 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynAgent: Generalizable Cooperative Humanoid Manipulation via Solo-to-Cooperative Agent Synergy
Apr 20, 2026Controllable cooperative humanoid manipulation is a fundamental yet challenging problem for embodied intelligence, due to severe data scarcity, complexities in multi-agent coordination, and limited generalization across objects. In this paper, we present SynAgent, a unified framework that enables scalable and physically plausible cooperative manipulation by leveraging Solo-to-Cooperative Agent Synergy to transfer skills from single-agent human-object interaction to multi-agent human-object-human scenarios. To maintain semantic integrity during motion transfer, we introduce an interaction-preserving retargeting method based on an Interact Mesh constructed via Delaunay tetrahedralization, which faithfully maintains spatial relationships among humans and objects. Building upon this refined data, we propose a single-agent pretraining and adaptation paradigm that bootstraps synergistic collaborative behaviors from abundant single-human data through decentralized training and multi-agent PPO. Finally, we develop a trajectory-conditioned generative policy using a conditional VAE, trained via multi-teacher distillation from motion imitation priors to achieve stable and controllable object-level trajectory execution. Extensive experiments demonstrate that SynAgent significantly outperforms existing baselines in both cooperative imitation and trajectory-conditioned control, while generalizing across diverse object geometries. Codes and data will be available after publication. Project Page: http://yw0208.github.io/synagent
PhysiInter: Integrating Physical Mapping for High-Fidelity Human Interaction Generation
Jun 09, 2025Driven by advancements in motion capture and generative artificial intelligence, leveraging large-scale MoCap datasets to train generative models for synthesizing diverse, realistic human motions has become a promising research direction. However, existing motion-capture techniques and generative models often neglect physical constraints, leading to artifacts such as interpenetration, sliding, and floating. These issues are exacerbated in multi-person motion generation, where complex interactions are involved. To address these limitations, we introduce physical mapping, integrated throughout the human interaction generation pipeline. Specifically, motion imitation within a physics-based simulation environment is used to project target motions into a physically valid space. The resulting motions are adjusted to adhere to real-world physics constraints while retaining their original semantic meaning. This mapping not only improves MoCap data quality but also directly informs post-processing of generated motions. Given the unique interactivity of multi-person scenarios, we propose a tailored motion representation framework. Motion Consistency (MC) and Marker-based Interaction (MI) loss functions are introduced to improve model performance. Experiments show our method achieves impressive results in generated human motion quality, with a 3%-89% improvement in physical fidelity. Project page http://yw0208.github.io/physiinter
ReCoM: Realistic Co-Speech Motion Generation with Recurrent Embedded Transformer
Mar 27, 2025We present ReCoM, an efficient framework for generating high-fidelity and generalizable human body motions synchronized with speech. The core innovation lies in the Recurrent Embedded Transformer (RET), which integrates Dynamic Embedding Regularization (DER) into a Vision Transformer (ViT) core architecture to explicitly model co-speech motion dynamics. This architecture enables joint spatial-temporal dependency modeling, thereby enhancing gesture naturalness and fidelity through coherent motion synthesis. To enhance model robustness, we incorporate the proposed DER strategy, which equips the model with dual capabilities of noise resistance and cross-domain generalization, thereby improving the naturalness and fluency of zero-shot motion generation for unseen speech inputs. To mitigate inherent limitations of autoregressive inference, including error accumulation and limited self-correction, we propose an iterative reconstruction inference (IRI) strategy. IRI refines motion sequences via cyclic pose reconstruction, driven by two key components: (1) classifier-free guidance improves distribution alignment between generated and real gestures without auxiliary supervision, and (2) a temporal smoothing process eliminates abrupt inter-frame transitions while ensuring kinematic continuity. Extensive experiments on benchmark datasets validate ReCoM's effectiveness, achieving state-of-the-art performance across metrics. Notably, it reduces the Fr\'echet Gesture Distance (FGD) from 18.70 to 2.48, demonstrating an 86.7% improvement in motion realism. Our project page is https://yong-xie-xy.github.io/ReCoM/.
STAF: 3D Human Mesh Recovery from Video with Spatio-Temporal Alignment Fusion
Jan 03, 2024



The recovery of 3D human mesh from monocular images has significantly been developed in recent years. However, existing models usually ignore spatial and temporal information, which might lead to mesh and image misalignment and temporal discontinuity. For this reason, we propose a novel Spatio-Temporal Alignment Fusion (STAF) model. As a video-based model, it leverages coherence clues from human motion by an attention-based Temporal Coherence Fusion Module (TCFM). As for spatial mesh-alignment evidence, we extract fine-grained local information through predicted mesh projection on the feature maps. Based on the spatial features, we further introduce a multi-stage adjacent Spatial Alignment Fusion Module (SAFM) to enhance the feature representation of the target frame. In addition to the above, we propose an Average Pooling Module (APM) to allow the model to focus on the entire input sequence rather than just the target frame. This method can remarkably improve the smoothness of recovery results from video. Extensive experiments on 3DPW, MPII3D, and H36M demonstrate the superiority of STAF. We achieve a state-of-the-art trade-off between precision and smoothness. Our code and more video results are on the project page https://yw0208.github.io/staf/
Generating Fine-Grained Human Motions Using ChatGPT-Refined Descriptions
Dec 05, 2023



Recently, significant progress has been made in text-based motion generation, enabling the generation of diverse and high-quality human motions that conform to textual descriptions. However, it remains challenging to generate fine-grained or stylized motions due to the lack of datasets annotated with detailed textual descriptions. By adopting a divide-and-conquer strategy, we propose a new framework named Fine-Grained Human Motion Diffusion Model (FG-MDM) for human motion generation. Specifically, we first parse previous vague textual annotation into fine-grained description of different body parts by leveraging a large language model (GPT-3.5). We then use these fine-grained descriptions to guide a transformer-based diffusion model. FG-MDM can generate fine-grained and stylized motions even outside of the distribution of the training data. Our experimental results demonstrate the superiority of FG-MDM over previous methods, especially the strong generalization capability. We will release our fine-grained textual annotations for HumanML3D and KIT.
W-HMR: Human Mesh Recovery in World Space with Weak-supervised Camera Calibration and Orientation Correction
Nov 30, 2023



For a long time, in the field of reconstructing 3D human bodies from monocular images, most methods opted to simplify the task by minimizing the influence of the camera. Using a coarse focal length setting results in the reconstructed bodies not aligning well with distorted images. Ignoring camera rotation leads to an unrealistic reconstructed body pose in world space. Consequently, existing methods' application scenarios are confined to controlled environments. And they struggle to achieve accurate and reasonable reconstruction in world space when confronted with complex and diverse in-the-wild images. To address the above issues, we propose W-HMR, which decouples global body recovery into camera calibration, local body recovery and global body orientation correction. We design the first weak-supervised camera calibration method for body distortion, eliminating dependence on focal length labels and achieving finer mesh-image alignment. We propose a novel orientation correction module to allow the reconstructed human body to remain normal in world space. Decoupling body orientation and body pose enables our model to consider the accuracy in camera coordinate and the reasonableness in world coordinate simultaneously, expanding the range of applications. As a result, W-HMR achieves high-quality reconstruction in dual coordinate systems, particularly in challenging scenes. Codes will be released on https://yw0208.github.io/w-hmr/ after publication.
Boosting Few-shot Fine-grained Recognition with Background Suppression and Foreground Alignment
Oct 04, 2022

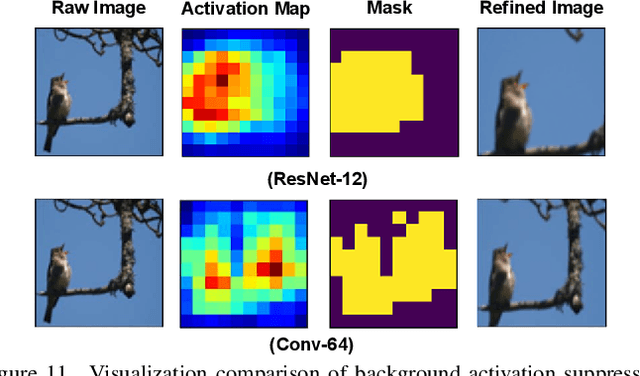

Few-shot fine-grained recognition (FS-FGR) aims to recognize novel fine-grained categories with the help of limited available samples. Undoubtedly, this task inherits the main challenges from both few-shot learning and fine-grained recognition. First, the lack of labeled samples makes the learned model easy to overfit. Second, it also suffers from high intra-class variance and low inter-class difference in the datasets. To address this challenging task, we propose a two-stage background suppression and foreground alignment framework, which is composed of a background activation suppression (BAS) module, a foreground object alignment (FOA) module, and a local to local (L2L) similarity metric. Specifically, the BAS is introduced to generate a foreground mask for localization to weaken background disturbance and enhance dominative foreground objects. What's more, considering the lack of labeled samples, we compute the pairwise similarity of feature maps using both the raw image and the refined image. The FOA then reconstructs the feature map of each support sample according to its correction to the query ones, which addresses the problem of misalignment between support-query image pairs. To enable the proposed method to have the ability to capture subtle differences in confused samples, we present a novel L2L similarity metric to further measure the local similarity between a pair of aligned spatial features in the embedding space. Extensive experiments conducted on multiple popular fine-grained benchmarks demonstrate that our method outperforms the existing state-of-the-art by a large margin.