 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Visual Encoder Learn to See Arrows?
May 26, 2025
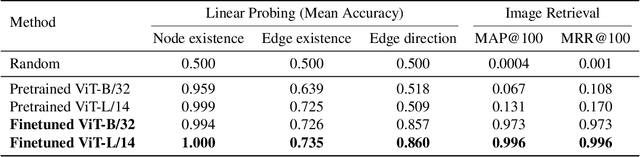


The diagram is a visual representation of a relationship illustrated with edges (lines or arrows), which is widely used in industrial and scientific communication. Although recognizing diagrams is essential for vision language models (VLMs) to comprehend domain-specific knowledge, recent studies reveal that many VLMs fail to identify edges in images. We hypothesize that these failures stem from an over-reliance on textual and positional biases, preventing VLMs from learning explicit edge features. Based on this idea, we empirically investigate whether the image encoder in VLMs can learn edge representation through training on a diagram dataset in which edges are biased neither by textual nor positional information. To this end, we conduct contrastive learning on an artificially generated diagram--caption dataset to train an image encoder and evaluate its diagram-related features on three tasks: probing, image retrieval, and captioning. Our results show that the finetuned model outperforms pretrained CLIP in all tasks and surpasses zero-shot GPT-4o and LLaVA-Mistral in the captioning task. These findings confirm that eliminating textual and positional biases fosters accurate edge recognition in VLMs, offering a promising path for advancing diagram understanding.
How does the task complexity of masked pretraining objectives affect downstream performance?
May 18, 2023



Masked language modeling (MLM) is a widely used self-supervised pretraining objective, where a model needs to predict an original token that is replaced with a mask given contexts. Although simpler and computationally efficient pretraining objectives, e.g., predicting the first character of a masked token, have recently shown comparable results to MLM, no objectives with a masking scheme actually outperform it in downstream tasks. Motivated by the assumption that their lack of complexity plays a vital role in the degradation, we validate whether more complex masked objectives can achieve better results and investigate how much complexity they should have to perform comparably to MLM. Our results using GLUE, SQuAD, and Universal Dependencies benchmarks demonstrate that more complicated objectives tend to show better downstream results with at least half of the MLM complexity needed to perform comparably to MLM. Finally, we discuss how we should pretrain a model using a masked objective from the task complexity perspective.
Controlling keywords and their positions in text generation
Apr 19, 2023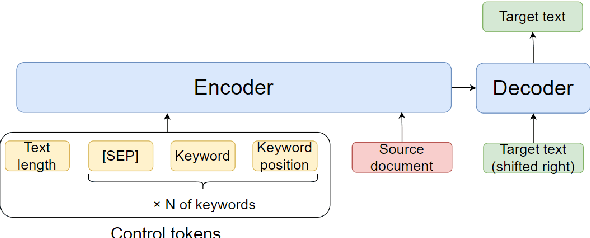
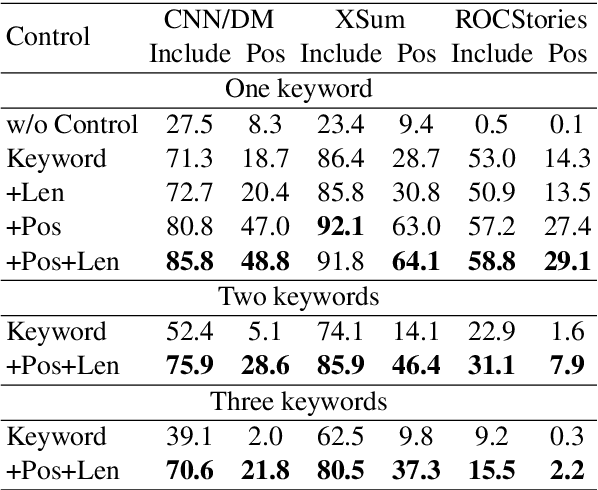
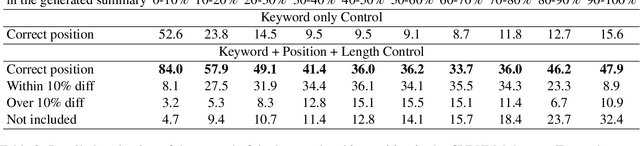
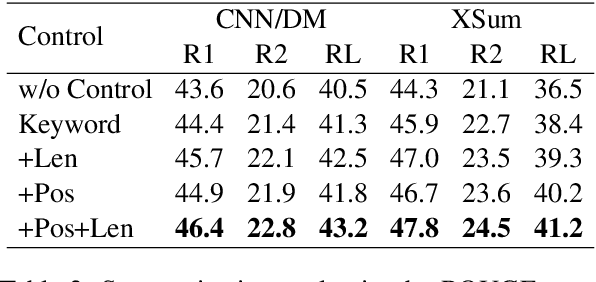
One of the challenges in text generation is to control generation as intended by a user. Previous studies have proposed to specify the keywords that should be included in the generated text. However, this is insufficient to generate text which reflect the user intent. For example, placing the important keyword beginning of the text would helps attract the reader's attention, but existing methods do not enable such flexible control. In this paper, we tackle a novel task of controlling not only keywords but also the position of each keyword in the text generation. To this end, we show that a method using special tokens can control the relative position of keywords. Experimental results on summarization and story generation tasks show that the proposed method can control keywords and their positions. We also demonstrate that controlling the keyword positions can generate summary texts that are closer to the user's intent than baseline. We release our code.
Team Hitachi at SemEval-2023 Task 3: Exploring Cross-lingual Multi-task Strategies for Genre and Framing Detection in Online News
Mar 03, 2023This paper explains the participation of team Hitachi to SemEval-2023 Task 3 "Detecting the genre, the framing, and the persuasion techniques in online news in a multi-lingual setup." Based on the multilingual, multi-task nature of the task and the setting that training data is limited, we investigated different strategies for training the pretrained language models under low resource settings. Through extensive experiments, we found that (a) cross-lingual/multi-task training, and (b) collecting an external balanced dataset, can benefit the genre and framing detection. We constructed ensemble models from the results and achieved the highest macro-averaged F1 scores in Italian and Russian genre categorization subtasks.
Rethinking Fano's Inequality in Ensemble Learning
May 25, 2022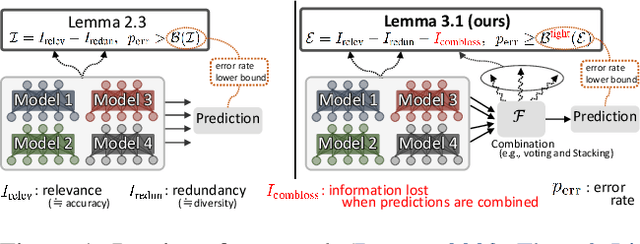
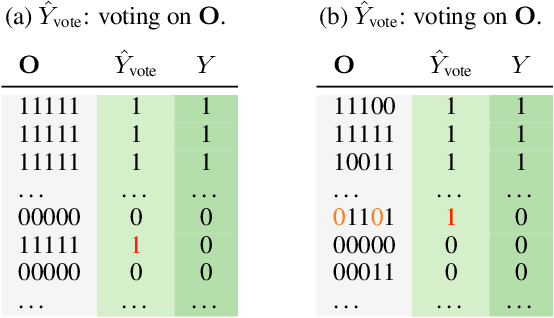

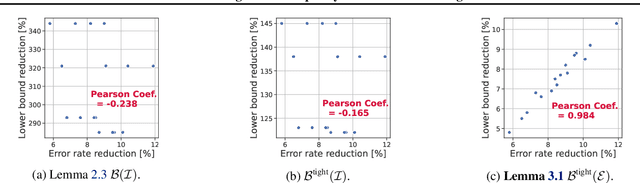
We propose a fundamental theory on ensemble learning that evaluates a given ensemble system by a well-grounded set of metrics. Previous studies used a variant of Fano's inequality of information theory and derived a lower bound of the classification error rate on the basis of the accuracy and diversity of models. We revisit the original Fano's inequality and argue that the studies did not take into account the information lost when multiple model predictions are combined into a final prediction. To address this issue, we generalize the previous theory to incorporate the information loss. Further, we empirically validate and demonstrate the proposed theory through extensive experiments on actual systems. The theory reveals the strengths and weaknesses of systems on each metric, which will push the theoretical understanding of ensemble learning and give us insights into designing systems.
Team Hitachi @ AutoMin 2021: Reference-free Automatic Minuting Pipeline with Argument Structure Construction over Topic-based Summarization
Dec 06, 2021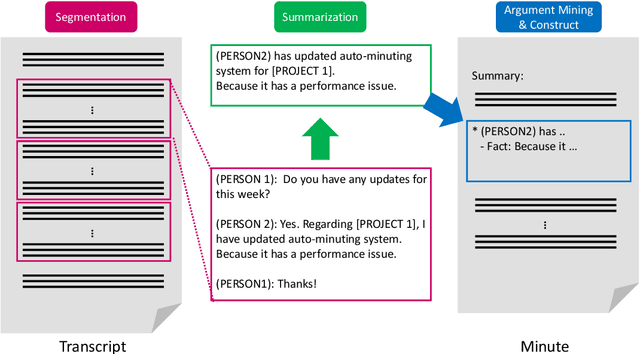


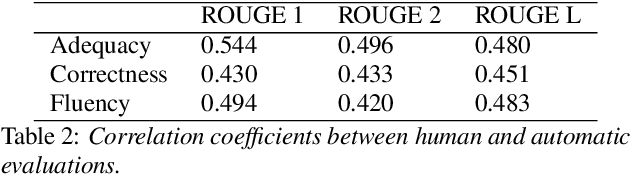
This paper introduces the proposed automatic minuting system of the Hitachi team for the First Shared Task on Automatic Minuting (AutoMin-2021). We utilize a reference-free approach (i.e., without using training minutes) for automatic minuting (Task A), which first splits a transcript into blocks on the basis of topics and subsequently summarizes those blocks with a pre-trained BART model fine-tuned on a summarization corpus of chat dialogue. In addition, we apply a technique of argument mining to the generated minutes, reorganizing them in a well-structured and coherent way. We utilize multiple relevance scores to determine whether or not a minute is derived from the same meeting when either a transcript or another minute is given (Task B and C). On top of those scores, we train a conventional machine learning model to bind them and to make final decisions. Consequently, our approach for Task A achieve the best adequacy score among all submissions and close performance to the best system in terms of grammatical correctness and fluency. For Task B and C, the proposed model successfully outperformed a majority vote baseline.
Hitachi at SemEval-2020 Task 12: Offensive Language Identification with Noisy Labels using Statistical Sampling and Post-Processing
May 01, 2020
In this paper, we present our participation in SemEval-2020 Task-12 Subtask-A (English Language) which focuses on offensive language identification from noisy labels. To this end, we developed a hybrid system with the BERT classifier trained with tweets selected using Statistical Sampling Algorithm (SA) and Post-Processed (PP) using an offensive wordlist. Our developed system achieved 34 th position with Macro-averaged F1-score (Macro-F1) of 0.90913 over both offensive and non-offensive classes. We further show comprehensive results and error analysis to assist future research in offensive language identification with noisy labels.
Hitachi at MRP 2019: Unified Encoder-to-Biaffine Network for Cross-Framework Meaning Representation Parsing
Oct 10, 2019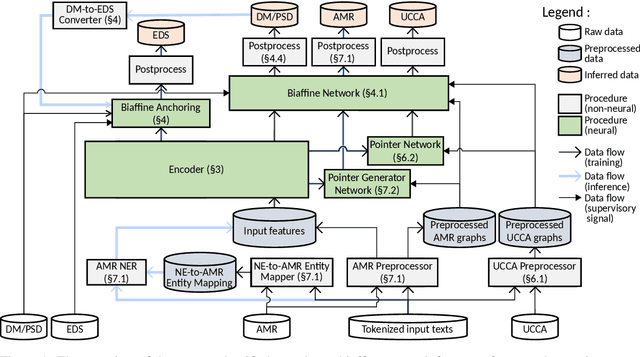
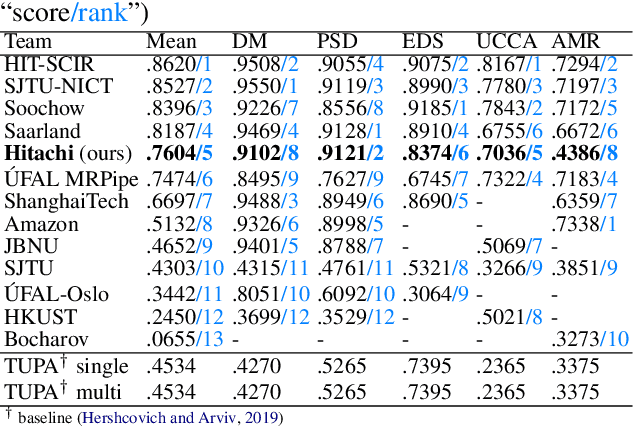
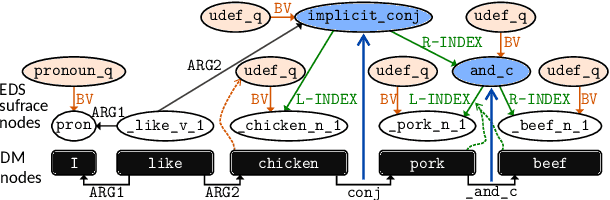
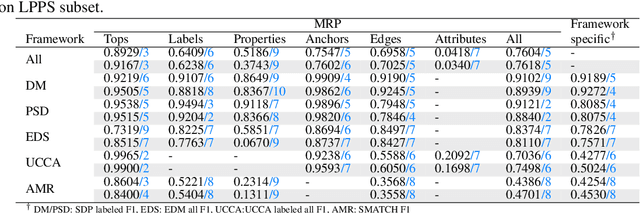
This paper describes the proposed system of the Hitachi team for the Cross-Framework Meaning Representation Parsing (MRP 2019) shared task. In this shared task, the participating systems were asked to predict nodes, edges and their attributes for five frameworks, each with different order of "abstraction" from input tokens. We proposed a unified encoder-to-biaffine network for all five frameworks, which effectively incorporates a shared encoder to extract rich input features, decoder networks to generate anchorless nodes in UCCA and AMR, and biaffine networks to predict edges. Our system was ranked fifth with the macro-averaged MRP F1 score of 0.7604, and outperformed the baseline unified transition-based MRP. Furthermore, post-evaluation experiments showed that we can boost the performance of the proposed system by incorporating multi-task learning, whereas the baseline could not. These imply efficacy of incorporating the biaffine network to the shared architecture for MRP and that learning heterogeneous meaning representations at once can boost the system performance.