 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Benchmark for Framing of Oil & Gas Advertising and Potential Greenwashing Detection
Oct 24, 2025Companies spend large amounts of money on public relations campaigns to project a positive brand image. However, sometimes there is a mismatch between what they say and what they do. Oil & gas companies, for example, are accused of "greenwashing" with imagery of climate-friendly initiatives. Understanding the framing, and changes in framing, at scale can help better understand the goals and nature of public relations campaigns. To address this, we introduce a benchmark dataset of expert-annotated video ads obtained from Facebook and YouTube. The dataset provides annotations for 13 framing types for more than 50 companies or advocacy groups across 20 countries. Our dataset is especially designed for the evaluation of vision-language models (VLMs), distinguishing it from past text-only framing datasets. Baseline experiments show some promising results, while leaving room for improvement for future work: GPT-4.1 can detect environmental messages with 79% F1 score, while our best model only achieves 46% F1 score on identifying framing around green innovation. We also identify challenges that VLMs must address, such as implicit framing, handling videos of various lengths, or implicit cultural backgrounds. Our dataset contributes to research in multimodal analysis of strategic communication in the energy sector.
Enhancing Reasoning Capabilities of LLMs via Principled Synthetic Logic Corpus
Nov 19, 2024



Large language models (LLMs) are capable of solving a wide range of tasks, yet they have struggled with reasoning. To address this, we propose $\textbf{Additional Logic Training (ALT)}$, which aims to enhance LLMs' reasoning capabilities by program-generated logical reasoning samples. We first establish principles for designing high-quality samples by integrating symbolic logic theory and previous empirical insights. Then, based on these principles, we construct a synthetic corpus named $\textbf{Formal Logic Deduction Diverse}$ ($\textbf{FLD}$$^{\times 2}$), comprising numerous samples of multi-step deduction with unknown facts, diverse reasoning rules, diverse linguistic expressions, and challenging distractors. Finally, we empirically show that ALT on FLD$^{\times2}$ substantially enhances the reasoning capabilities of state-of-the-art LLMs, including LLaMA-3.1-70B. Improvements include gains of up to 30 points on logical reasoning benchmarks, up to 10 points on math and coding benchmarks, and 5 points on the benchmark suite BBH.
Learning Deductive Reasoning from Synthetic Corpus based on Formal Logic
Aug 11, 2023



We study a synthetic corpus-based approach for language models (LMs) to acquire logical deductive reasoning ability. The previous studies generated deduction examples using specific sets of deduction rules. However, these rules were limited or otherwise arbitrary. This can limit the generalizability of acquired deductive reasoning ability. We rethink this and adopt a well-grounded set of deduction rules based on formal logic theory, which can derive any other deduction rules when combined in a multistep way. We empirically verify that LMs trained on the proposed corpora, which we name $\textbf{FLD}$ ($\textbf{F}$ormal $\textbf{L}$ogic $\textbf{D}$eduction), acquire more generalizable deductive reasoning ability. Furthermore, we identify the aspects of deductive reasoning ability on which deduction corpora can enhance LMs and those on which they cannot. Finally, on the basis of these results, we discuss the future directions for applying deduction corpora or other approaches for each aspect. We release the code, data, and models.
How does the task complexity of masked pretraining objectives affect downstream performance?
May 18, 2023



Masked language modeling (MLM) is a widely used self-supervised pretraining objective, where a model needs to predict an original token that is replaced with a mask given contexts. Although simpler and computationally efficient pretraining objectives, e.g., predicting the first character of a masked token, have recently shown comparable results to MLM, no objectives with a masking scheme actually outperform it in downstream tasks. Motivated by the assumption that their lack of complexity plays a vital role in the degradation, we validate whether more complex masked objectives can achieve better results and investigate how much complexity they should have to perform comparably to MLM. Our results using GLUE, SQuAD, and Universal Dependencies benchmarks demonstrate that more complicated objectives tend to show better downstream results with at least half of the MLM complexity needed to perform comparably to MLM. Finally, we discuss how we should pretrain a model using a masked objective from the task complexity perspective.
Rethinking Fano's Inequality in Ensemble Learning
May 25, 2022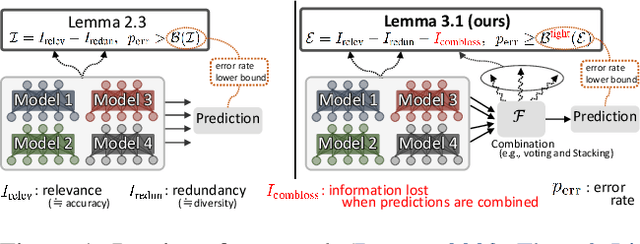
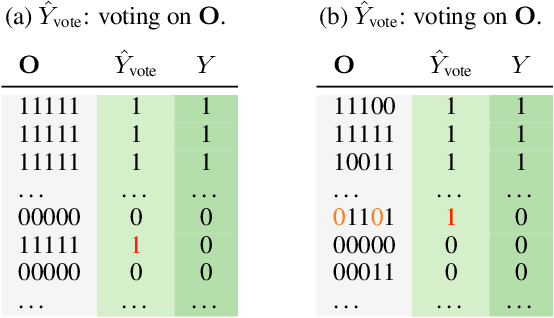

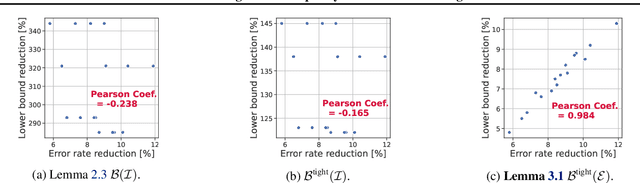
We propose a fundamental theory on ensemble learning that evaluates a given ensemble system by a well-grounded set of metrics. Previous studies used a variant of Fano's inequality of information theory and derived a lower bound of the classification error rate on the basis of the accuracy and diversity of models. We revisit the original Fano's inequality and argue that the studies did not take into account the information lost when multiple model predictions are combined into a final prediction. To address this issue, we generalize the previous theory to incorporate the information loss. Further, we empirically validate and demonstrate the proposed theory through extensive experiments on actual systems. The theory reveals the strengths and weaknesses of systems on each metric, which will push the theoretical understanding of ensemble learning and give us insights into designing systems.
Team Hitachi @ AutoMin 2021: Reference-free Automatic Minuting Pipeline with Argument Structure Construction over Topic-based Summarization
Dec 06, 2021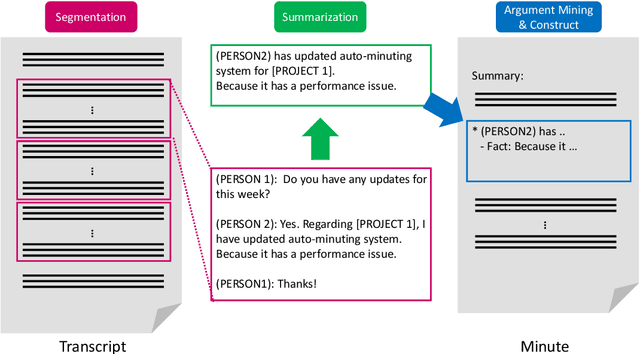


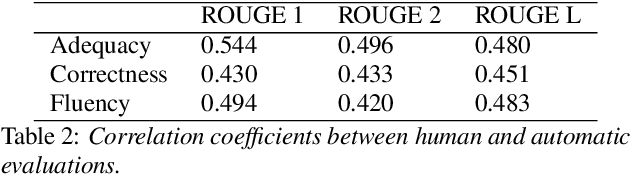
This paper introduces the proposed automatic minuting system of the Hitachi team for the First Shared Task on Automatic Minuting (AutoMin-2021). We utilize a reference-free approach (i.e., without using training minutes) for automatic minuting (Task A), which first splits a transcript into blocks on the basis of topics and subsequently summarizes those blocks with a pre-trained BART model fine-tuned on a summarization corpus of chat dialogue. In addition, we apply a technique of argument mining to the generated minutes, reorganizing them in a well-structured and coherent way. We utilize multiple relevance scores to determine whether or not a minute is derived from the same meeting when either a transcript or another minute is given (Task B and C). On top of those scores, we train a conventional machine learning model to bind them and to make final decisions. Consequently, our approach for Task A achieve the best adequacy score among all submissions and close performance to the best system in terms of grammatical correctness and fluency. For Task B and C, the proposed model successfully outperformed a majority vote baseline.
Hitachi at MRP 2019: Unified Encoder-to-Biaffine Network for Cross-Framework Meaning Representation Parsing
Oct 10, 2019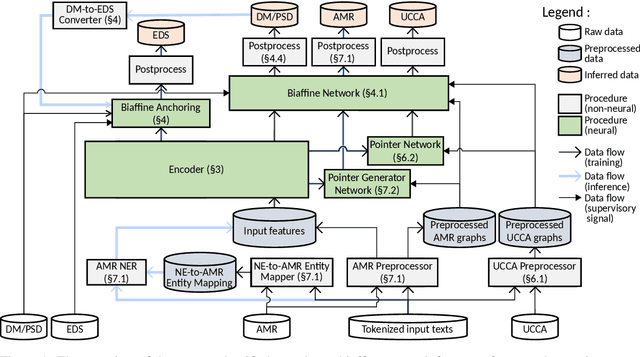
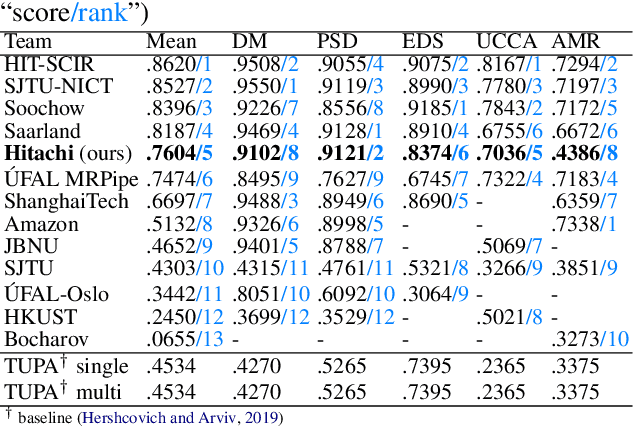
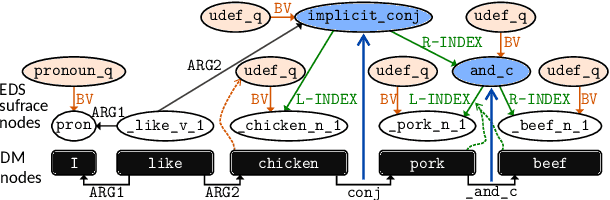
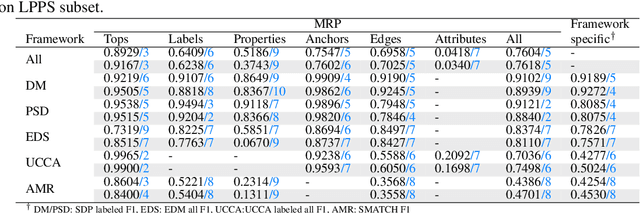
This paper describes the proposed system of the Hitachi team for the Cross-Framework Meaning Representation Parsing (MRP 2019) shared task. In this shared task, the participating systems were asked to predict nodes, edges and their attributes for five frameworks, each with different order of "abstraction" from input tokens. We proposed a unified encoder-to-biaffine network for all five frameworks, which effectively incorporates a shared encoder to extract rich input features, decoder networks to generate anchorless nodes in UCCA and AMR, and biaffine networks to predict edges. Our system was ranked fifth with the macro-averaged MRP F1 score of 0.7604, and outperformed the baseline unified transition-based MRP. Furthermore, post-evaluation experiments showed that we can boost the performance of the proposed system by incorporating multi-task learning, whereas the baseline could not. These imply efficacy of incorporating the biaffine network to the shared architecture for MRP and that learning heterogeneous meaning representations at once can boost the system performance.
End-to-End Argument Mining for Discussion Threads Based on Parallel Constrained Pointer Architecture
Sep 03, 2018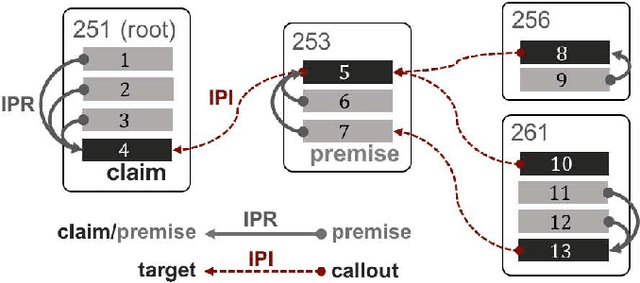
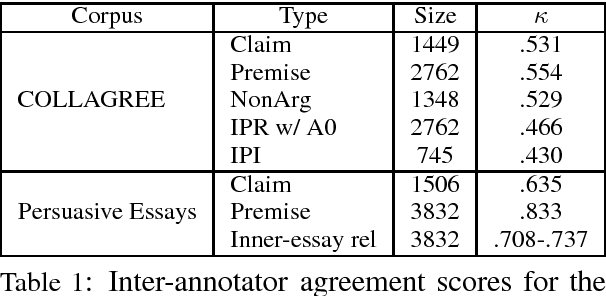

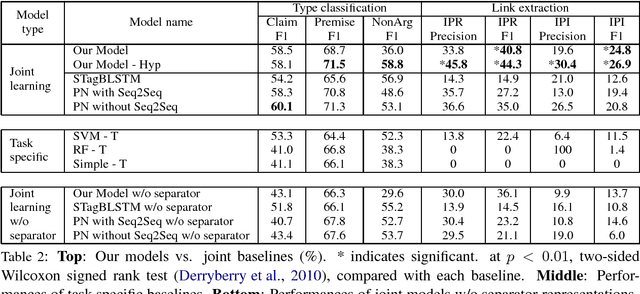
Argument Mining (AM) is a relatively recent discipline, which concentrates on extracting claims or premises from discourses, and inferring their structures. However, many existing works do not consider micro-level AM studies on discussion threads sufficiently. In this paper, we tackle AM for discussion threads. Our main contributions are follows: (1) A novel combination scheme focusing on micro-level inner- and inter- post schemes for a discussion thread. (2) Annotation of large-scale civic discussion threads with the scheme. (3) Parallel constrained pointer architecture (PCPA), a novel end-to-end technique to discriminate sentence types, inner-post relations, and inter-post interactions simultaneously. The experimental results demonstrate that our proposed model shows better accuracy in terms of relations extraction, in comparison to existing state-of-the-art models.