 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquiring Bidirectionality via Large and Small Language Models
Paper and Code
Aug 19, 2024
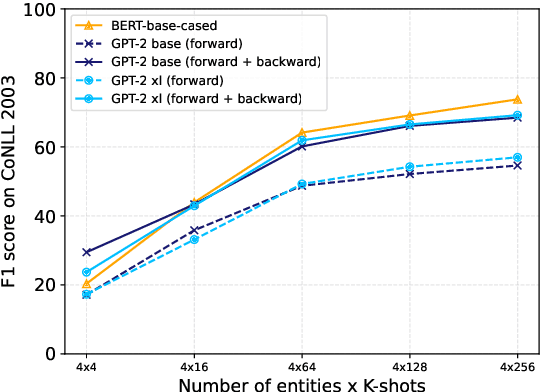


Using token representation from bidirectional language models (LMs) such as BERT is still a widely used approach for token-classification tasks. Even though there exist much larger unidirectional LMs such as Llama-2, they are rarely used to replace the token representation of bidirectional LMs. In this work, we hypothesize that their lack of bidirectionality is keeping them behind. To that end, we propose to newly train a small backward LM and concatenate its representations to those of existing LM for downstream tasks. Through experiments in named entity recognition, we demonstrate that introducing backward model improves the benchmark performance more than 10 points. Furthermore, we show that the proposed method is especially effective for rare domains and in few-shot learning settings.