 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Micro Domain-Adaptive Pre-Training Effective for Real-World Operations? Multi-Step Evaluation Reveals Potential and Bottlenecks
Feb 04, 2026When applying LLMs to real-world enterprise operations, LLMs need to handle proprietary knowledge in small domains of specific operations ($\textbf{micro domains}$). A previous study shows micro domain-adaptive pre-training ($\textbf{mDAPT}$) with fewer documents is effective, similarly to DAPT in larger domains. However, it evaluates mDAPT only on multiple-choice questions; thus, its effectiveness for generative tasks in real-world operations remains unknown. We aim to reveal the potential and bottlenecks of mDAPT for generative tasks. To this end, we disentangle the answering process into three subtasks and evaluate the performance of each subtask: (1) $\textbf{eliciting}$ facts relevant to questions from an LLM's own knowledge, (2) $\textbf{reasoning}$ over the facts to obtain conclusions, and (3) $\textbf{composing}$ long-form answers based on the conclusions. We verified mDAPT on proprietary IT product knowledge for real-world questions in IT technical support operations. As a result, mDAPT resolved the elicitation task that the base model struggled with but did not resolve other subtasks. This clarifies mDAPT's effectiveness in the knowledge aspect and its bottlenecks in other aspects. Further analysis empirically shows that resolving the elicitation and reasoning tasks ensures sufficient performance (over 90%), emphasizing the need to enhance reasoning capability.
Agent Fine-tuning through Distillation for Domain-specific LLMs in Microdomains
Oct 01, 2025Agentic large language models (LLMs) have become prominent for autonomously interacting with external environments and performing multi-step reasoning tasks. Most approaches leverage these capabilities via in-context learning with few-shot prompts, but this often results in lengthy inputs and higher computational costs. Agent fine-tuning offers an alternative by enabling LLMs to internalize procedural reasoning and domain-specific knowledge through training on relevant data and demonstration trajectories. While prior studies have focused on general domains, their effectiveness in specialized technical microdomains remains unclear. This paper explores agent fine-tuning for domain adaptation within Hitachi's JP1 middleware, a microdomain for specialized IT operations. We fine-tuned LLMs using JP1-specific datasets derived from domain manuals and distilled reasoning trajectories generated by LLMs themselves, enhancing decision making accuracy and search efficiency. During inference, we used an agentic prompt with retrieval-augmented generation and introduced a context-answer extractor to improve information relevance. On JP1 certification exam questions, our method achieved a 14% performance improvement over the base model, demonstrating the potential of agent fine-tuning for domain-specific reasoning in complex microdomains.
Can Visual Encoder Learn to See Arrows?
May 26, 2025
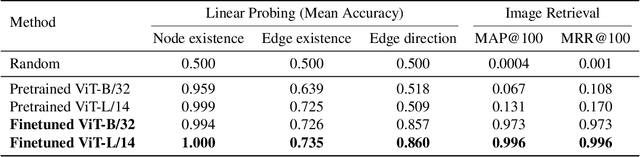


The diagram is a visual representation of a relationship illustrated with edges (lines or arrows), which is widely used in industrial and scientific communication. Although recognizing diagrams is essential for vision language models (VLMs) to comprehend domain-specific knowledge, recent studies reveal that many VLMs fail to identify edges in images. We hypothesize that these failures stem from an over-reliance on textual and positional biases, preventing VLMs from learning explicit edge features. Based on this idea, we empirically investigate whether the image encoder in VLMs can learn edge representation through training on a diagram dataset in which edges are biased neither by textual nor positional information. To this end, we conduct contrastive learning on an artificially generated diagram--caption dataset to train an image encoder and evaluate its diagram-related features on three tasks: probing, image retrieval, and captioning. Our results show that the finetuned model outperforms pretrained CLIP in all tasks and surpasses zero-shot GPT-4o and LLaVA-Mistral in the captioning task. These findings confirm that eliminating textual and positional biases fosters accurate edge recognition in VLMs, offering a promising path for advancing diagram understanding.
Acquiring Bidirectionality via Large and Small Language Models
Aug 19, 2024
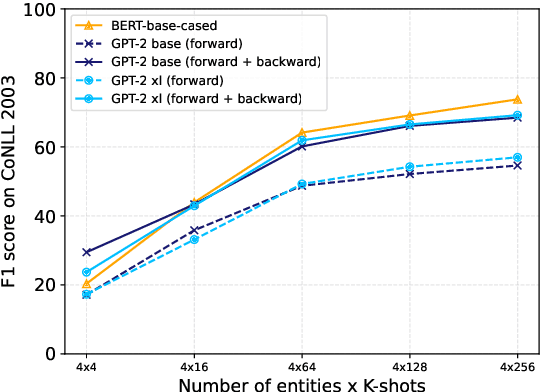


Using token representation from bidirectional language models (LMs) such as BERT is still a widely used approach for token-classification tasks. Even though there exist much larger unidirectional LMs such as Llama-2, they are rarely used to replace the token representation of bidirectional LMs. In this work, we hypothesize that their lack of bidirectionality is keeping them behind. To that end, we propose to newly train a small backward LM and concatenate its representations to those of existing LM for downstream tasks. Through experiments in named entity recognition, we demonstrate that introducing backward model improves the benchmark performance more than 10 points. Furthermore, we show that the proposed method is especially effective for rare domains and in few-shot learning settings.
LARCH: Large Language Model-based Automatic Readme Creation with Heuristics
Aug 22, 2023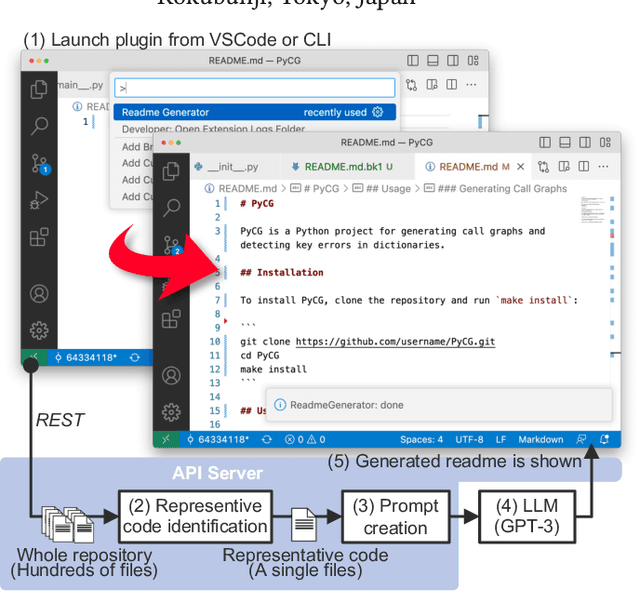
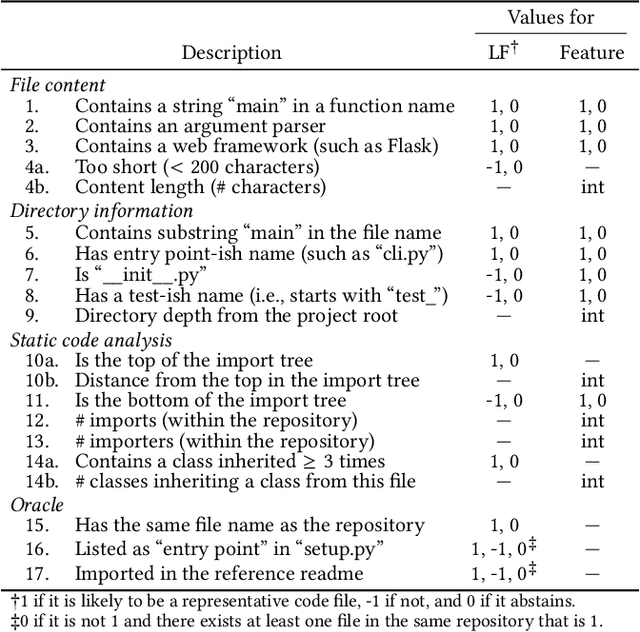
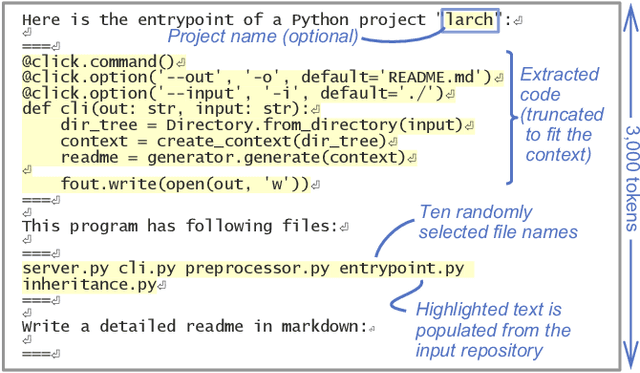

Writing a readme is a crucial aspect of software development as it plays a vital role in managing and reusing program code. Though it is a pain point for many developers, automatically creating one remains a challenge even with the recent advancements in large language models (LLMs), because it requires generating an abstract description from thousands of lines of code. In this demo paper, we show that LLMs are capable of generating a coherent and factually correct readmes if we can identify a code fragment that is representative of the repository. Building upon this finding, we developed LARCH (LLM-based Automatic Readme Creation with Heuristics) which leverages representative code identification with heuristics and weak supervision. Through human and automated evaluations, we illustrate that LARCH can generate coherent and factually correct readmes in the majority of cases, outperforming a baseline that does not rely on representative code identification. We have made LARCH open-source and provided a cross-platform Visual Studio Code interface and command-line interface, accessible at https://github.com/hitachi-nlp/larch. A demo video showcasing LARCH's capabilities is available at https://youtu.be/ZUKkh5ED-O4.
* This is a pre-print of a paper accepted at CIKM'23 Demo. Refer to the DOI URL for the original publication
Team Hitachi at SemEval-2023 Task 3: Exploring Cross-lingual Multi-task Strategies for Genre and Framing Detection in Online News
Mar 03, 2023This paper explains the participation of team Hitachi to SemEval-2023 Task 3 "Detecting the genre, the framing, and the persuasion techniques in online news in a multi-lingual setup." Based on the multilingual, multi-task nature of the task and the setting that training data is limited, we investigated different strategies for training the pretrained language models under low resource settings. Through extensive experiments, we found that (a) cross-lingual/multi-task training, and (b) collecting an external balanced dataset, can benefit the genre and framing detection. We constructed ensemble models from the results and achieved the highest macro-averaged F1 scores in Italian and Russian genre categorization subtasks.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
ContractNLI: A Dataset for Document-level Natural Language Inference for Contracts
Oct 05, 2021
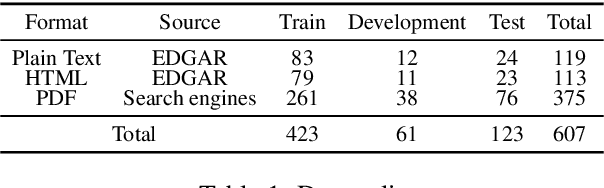


Reviewing contracts is a time-consuming procedure that incurs large expenses to companies and social inequality to those who cannot afford it. In this work, we propose "document-level natural language inference (NLI) for contracts", a novel, real-world application of NLI that addresses such problems. In this task, a system is given a set of hypotheses (such as "Some obligations of Agreement may survive termination.") and a contract, and it is asked to classify whether each hypothesis is "entailed by", "contradicting to" or "not mentioned by" (neutral to) the contract as well as identifying "evidence" for the decision as spans in the contract. We annotated and release the largest corpus to date consisting of 607 annotated contracts. We then show that existing models fail badly on our task and introduce a strong baseline, which (1) models evidence identification as multi-label classification over spans instead of trying to predict start and end tokens, and (2) employs more sophisticated context segmentation for dealing with long documents. We also show that linguistic characteristics of contracts, such as negations by exceptions, are contributing to the difficulty of this task and that there is much room for improvement.
Capturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser
May 01, 2021

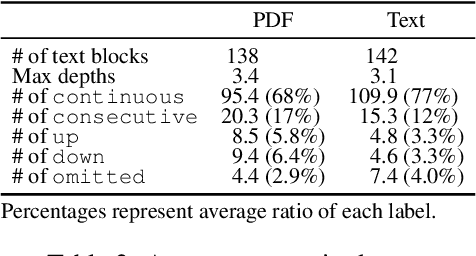

While many NLP papers, tasks and pipelines assume raw, clean texts, many texts we encounter in the wild are not so clean, with many of them being visually structured documents (VSDs) such as PDFs. Conventional preprocessing tools for VSDs mainly focused on word segmentation and coarse layout analysis, while fine-grained logical structure analysis (such as identifying paragraph boundaries and their hierarchies) of VSDs is underexplored. To that end, we proposed to formulate the task as prediction of transition labels between text fragments that maps the fragments to a tree, and developed a feature-based machine learning system that fuses visual, textual and semantic cues. Our system significantly outperformed baselines in identifying different structures in VSDs. For example, our system obtained a paragraph boundary detection F1 score of 0.951 which is significantly better than a popular PDF-to-text tool with a F1 score of 0.739.
Hitachi at SemEval-2020 Task 12: Offensive Language Identification with Noisy Labels using Statistical Sampling and Post-Processing
May 01, 2020
In this paper, we present our participation in SemEval-2020 Task-12 Subtask-A (English Language) which focuses on offensive language identification from noisy labels. To this end, we developed a hybrid system with the BERT classifier trained with tweets selected using Statistical Sampling Algorithm (SA) and Post-Processed (PP) using an offensive wordlist. Our developed system achieved 34 th position with Macro-averaged F1-score (Macro-F1) of 0.90913 over both offensive and non-offensive classes. We further show comprehensive results and error analysis to assist future research in offensive language identification with noisy labels.