 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassification in Japanese Sign Language Based on Dynamic Facial Expressions
Nov 10, 2024

Sign language is a visual language expressed through hand movements and non-manual markers. Non-manual markers include facial expressions and head movements. These expressions vary across different nations. Therefore, specialized analysis methods for each sign language are necessary. However, research on Japanese Sign Language (JSL) recognition is limited due to a lack of datasets. The development of recognition models that consider both manual and non-manual features of JSL is crucial for precise and smooth communication with deaf individuals. In JSL, sentence types such as affirmative statements and questions are distinguished by facial expressions. In this paper, we propose a JSL recognition method that focuses on facial expressions. Our proposed method utilizes a neural network to analyze facial features and classify sentence types. Through the experiments, we confirm our method's effectiveness by achieving a classification accuracy of 96.05%.
Neural Video Representation for Redundancy Reduction and Consistency Preservation
Sep 27, 2024



Implicit neural representations (INRs) embed various signals into networks. They have gained attention in recent years because of their versatility in handling diverse signal types. For videos, INRs achieve video compression by embedding video signals into networks and compressing them. Conventional methods use an index that expresses the time of the frame or the features extracted from the frame as inputs to the network. The latter method provides greater expressive capability as the input is specific to each video. However, the features extracted from frames often contain redundancy, which contradicts the purpose of video compression. Moreover, since frame time information is not explicitly provided to the network, learning the relationships between frames is challenging. To address these issues, we aim to reduce feature redundancy by extracting features based on the high-frequency components of the frames. In addition, we use feature differences between adjacent frames in order for the network to learn frame relationships smoothly. We propose a video representation method that uses the high-frequency components of frames and the differences in features between adjacent frames. The experimental results show that our method outperforms the existing HNeRV method in 90 percent of the videos.
Improving Image Coding for Machines through Optimizing Encoder via Auxiliary Loss
Feb 13, 2024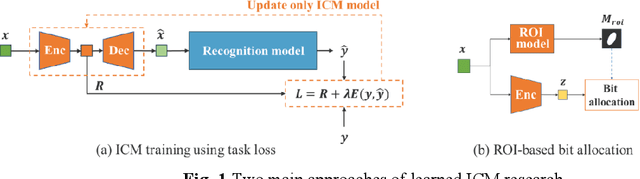

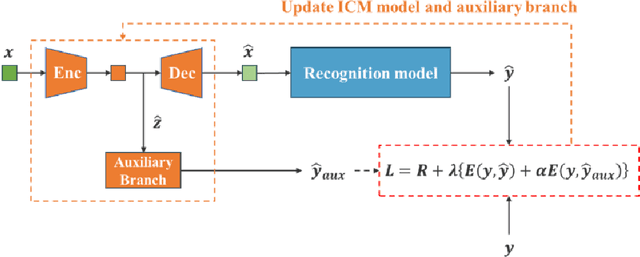
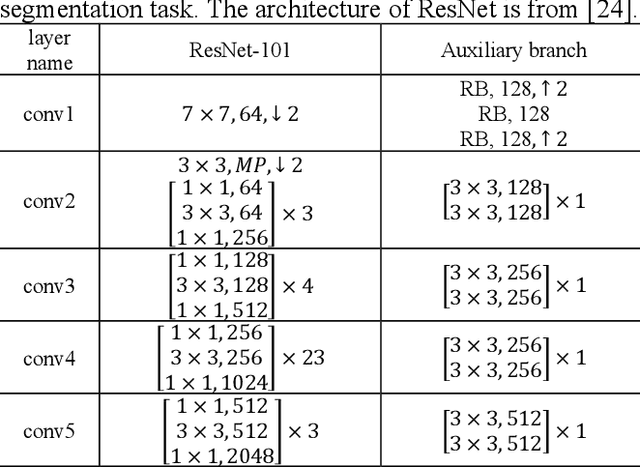
Image coding for machines (ICM) aims to compress images for machine analysis using recognition models rather than human vision. Hence, in ICM, it is important for the encoder to recognize and compress the information necessary for the machine recognition task. There are two main approaches in learned ICM; optimization of the compression model based on task loss, and Region of Interest (ROI) based bit allocation. These approaches provide the encoder with the recognition capability. However, optimization with task loss becomes difficult when the recognition model is deep, and ROI-based methods often involve extra overhead during evaluation. In this study, we propose a novel training method for learned ICM models that applies auxiliary loss to the encoder to improve its recognition capability and rate-distortion performance. Our method achieves Bjontegaard Delta rate improvements of 27.7% and 20.3% in object detection and semantic segmentation tasks, compared to the conventional training method.