 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammatical Error Correction Evaluation by Optimally Transporting Edit Representation
Feb 05, 2026Automatic evaluation in grammatical error correction (GEC) is crucial for selecting the best-performing systems. Currently, reference-based metrics are a popular choice, which basically measure the similarity between hypothesis and reference sentences. However, similarity measures based on embeddings, such as BERTScore, are often ineffective, since many words in the source sentences remain unchanged in both the hypothesis and the reference. This study focuses on edits specifically designed for GEC, i.e., ERRANT, and computes similarity measured over the edits from the source sentence. To this end, we propose edit vector, a representation for an edit, and introduce a new metric, UOT-ERRANT, which transports these edit vectors from hypothesis to reference using unbalanced optimal transport. Experiments with SEEDA meta-evaluation show that UOT-ERRANT improves evaluation performance, particularly in the +Fluency domain where many edits occur. Moreover, our method is highly interpretable because the transport plan can be interpreted as a soft edit alignment, making UOT-ERRANT a useful metric for both system ranking and analyzing GEC systems. Our code is available from https://github.com/gotutiyan/uot-errant.
gec-metrics: A Unified Library for Grammatical Error Correction Evaluation
May 26, 2025We introduce gec-metrics, a library for using and developing grammatical error correction (GEC) evaluation metrics through a unified interface. Our library enables fair system comparisons by ensuring that everyone conducts evaluations using a consistent implementation. Moreover, it is designed with a strong focus on API usage, making it highly extensible. It also includes meta-evaluation functionalities and provides analysis and visualization scripts, contributing to developing GEC evaluation metrics. Our code is released under the MIT license and is also distributed as an installable package. The video is available on YouTube.
Rethinking Evaluation Metrics for Grammatical Error Correction: Why Use a Different Evaluation Process than Human?
Feb 13, 2025


One of the goals of automatic evaluation metrics in grammatical error correction (GEC) is to rank GEC systems such that it matches human preferences. However, current automatic evaluations are based on procedures that diverge from human evaluation. Specifically, human evaluation derives rankings by aggregating sentence-level relative evaluation results, e.g., pairwise comparisons, using a rating algorithm, whereas automatic evaluation averages sentence-level absolute scores to obtain corpus-level scores, which are then sorted to determine rankings. In this study, we propose an aggregation method for existing automatic evaluation metrics which aligns with human evaluation methods to bridge this gap. We conducted experiments using various metrics, including edit-based metrics, $n$-gram based metrics, and sentence-level metrics, and show that resolving the gap improves results for the most of metrics on the SEEDA benchmark. We also found that even BERT-based metrics sometimes outperform the metrics of GPT-4. We publish our unified implementation of the metrics and meta-evaluations.
Improving Explainability of Sentence-level Metrics via Edit-level Attribution for Grammatical Error Correction
Dec 17, 2024Various evaluation metrics have been proposed for Grammatical Error Correction (GEC), but many, particularly reference-free metrics, lack explainability. This lack of explainability hinders researchers from analyzing the strengths and weaknesses of GEC models and limits the ability to provide detailed feedback for users. To address this issue, we propose attributing sentence-level scores to individual edits, providing insight into how specific corrections contribute to the overall performance. For the attribution method, we use Shapley values, from cooperative game theory, to compute the contribution of each edit. Experiments with existing sentence-level metrics demonstrate high consistency across different edit granularities and show approximately 70\% alignment with human evaluations. In addition, we analyze biases in the metrics based on the attribution results, revealing trends such as the tendency to ignore orthographic edits. Our implementation is available at \url{https://github.com/naist-nlp/gec-attribute}.
Acquiring Bidirectionality via Large and Small Language Models
Aug 19, 2024
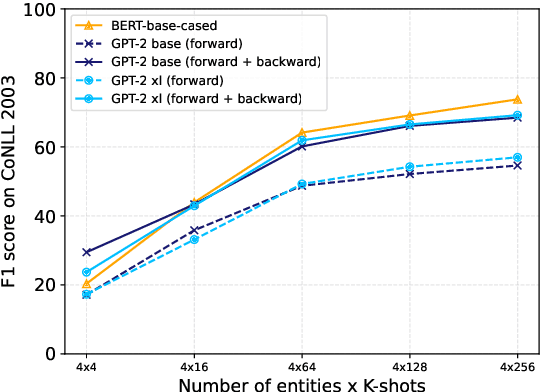


Using token representation from bidirectional language models (LMs) such as BERT is still a widely used approach for token-classification tasks. Even though there exist much larger unidirectional LMs such as Llama-2, they are rarely used to replace the token representation of bidirectional LMs. In this work, we hypothesize that their lack of bidirectionality is keeping them behind. To that end, we propose to newly train a small backward LM and concatenate its representations to those of existing LM for downstream tasks. Through experiments in named entity recognition, we demonstrate that introducing backward model improves the benchmark performance more than 10 points. Furthermore, we show that the proposed method is especially effective for rare domains and in few-shot learning settings.