 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Retrieval with Multi-Stage Re-Ranking Models
Nov 14, 2023The text retrieval is the task of retrieving similar documents to a search query, and it is important to improve retrieval accuracy while maintaining a certain level of retrieval speed. Existing studies have reported accuracy improvements using language models, but many of these do not take into account the reduction in search speed that comes with increased performance. In this study, we propose three-stage re-ranking model using model ensembles or larger language models to improve search accuracy while minimizing the search delay. We ranked the documents by BM25 and language models, and then re-ranks by a model ensemble or a larger language model for documents with high similarity to the query. In our experiments, we train the MiniLM language model on the MS-MARCO dataset and evaluate it in a zero-shot setting. Our proposed method achieves higher retrieval accuracy while reducing the retrieval speed decay.
LARCH: Large Language Model-based Automatic Readme Creation with Heuristics
Aug 22, 2023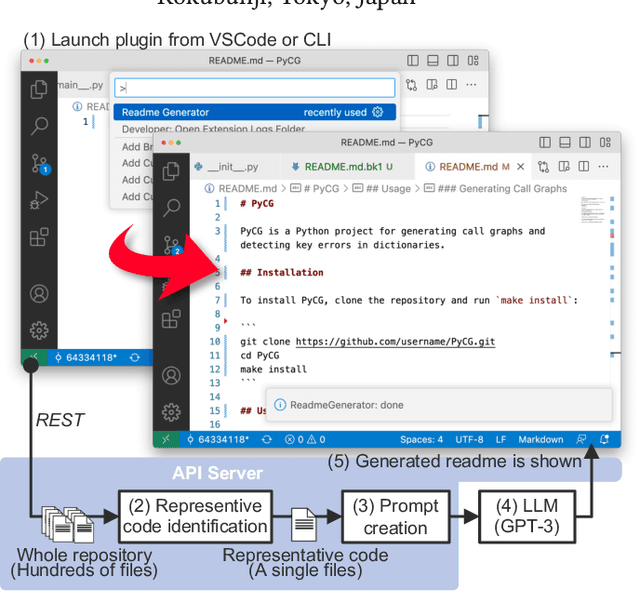
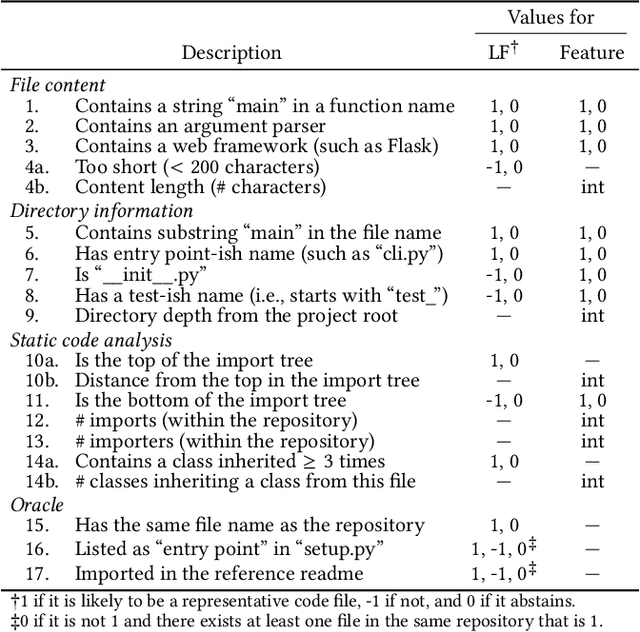
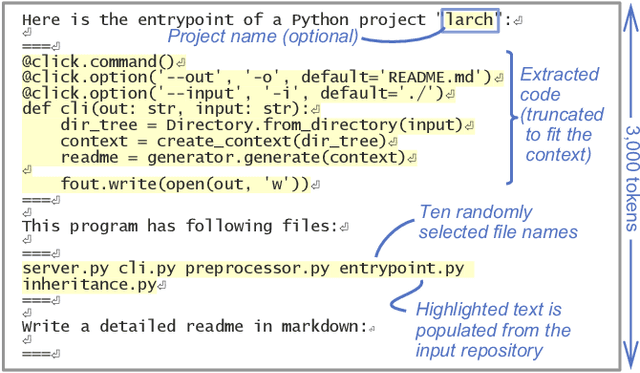

Writing a readme is a crucial aspect of software development as it plays a vital role in managing and reusing program code. Though it is a pain point for many developers, automatically creating one remains a challenge even with the recent advancements in large language models (LLMs), because it requires generating an abstract description from thousands of lines of code. In this demo paper, we show that LLMs are capable of generating a coherent and factually correct readmes if we can identify a code fragment that is representative of the repository. Building upon this finding, we developed LARCH (LLM-based Automatic Readme Creation with Heuristics) which leverages representative code identification with heuristics and weak supervision. Through human and automated evaluations, we illustrate that LARCH can generate coherent and factually correct readmes in the majority of cases, outperforming a baseline that does not rely on representative code identification. We have made LARCH open-source and provided a cross-platform Visual Studio Code interface and command-line interface, accessible at https://github.com/hitachi-nlp/larch. A demo video showcasing LARCH's capabilities is available at https://youtu.be/ZUKkh5ED-O4.
* This is a pre-print of a paper accepted at CIKM'23 Demo. Refer to the DOI URL for the original publication
Controlling keywords and their positions in text generation
Apr 19, 2023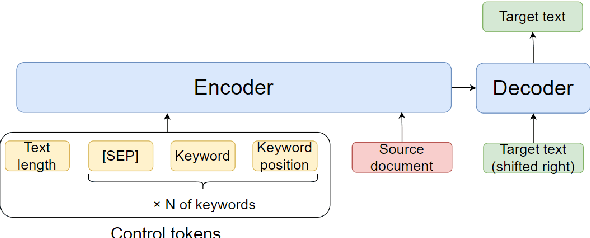
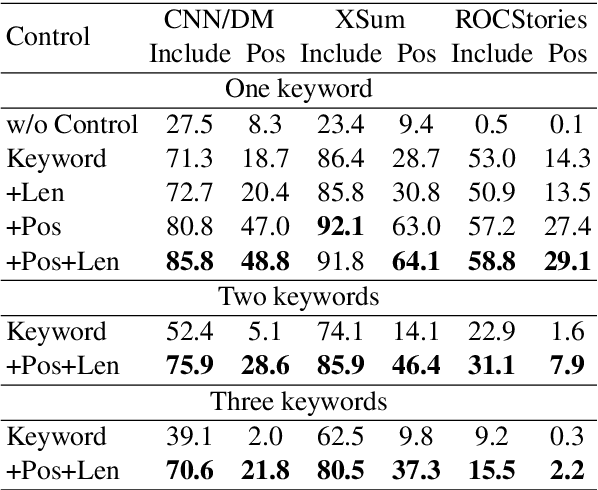
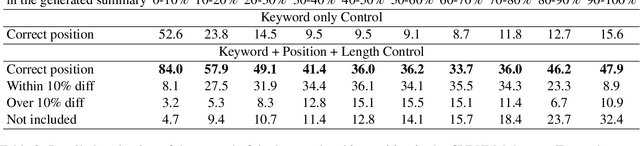
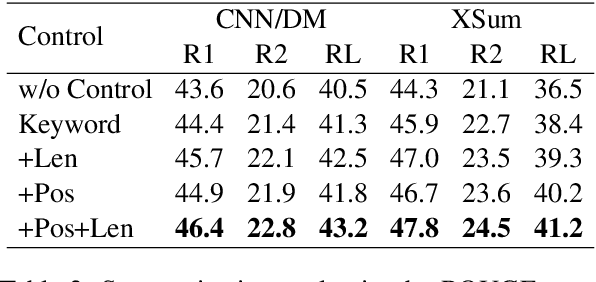
One of the challenges in text generation is to control generation as intended by a user. Previous studies have proposed to specify the keywords that should be included in the generated text. However, this is insufficient to generate text which reflect the user intent. For example, placing the important keyword beginning of the text would helps attract the reader's attention, but existing methods do not enable such flexible control. In this paper, we tackle a novel task of controlling not only keywords but also the position of each keyword in the text generation. To this end, we show that a method using special tokens can control the relative position of keywords. Experimental results on summarization and story generation tasks show that the proposed method can control keywords and their positions. We also demonstrate that controlling the keyword positions can generate summary texts that are closer to the user's intent than baseline. We release our code.