 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speaker Diarization for an Unknown Number of Speakers with Encoder-Decoder Based Attractors
Paper and Code

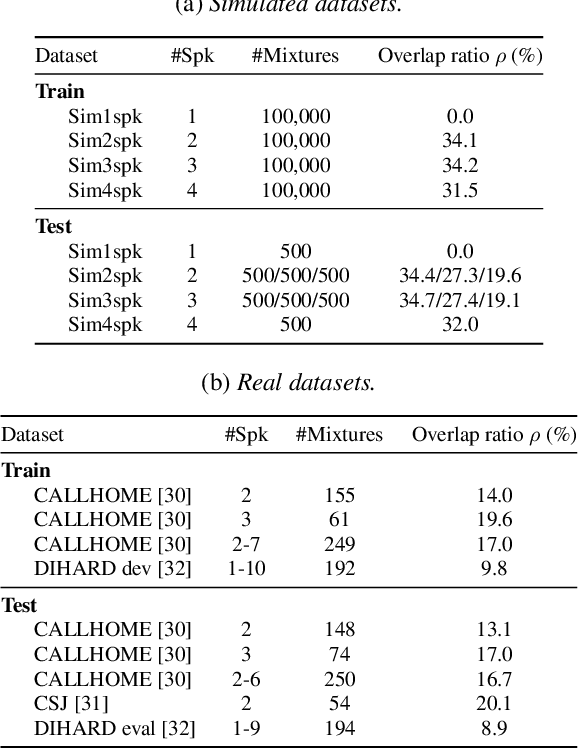
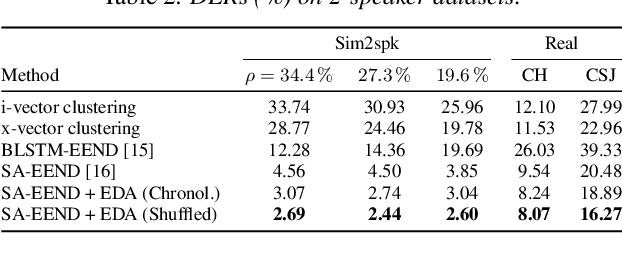

End-to-end speaker diarization for an unknown number of speakers is addressed in this paper. Recently proposed end-to-end speaker diarization outperformed conventional clustering-based speaker diarization, but it has one drawback: it is less flexible in terms of the number of speakers. This paper proposes a method for encoder-decoder based attractor calculation (EDA), which first generates a flexible number of attractors from a speech embedding sequence. Then, the generated multiple attractors are multiplied by the speech embedding sequence to produce the same number of speaker activities. The speech embedding sequence is extracted using the conventional self-attentive end-to-end neural speaker diarization (SA-EEND) network. In a two-speaker condition, our method achieved a 2.69 % diarization error rate (DER) on simulated mixtures and a 8.07 % DER on the two-speaker subset of CALLHOME, while vanilla SA-EEND attained 4.56 % and 9.54 %, respectively. In unknown numbers of speakers conditions, our method attained a 15.29 % DER on CALLHOME, while the x-vector-based clustering method achieved a 19.43 % DER.