 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Micro Domain-Adaptive Pre-Training Effective for Real-World Operations? Multi-Step Evaluation Reveals Potential and Bottlenecks
Feb 04, 2026When applying LLMs to real-world enterprise operations, LLMs need to handle proprietary knowledge in small domains of specific operations ($\textbf{micro domains}$). A previous study shows micro domain-adaptive pre-training ($\textbf{mDAPT}$) with fewer documents is effective, similarly to DAPT in larger domains. However, it evaluates mDAPT only on multiple-choice questions; thus, its effectiveness for generative tasks in real-world operations remains unknown. We aim to reveal the potential and bottlenecks of mDAPT for generative tasks. To this end, we disentangle the answering process into three subtasks and evaluate the performance of each subtask: (1) $\textbf{eliciting}$ facts relevant to questions from an LLM's own knowledge, (2) $\textbf{reasoning}$ over the facts to obtain conclusions, and (3) $\textbf{composing}$ long-form answers based on the conclusions. We verified mDAPT on proprietary IT product knowledge for real-world questions in IT technical support operations. As a result, mDAPT resolved the elicitation task that the base model struggled with but did not resolve other subtasks. This clarifies mDAPT's effectiveness in the knowledge aspect and its bottlenecks in other aspects. Further analysis empirically shows that resolving the elicitation and reasoning tasks ensures sufficient performance (over 90%), emphasizing the need to enhance reasoning capability.
Vocabulary Expansion of Chat Models with Unlabeled Target Language Data
Dec 16, 2024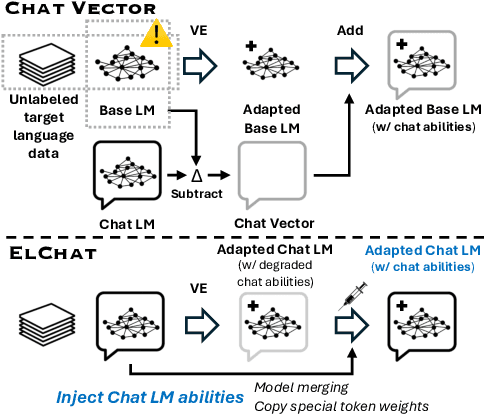
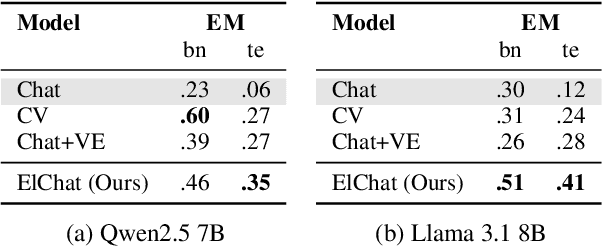
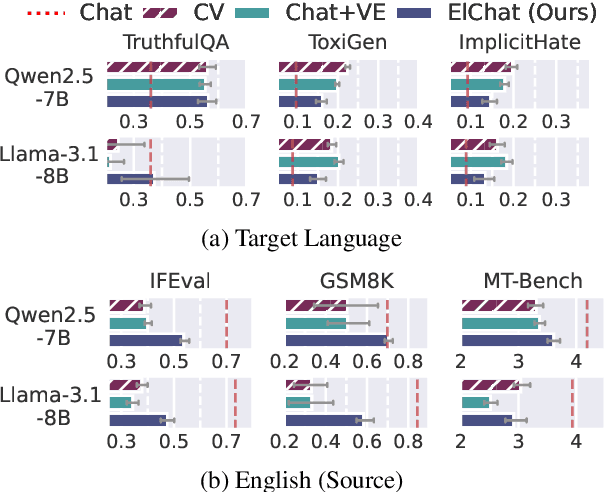
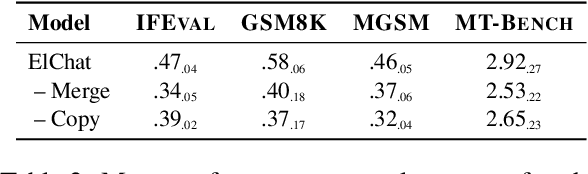
Chat models (i.e. language models trained to follow instructions through conversation with humans) outperform base models (i.e. trained solely on unlabeled data) in both conversation and general task-solving abilities. These models are generally English-centric and require further adaptation for languages that are underrepresented in or absent from their training data. A common technique for adapting base models is to extend the model's vocabulary with target language tokens, i.e. vocabulary expansion (VE), and then continually pre-train it on language-specific data. Using chat data is ideal for chat model adaptation, but often, either this does not exist or is costly to construct. Alternatively, adapting chat models with unlabeled data is a possible solution, but it could result in catastrophic forgetting. In this paper, we investigate the impact of using unlabeled target language data for VE on chat models for the first time. We first show that off-the-shelf VE generally performs well across target language tasks and models in 71% of cases, though it underperforms in scenarios where source chat models are already strong. To further improve adapted models, we propose post-hoc techniques that inject information from the source model without requiring any further training. Experiments reveal the effectiveness of our methods, helping the adapted models to achieve performance improvements in 87% of cases.
Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus
Nov 19, 2024



Large language models (LLMs) are capable of solving a wide range of tasks, yet they have struggled with reasoning. To address this, we propose $\textbf{Additional Logic Training (ALT)}$, which aims to enhance LLMs' reasoning capabilities by program-generated logical reasoning samples. We first establish principles for designing high-quality samples by integrating symbolic logic theory and previous empirical insights. Then, based on these principles, we construct a synthetic corpus named $\textbf{Formal Logic Deduction Diverse}$ ($\textbf{FLD}$$^{\times 2}$), comprising numerous samples of multi-step deduction with unknown facts, diverse reasoning rules, diverse linguistic expressions, and challenging distractors. Finally, we empirically show that ALT on FLD$^{\times2}$ substantially enhances the reasoning capabilities of state-of-the-art LLMs, including LLaMA-3.1-70B. Improvements include gains of up to 30 points on logical reasoning benchmarks, up to 10 points on math and coding benchmarks, and 5 points on the benchmark suite BBH.
appjsonify: An Academic Paper PDF-to-JSON Conversion Toolkit
Oct 03, 2023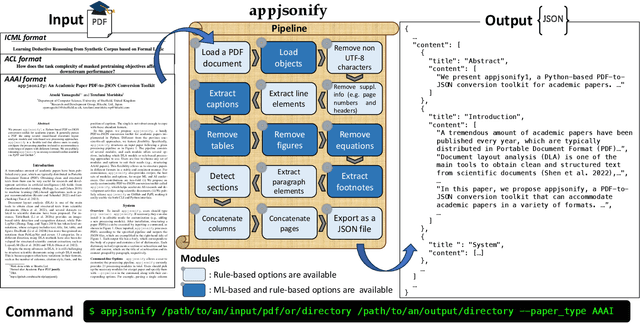
We present appjsonify, a Python-based PDF-to-JSON conversion toolkit for academic papers. It parses a PDF file using several visual-based document layout analysis models and rule-based text processing approaches. appjsonify is a flexible tool that allows users to easily configure the processing pipeline to handle a specific format of a paper they wish to process. We are publicly releasing appjsonify as an easy-to-install toolkit available via PyPI and GitHub.
LARCH: Large Language Model-based Automatic Readme Creation with Heuristics
Aug 22, 2023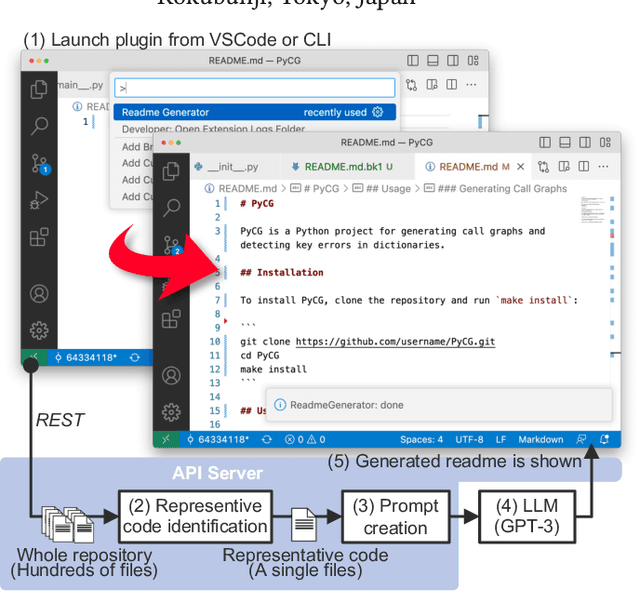
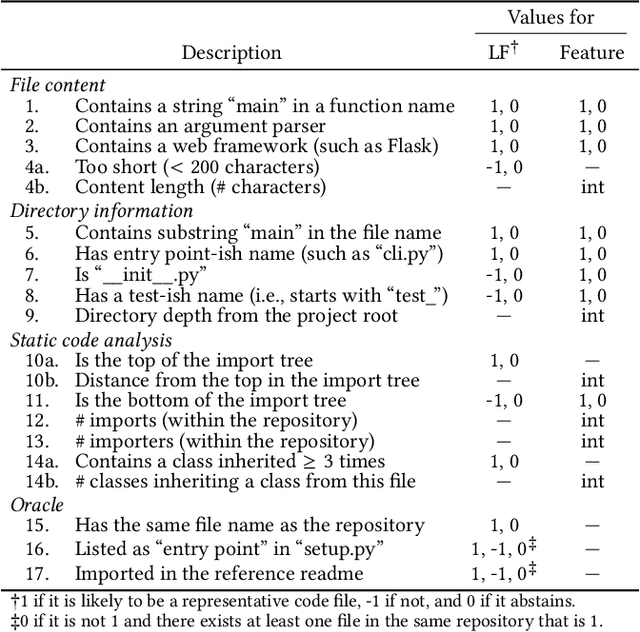
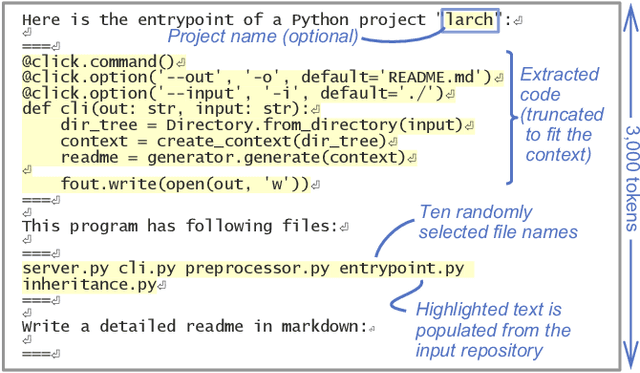

Writing a readme is a crucial aspect of software development as it plays a vital role in managing and reusing program code. Though it is a pain point for many developers, automatically creating one remains a challenge even with the recent advancements in large language models (LLMs), because it requires generating an abstract description from thousands of lines of code. In this demo paper, we show that LLMs are capable of generating a coherent and factually correct readmes if we can identify a code fragment that is representative of the repository. Building upon this finding, we developed LARCH (LLM-based Automatic Readme Creation with Heuristics) which leverages representative code identification with heuristics and weak supervision. Through human and automated evaluations, we illustrate that LARCH can generate coherent and factually correct readmes in the majority of cases, outperforming a baseline that does not rely on representative code identification. We have made LARCH open-source and provided a cross-platform Visual Studio Code interface and command-line interface, accessible at https://github.com/hitachi-nlp/larch. A demo video showcasing LARCH's capabilities is available at https://youtu.be/ZUKkh5ED-O4.
* This is a pre-print of a paper accepted at CIKM'23 Demo. Refer to the DOI URL for the original publication
Learning Deductive Reasoning from Synthetic Corpus based on Formal Logic
Aug 11, 2023



We study a synthetic corpus-based approach for language models (LMs) to acquire logical deductive reasoning ability. The previous studies generated deduction examples using specific sets of deduction rules. However, these rules were limited or otherwise arbitrary. This can limit the generalizability of acquired deductive reasoning ability. We rethink this and adopt a well-grounded set of deduction rules based on formal logic theory, which can derive any other deduction rules when combined in a multistep way. We empirically verify that LMs trained on the proposed corpora, which we name $\textbf{FLD}$ ($\textbf{F}$ormal $\textbf{L}$ogic $\textbf{D}$eduction), acquire more generalizable deductive reasoning ability. Furthermore, we identify the aspects of deductive reasoning ability on which deduction corpora can enhance LMs and those on which they cannot. Finally, on the basis of these results, we discuss the future directions for applying deduction corpora or other approaches for each aspect. We release the code, data, and models.
How do different tokenizers perform on downstream tasks in scriptio continua languages?: A case study in Japanese
Jun 16, 2023

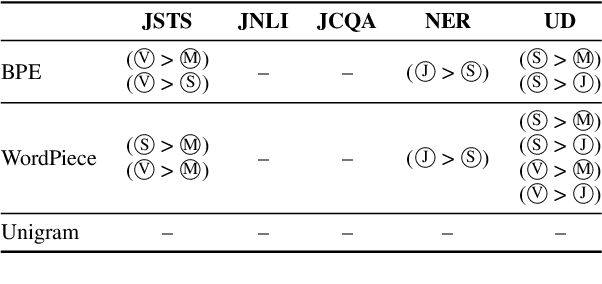

This paper investigates the effect of tokenizers on the downstream performance of pretrained language models (PLMs) in scriptio continua languages where no explicit spaces exist between words, using Japanese as a case study. The tokenizer for such languages often consists of a morphological analyzer and a subword tokenizer, requiring us to conduct a comprehensive study of all possible pairs. However, previous studies lack this comprehensiveness. We therefore train extensive sets of tokenizers, build a PLM using each, and measure the downstream performance on a wide range of tasks. Our results demonstrate that each downstream task has a different optimal morphological analyzer, and that it is better to use Byte-Pair-Encoding or Unigram rather than WordPiece as a subword tokenizer, regardless of the type of task.
How does the task complexity of masked pretraining objectives affect downstream performance?
May 18, 2023



Masked language modeling (MLM) is a widely used self-supervised pretraining objective, where a model needs to predict an original token that is replaced with a mask given contexts. Although simpler and computationally efficient pretraining objectives, e.g., predicting the first character of a masked token, have recently shown comparable results to MLM, no objectives with a masking scheme actually outperform it in downstream tasks. Motivated by the assumption that their lack of complexity plays a vital role in the degradation, we validate whether more complex masked objectives can achieve better results and investigate how much complexity they should have to perform comparably to MLM. Our results using GLUE, SQuAD, and Universal Dependencies benchmarks demonstrate that more complicated objectives tend to show better downstream results with at least half of the MLM complexity needed to perform comparably to MLM. Finally, we discuss how we should pretrain a model using a masked objective from the task complexity perspective.
Controlling keywords and their positions in text generation
Apr 19, 2023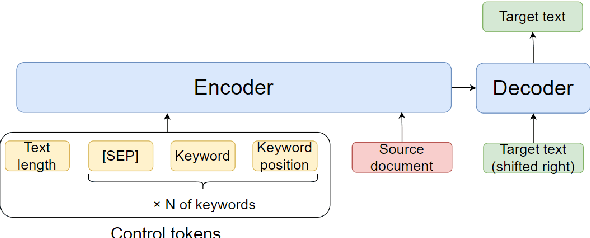
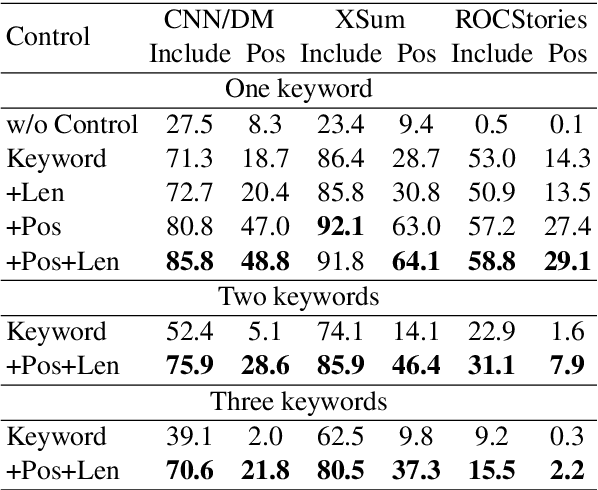
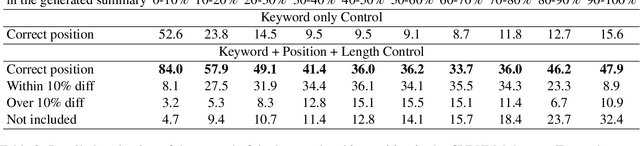
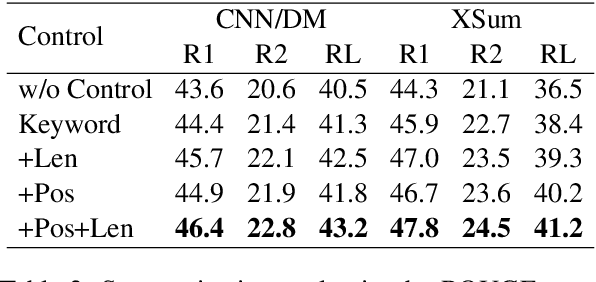
One of the challenges in text generation is to control generation as intended by a user. Previous studies have proposed to specify the keywords that should be included in the generated text. However, this is insufficient to generate text which reflect the user intent. For example, placing the important keyword beginning of the text would helps attract the reader's attention, but existing methods do not enable such flexible control. In this paper, we tackle a novel task of controlling not only keywords but also the position of each keyword in the text generation. To this end, we show that a method using special tokens can control the relative position of keywords. Experimental results on summarization and story generation tasks show that the proposed method can control keywords and their positions. We also demonstrate that controlling the keyword positions can generate summary texts that are closer to the user's intent than baseline. We release our code.
Rethinking Fano's Inequality in Ensemble Learning
May 25, 2022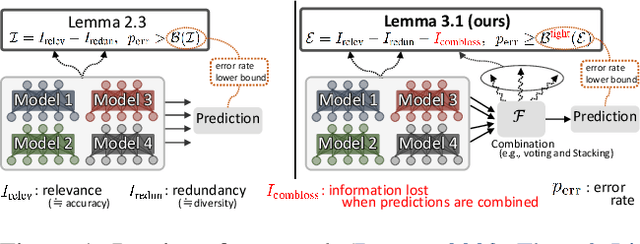
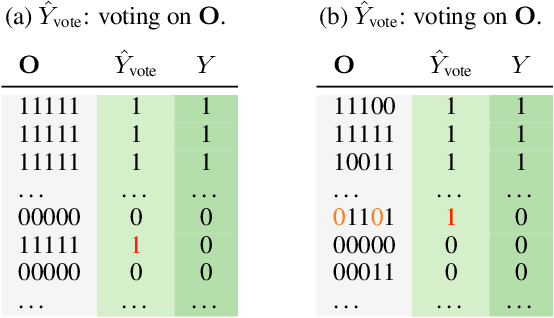

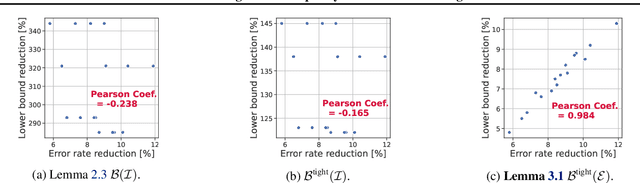
We propose a fundamental theory on ensemble learning that evaluates a given ensemble system by a well-grounded set of metrics. Previous studies used a variant of Fano's inequality of information theory and derived a lower bound of the classification error rate on the basis of the accuracy and diversity of models. We revisit the original Fano's inequality and argue that the studies did not take into account the information lost when multiple model predictions are combined into a final prediction. To address this issue, we generalize the previous theory to incorporate the information loss. Further, we empirically validate and demonstrate the proposed theory through extensive experiments on actual systems. The theory reveals the strengths and weaknesses of systems on each metric, which will push the theoretical understanding of ensemble learning and give us insights into designing systems.