 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam Hitachi at SemEval-2023 Task 3: Exploring Cross-lingual Multi-task Strategies for Genre and Framing Detection in Online News
Mar 03, 2023This paper explains the participation of team Hitachi to SemEval-2023 Task 3 "Detecting the genre, the framing, and the persuasion techniques in online news in a multi-lingual setup." Based on the multilingual, multi-task nature of the task and the setting that training data is limited, we investigated different strategies for training the pretrained language models under low resource settings. Through extensive experiments, we found that (a) cross-lingual/multi-task training, and (b) collecting an external balanced dataset, can benefit the genre and framing detection. We constructed ensemble models from the results and achieved the highest macro-averaged F1 scores in Italian and Russian genre categorization subtasks.
Team Hitachi @ AutoMin 2021: Reference-free Automatic Minuting Pipeline with Argument Structure Construction over Topic-based Summarization
Dec 06, 2021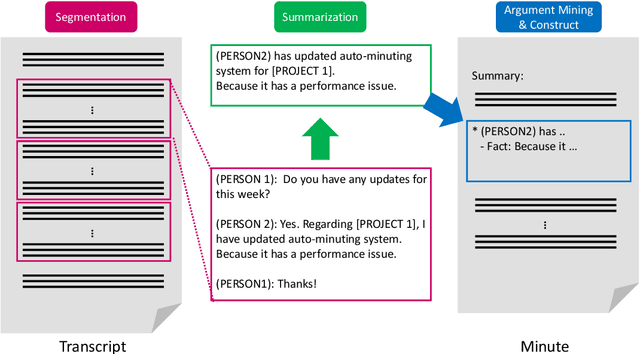


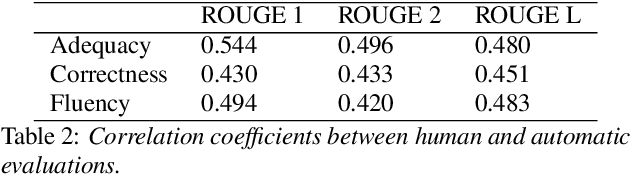
This paper introduces the proposed automatic minuting system of the Hitachi team for the First Shared Task on Automatic Minuting (AutoMin-2021). We utilize a reference-free approach (i.e., without using training minutes) for automatic minuting (Task A), which first splits a transcript into blocks on the basis of topics and subsequently summarizes those blocks with a pre-trained BART model fine-tuned on a summarization corpus of chat dialogue. In addition, we apply a technique of argument mining to the generated minutes, reorganizing them in a well-structured and coherent way. We utilize multiple relevance scores to determine whether or not a minute is derived from the same meeting when either a transcript or another minute is given (Task B and C). On top of those scores, we train a conventional machine learning model to bind them and to make final decisions. Consequently, our approach for Task A achieve the best adequacy score among all submissions and close performance to the best system in terms of grammatical correctness and fluency. For Task B and C, the proposed model successfully outperformed a majority vote baseline.