 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser
Paper and Code


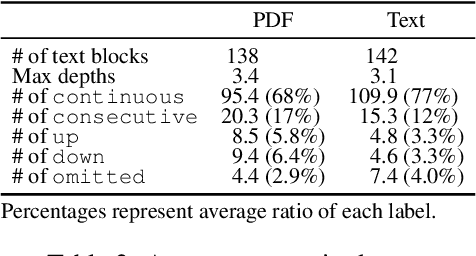

While many NLP papers, tasks and pipelines assume raw, clean texts, many texts we encounter in the wild are not so clean, with many of them being visually structured documents (VSDs) such as PDFs. Conventional preprocessing tools for VSDs mainly focused on word segmentation and coarse layout analysis, while fine-grained logical structure analysis (such as identifying paragraph boundaries and their hierarchies) of VSDs is underexplored. To that end, we proposed to formulate the task as prediction of transition labels between text fragments that maps the fragments to a tree, and developed a feature-based machine learning system that fuses visual, textual and semantic cues. Our system significantly outperformed baselines in identifying different structures in VSDs. For example, our system obtained a paragraph boundary detection F1 score of 0.951 which is significantly better than a popular PDF-to-text tool with a F1 score of 0.739.