 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Single-Channel Audio Separation with Diffusion Source Priors
Dec 23, 2025Single-channel audio separation aims to separate individual sources from a single-channel mixture. Most existing methods rely on supervised learning with synthetically generated paired data. However, obtaining high-quality paired data in real-world scenarios is often difficult. This data scarcity can degrade model performance under unseen conditions and limit generalization ability. To this end, in this work, we approach this problem from an unsupervised perspective, framing it as a probabilistic inverse problem. Our method requires only diffusion priors trained on individual sources. Separation is then achieved by iteratively guiding an initial state toward the solution through reconstruction guidance. Importantly, we introduce an advanced inverse problem solver specifically designed for separation, which mitigates gradient conflicts caused by interference between the diffusion prior and reconstruction guidance during inverse denoising. This design ensures high-quality and balanced separation performance across individual sources. Additionally, we find that initializing the denoising process with an augmented mixture instead of pure Gaussian noise provides an informative starting point that significantly improves the final performance. To further enhance audio prior modeling, we design a novel time-frequency attention-based network architecture that demonstrates strong audio modeling capability. Collectively, these improvements lead to significant performance gains, as validated across speech-sound event, sound event, and speech separation tasks.
Improvement in Sign Language Translation Using Text CTC Alignment
Dec 12, 2024
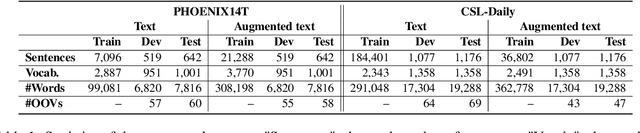
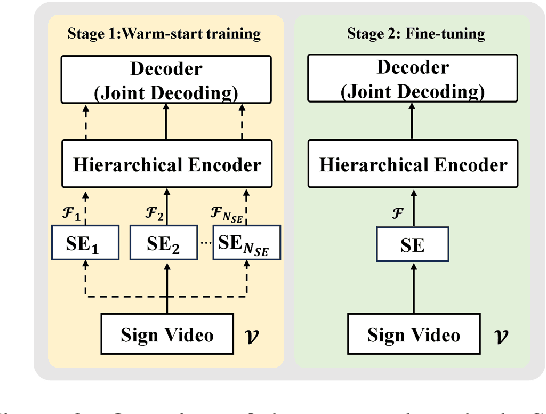
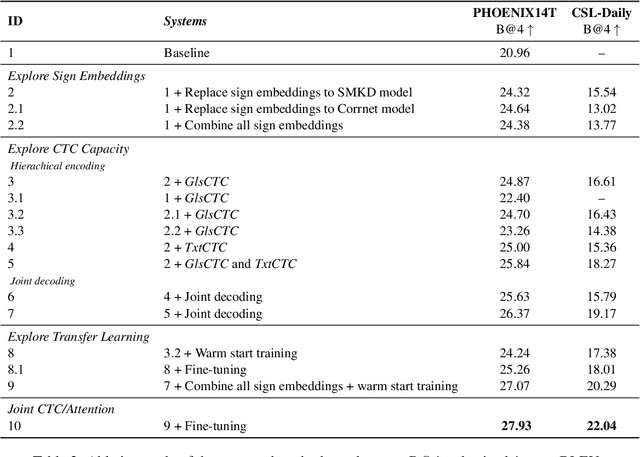
Current sign language translation (SLT) approaches often rely on gloss-based supervision with Connectionist Temporal Classification (CTC), limiting their ability to handle non-monotonic alignments between sign language video and spoken text. In this work, we propose a novel method combining joint CTC/Attention and transfer learning. The joint CTC/Attention introduces hierarchical encoding and integrates CTC with the attention mechanism during decoding, effectively managing both monotonic and non-monotonic alignments. Meanwhile, transfer learning helps bridge the modality gap between vision and language in SLT. Experimental results on two widely adopted benchmarks, RWTH-PHOENIX-Weather 2014 T and CSL-Daily, show that our method achieves results comparable to state-of-the-art and outperforms the pure-attention baseline. Additionally, this work opens a new door for future research into gloss-free SLT using text-based CTC alignment.