 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Nearest Neighbors with Dynamic Updates via Random Walks
Dec 19, 2025Approximate nearest neighbor search (ANN) is a common way to retrieve relevant search results, especially now in the context of large language models and retrieval augmented generation. One of the most widely used algorithms for ANN is based on constructing a multi-layer graph over the dataset, called the Hierarchical Navigable Small World (HNSW). While this algorithm supports insertion of new data, it does not support deletion of existing data. Moreover, deletion algorithms described by prior work come at the cost of increased query latency, decreased recall, or prolonged deletion time. In this paper, we propose a new theoretical framework for graph-based ANN based on random walks. We then utilize this framework to analyze a randomized deletion approach that preserves hitting time statistics compared to the graph before deleting the point. We then turn this theoretical framework into a deterministic deletion algorithm, and show that it provides better tradeoff between query latency, recall, deletion time, and memory usage through an extensive collection of experiments.
Private Text Generation by Seeding Large Language Model Prompts
Feb 18, 2025



We explore how private synthetic text can be generated by suitably prompting a large language model (LLM). This addresses a challenge for organizations like hospitals, which hold sensitive text data like patient medical records, and wish to share it in order to train machine learning models for medical tasks, while preserving patient privacy. Methods that rely on training or finetuning a model may be out of reach, either due to API limits of third-party LLMs, or due to ethical and legal prohibitions on sharing the private data with the LLM itself. We propose Differentially Private Keyphrase Prompt Seeding (DP-KPS), a method that generates a private synthetic text corpus from a sensitive input corpus, by accessing an LLM only through privatized prompts. It is based on seeding the prompts with private samples from a distribution over phrase embeddings, thus capturing the input corpus while achieving requisite output diversity and maintaining differential privacy. We evaluate DP-KPS on downstream ML text classification tasks, and show that the corpora it generates preserve much of the predictive power of the original ones. Our findings offer hope that institutions can reap ML insights by privately sharing data with simple prompts and little compute.
Fast Private Kernel Density Estimation via Locality Sensitive Quantization
Jul 04, 2023



We study efficient mechanisms for differentially private kernel density estimation (DP-KDE). Prior work for the Gaussian kernel described algorithms that run in time exponential in the number of dimensions $d$. This paper breaks the exponential barrier, and shows how the KDE can privately be approximated in time linear in $d$, making it feasible for high-dimensional data. We also present improved bounds for low-dimensional data. Our results are obtained through a general framework, which we term Locality Sensitive Quantization (LSQ), for constructing private KDE mechanisms where existing KDE approximation techniques can be applied. It lets us leverage several efficient non-private KDE methods -- like Random Fourier Features, the Fast Gauss Transform, and Locality Sensitive Hashing -- and ``privatize'' them in a black-box manner. Our experiments demonstrate that our resulting DP-KDE mechanisms are fast and accurate on large datasets in both high and low dimensions.
Explaining a machine learning decision to physicians via counterfactuals
Jun 10, 2023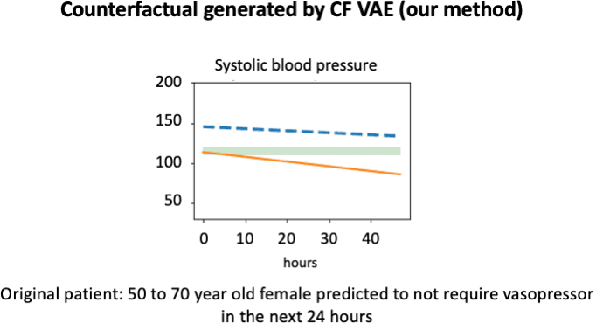
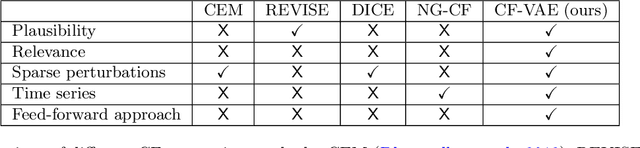
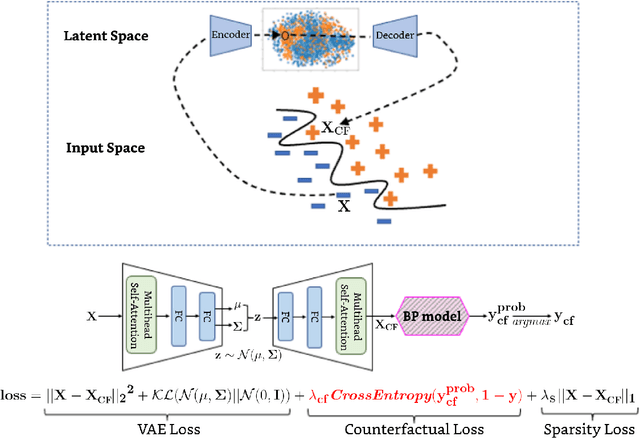

Machine learning models perform well on several healthcare tasks and can help reduce the burden on the healthcare system. However, the lack of explainability is a major roadblock to their adoption in hospitals. \textit{How can the decision of an ML model be explained to a physician?} The explanations considered in this paper are counterfactuals (CFs), hypothetical scenarios that would have resulted in the opposite outcome. Specifically, time-series CFs are investigated, inspired by the way physicians converse and reason out decisions `I would have given the patient a vasopressor if their blood pressure was lower and falling'. Key properties of CFs that are particularly meaningful in clinical settings are outlined: physiological plausibility, relevance to the task and sparse perturbations. Past work on CF generation does not satisfy these properties, specifically plausibility in that realistic time-series CFs are not generated. A variational autoencoder (VAE)-based approach is proposed that captures these desired properties. The method produces CFs that improve on prior approaches quantitatively (more plausible CFs as evaluated by their likelihood w.r.t original data distribution, and 100$\times$ faster at generating CFs) and qualitatively (2$\times$ more plausible and relevant) as evaluated by three physicians.
Predicting Preference Flips in Commerce Search
Jun 27, 2012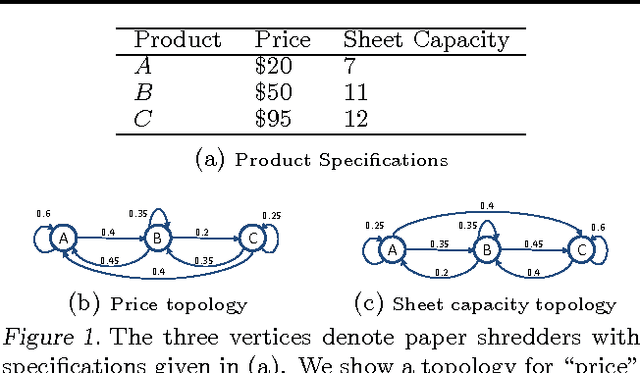

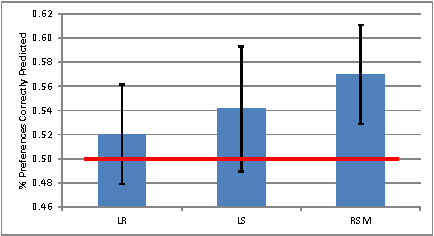
Traditional approaches to ranking in web search follow the paradigm of rank-by-score: a learned function gives each query-URL combination an absolute score and URLs are ranked according to this score. This paradigm ensures that if the score of one URL is better than another then one will always be ranked higher than the other. Scoring contradicts prior work in behavioral economics that showed that users' preferences between two items depend not only on the items but also on the presented alternatives. Thus, for the same query, users' preference between items A and B depends on the presence/absence of item C. We propose a new model of ranking, the Random Shopper Model, that allows and explains such behavior. In this model, each feature is viewed as a Markov chain over the items to be ranked, and the goal is to find a weighting of the features that best reflects their importance. We show that our model can be learned under the empirical risk minimization framework, and give an efficient learning algorithm. Experiments on commerce search logs demonstrate that our algorithm outperforms scoring-based approaches including regression and listwise ranking.
Adapting to the Shifting Intent of Search Queries
Jul 22, 2010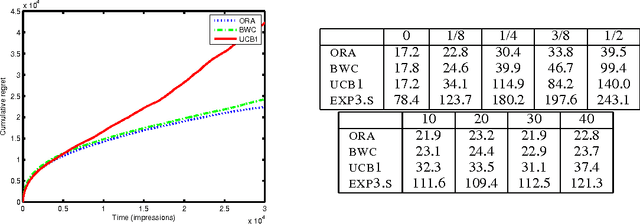
Search engines today present results that are often oblivious to abrupt shifts in intent. For example, the query `independence day' usually refers to a US holiday, but the intent of this query abruptly changed during the release of a major film by that name. While no studies exactly quantify the magnitude of intent-shifting traffic, studies suggest that news events, seasonal topics, pop culture, etc account for 50% of all search queries. This paper shows that the signals a search engine receives can be used to both determine that a shift in intent has happened, as well as find a result that is now more relevant. We present a meta-algorithm that marries a classifier with a bandit algorithm to achieve regret that depends logarithmically on the number of query impressions, under certain assumptions. We provide strong evidence that this regret is close to the best achievable. Finally, via a series of experiments, we demonstrate that our algorithm outperforms prior approaches, particularly as the amount of intent-shifting traffic increases.