 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Japanese Language Model and Three New Evaluation Benchmarks for Pharmaceutical NLP
May 22, 2025

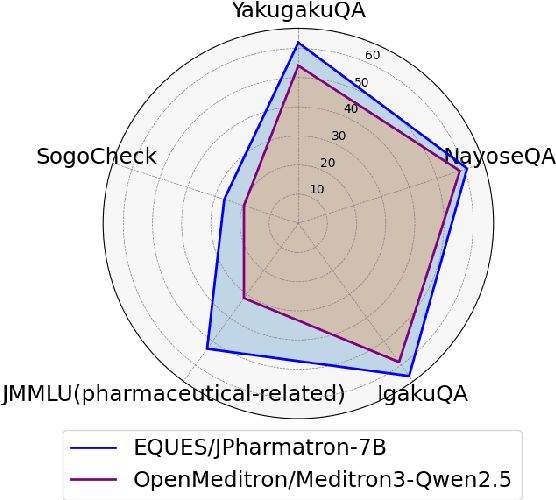
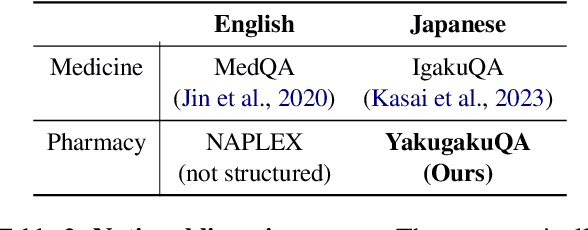
We present a Japanese domain-specific language model for the pharmaceutical field, developed through continual pretraining on 2 billion Japanese pharmaceutical tokens and 8 billion English biomedical tokens. To enable rigorous evaluation, we introduce three new benchmarks: YakugakuQA, based on national pharmacist licensing exams; NayoseQA, which tests cross-lingual synonym and terminology normalization; and SogoCheck, a novel task designed to assess consistency reasoning between paired statements. We evaluate our model against both open-source medical LLMs and commercial models, including GPT-4o. Results show that our domain-specific model outperforms existing open models and achieves competitive performance with commercial ones, particularly on terminology-heavy and knowledge-based tasks. Interestingly, even GPT-4o performs poorly on SogoCheck, suggesting that cross-sentence consistency reasoning remains an open challenge. Our benchmark suite offers a broader diagnostic lens for pharmaceutical NLP, covering factual recall, lexical variation, and logical consistency. This work demonstrates the feasibility of building practical, secure, and cost-effective language models for Japanese domain-specific applications, and provides reusable evaluation resources for future research in pharmaceutical and healthcare NLP. Our model, codes, and datasets are released at https://github.com/EQUES-Inc/pharma-LLM-eval.
JAPAGEN: Efficient Few/Zero-shot Learning via Japanese Training Dataset Generation with LLM
Dec 09, 2024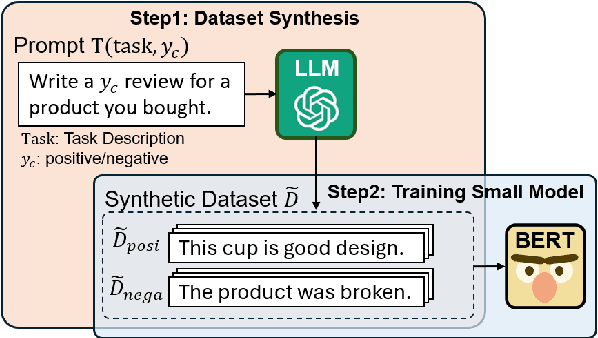



Recently some studies have highlighted the potential of Large Language Models (LLMs) as effective generators of supervised training data, offering advantages such as enhanced inference efficiency and reduced costs associated with data collection. However, these studies have predominantly focused on English language tasks. In this paper, we address the fundamental research question: Can LLMs serve as proficient training data generators for other language tasks? Specifically, we leverage LLMs to synthesize supervised training data under few-shot and zero-shot learning scenarios across six diverse Japanese downstream tasks. Subsequently, we utilize this synthesized data to train compact models (e.g., BERT). This novel methodology is termed JAPAGEN. Our experimental findings underscore that JAPAGEN achieves robust performance in classification tasks that necessitate formal text inputs, demonstrating competitive results compared to conventional LLM prompting strategies.
Automated Sperm Assessment Framework and Neural Network Specialized for Sperm Video Recognition
Nov 13, 2023Infertility is a global health problem, and an increasing number of couples are seeking medical assistance to achieve reproduction, at least half of which are caused by men. The success rate of assisted reproductive technologies depends on sperm assessment, in which experts determine whether sperm can be used for reproduction based on morphology and motility of sperm. Previous sperm assessment studies with deep learning have used datasets comprising images that include only sperm heads, which cannot consider motility and other morphologies of sperm. Furthermore, the labels of the dataset are one-hot, which provides insufficient support for experts, because assessment results are inconsistent between experts, and they have no absolute answer. Therefore, we constructed the video dataset for sperm assessment whose videos include sperm head as well as neck and tail, and its labels were annotated with soft-label. Furthermore, we proposed the sperm assessment framework and the neural network, RoSTFine, for sperm video recognition. Experimental results showed that RoSTFine could improve the sperm assessment performances compared to existing video recognition models and focus strongly on important sperm parts (i.e., head and neck).
BiLMa: Bidirectional Local-Matching for Text-based Person Re-identification
Sep 09, 2023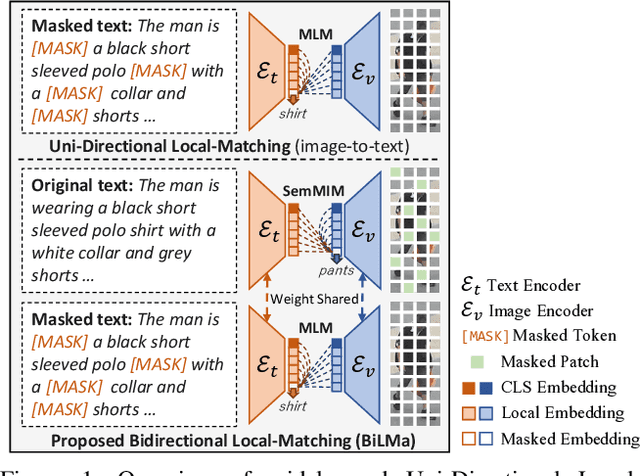
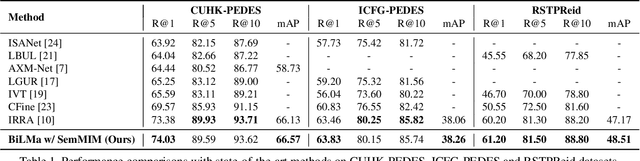
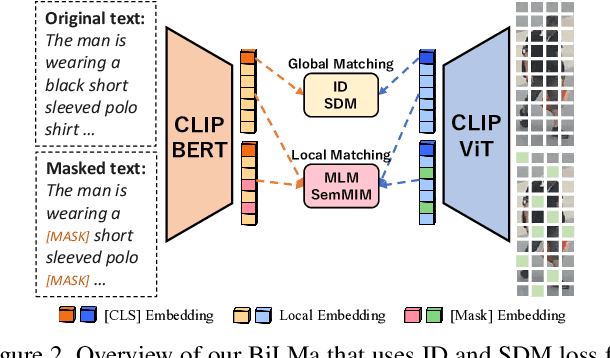

Text-based person re-identification (TBPReID) aims to retrieve person images represented by a given textual query. In this task, how to effectively align images and texts globally and locally is a crucial challenge. Recent works have obtained high performances by solving Masked Language Modeling (MLM) to align image/text parts. However, they only performed uni-directional (i.e., from image to text) local-matching, leaving room for improvement by introducing opposite-directional (i.e., from text to image) local-matching. In this work, we introduce Bidirectional Local-Matching (BiLMa) framework that jointly optimize MLM and Masked Image Modeling (MIM) in TBPReID model training. With this framework, our model is trained so as the labels of randomly masked both image and text tokens are predicted by unmasked tokens. In addition, to narrow the semantic gap between image and text in MIM, we propose Semantic MIM (SemMIM), in which the labels of masked image tokens are automatically given by a state-of-the-art human parser. Experimental results demonstrate that our BiLMa framework with SemMIM achieves state-of-the-art Rank@1 and mAP scores on three benchmarks.
How do different tokenizers perform on downstream tasks in scriptio continua languages?: A case study in Japanese
Jun 16, 2023

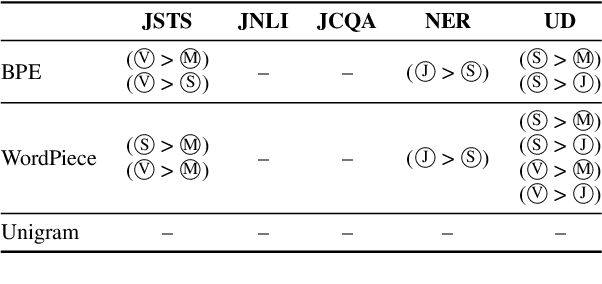

This paper investigates the effect of tokenizers on the downstream performance of pretrained language models (PLMs) in scriptio continua languages where no explicit spaces exist between words, using Japanese as a case study. The tokenizer for such languages often consists of a morphological analyzer and a subword tokenizer, requiring us to conduct a comprehensive study of all possible pairs. However, previous studies lack this comprehensiveness. We therefore train extensive sets of tokenizers, build a PLM using each, and measure the downstream performance on a wide range of tasks. Our results demonstrate that each downstream task has a different optimal morphological analyzer, and that it is better to use Byte-Pair-Encoding or Unigram rather than WordPiece as a subword tokenizer, regardless of the type of task.