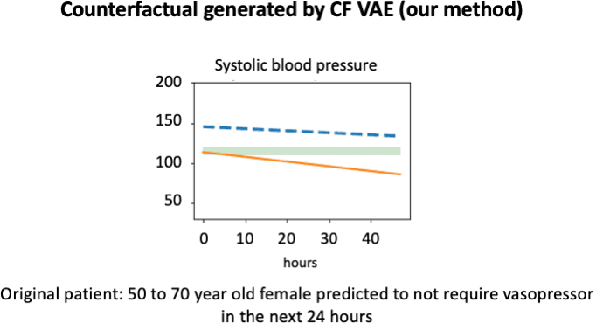
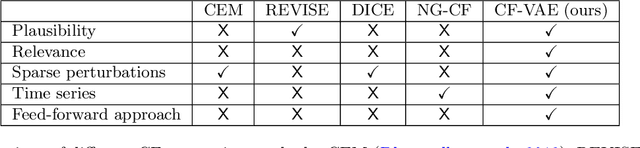
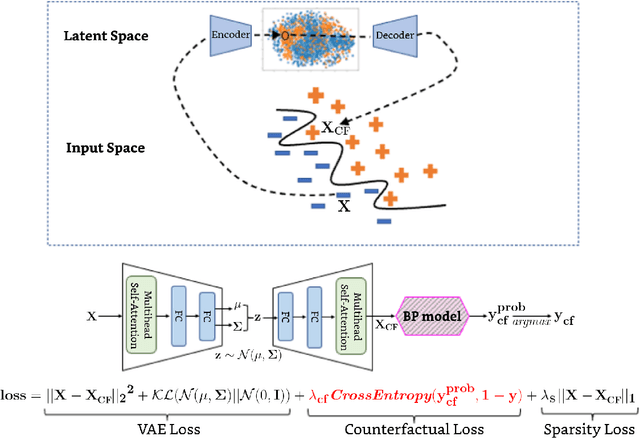

Machine learning models perform well on several healthcare tasks and can help reduce the burden on the healthcare system. However, the lack of explainability is a major roadblock to their adoption in hospitals. \textit{How can the decision of an ML model be explained to a physician?} The explanations considered in this paper are counterfactuals (CFs), hypothetical scenarios that would have resulted in the opposite outcome. Specifically, time-series CFs are investigated, inspired by the way physicians converse and reason out decisions `I would have given the patient a vasopressor if their blood pressure was lower and falling'. Key properties of CFs that are particularly meaningful in clinical settings are outlined: physiological plausibility, relevance to the task and sparse perturbations. Past work on CF generation does not satisfy these properties, specifically plausibility in that realistic time-series CFs are not generated. A variational autoencoder (VAE)-based approach is proposed that captures these desired properties. The method produces CFs that improve on prior approaches quantitatively (more plausible CFs as evaluated by their likelihood w.r.t original data distribution, and 100$\times$ faster at generating CFs) and qualitatively (2$\times$ more plausible and relevant) as evaluated by three physicians.