 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHitachi at MRP 2019: Unified Encoder-to-Biaffine Network for Cross-Framework Meaning Representation Parsing
Paper and Code
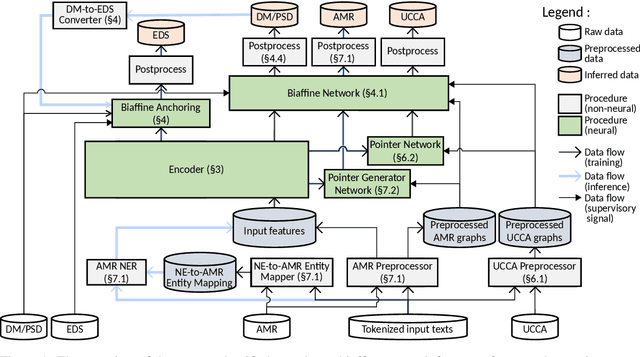
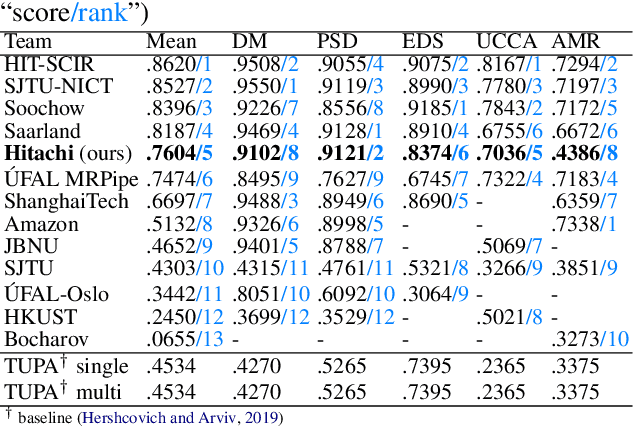
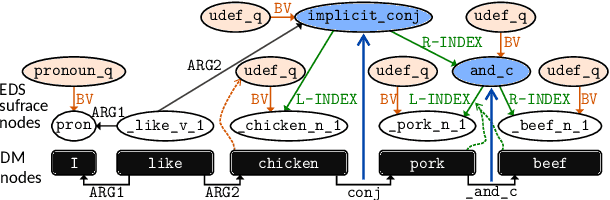
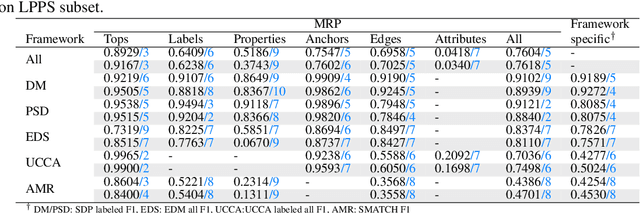
This paper describes the proposed system of the Hitachi team for the Cross-Framework Meaning Representation Parsing (MRP 2019) shared task. In this shared task, the participating systems were asked to predict nodes, edges and their attributes for five frameworks, each with different order of "abstraction" from input tokens. We proposed a unified encoder-to-biaffine network for all five frameworks, which effectively incorporates a shared encoder to extract rich input features, decoder networks to generate anchorless nodes in UCCA and AMR, and biaffine networks to predict edges. Our system was ranked fifth with the macro-averaged MRP F1 score of 0.7604, and outperformed the baseline unified transition-based MRP. Furthermore, post-evaluation experiments showed that we can boost the performance of the proposed system by incorporating multi-task learning, whereas the baseline could not. These imply efficacy of incorporating the biaffine network to the shared architecture for MRP and that learning heterogeneous meaning representations at once can boost the system performance.