 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJAPAGEN: Efficient Few/Zero-shot Learning via Japanese Training Dataset Generation with LLM
Dec 09, 2024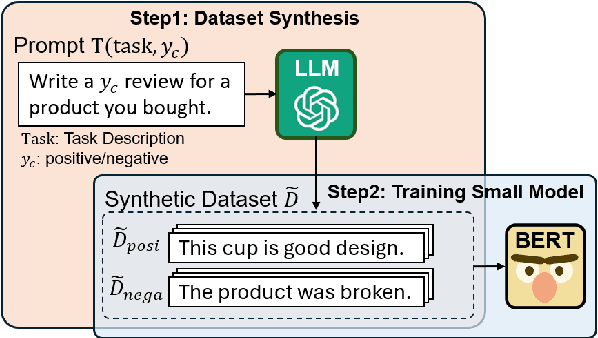



Recently some studies have highlighted the potential of Large Language Models (LLMs) as effective generators of supervised training data, offering advantages such as enhanced inference efficiency and reduced costs associated with data collection. However, these studies have predominantly focused on English language tasks. In this paper, we address the fundamental research question: Can LLMs serve as proficient training data generators for other language tasks? Specifically, we leverage LLMs to synthesize supervised training data under few-shot and zero-shot learning scenarios across six diverse Japanese downstream tasks. Subsequently, we utilize this synthesized data to train compact models (e.g., BERT). This novel methodology is termed JAPAGEN. Our experimental findings underscore that JAPAGEN achieves robust performance in classification tasks that necessitate formal text inputs, demonstrating competitive results compared to conventional LLM prompting strategies.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
Chinese Grammatical Correction Using BERT-based Pre-trained Model
Nov 04, 2020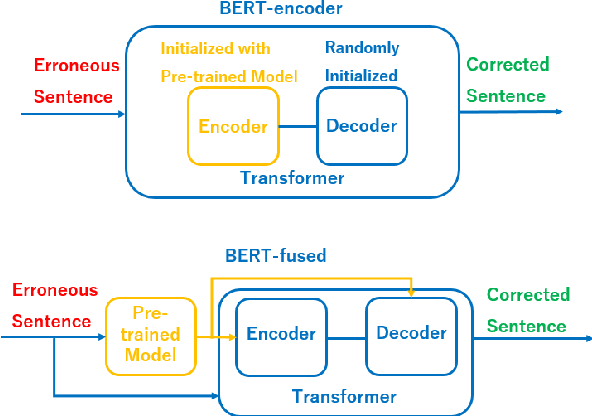
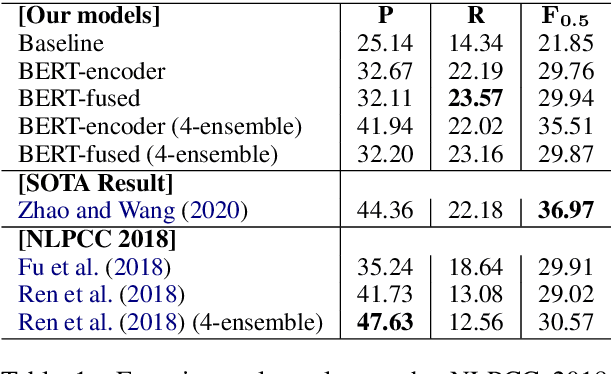


In recent years, pre-trained models have been extensively studied, and several downstream tasks have benefited from their utilization. In this study, we verify the effectiveness of two methods that incorporate a BERT-based pre-trained model developed by Cui et al. (2020) into an encoder-decoder model on Chinese grammatical error correction tasks. We also analyze the error type and conclude that sentence-level errors are yet to be addressed.
Stronger Baselines for Grammatical Error Correction Using Pretrained Encoder-Decoder Model
May 24, 2020
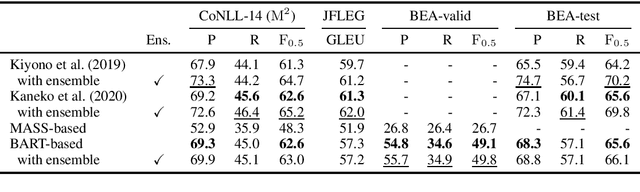
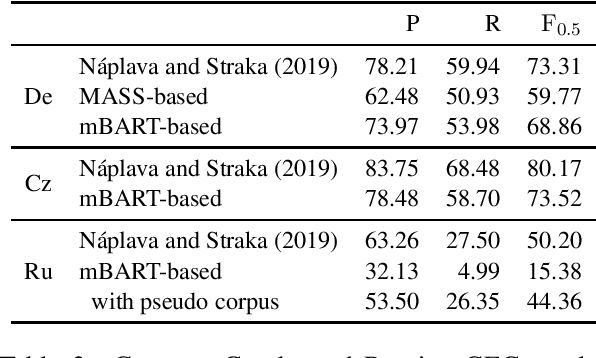
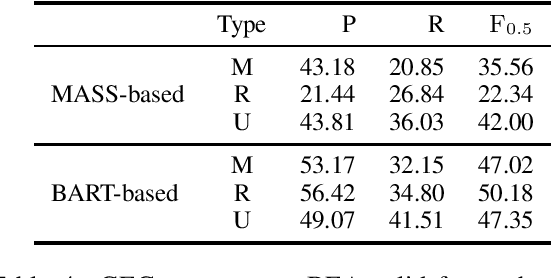
Grammatical error correction (GEC) literature has reported on the effectiveness of pretraining a Seq2Seq model with a large amount of pseudo data. In this study, we explored two generic pretrained encoder-decoder (Enc-Dec) models, including BART, which reported the state-of-the-art (SOTA) results for several Seq2Seq tasks other than GEC. We found that monolingual and multilingual BART models achieve high performance in GEC, including a competitive result compared with the current SOTA result in English GEC. Our implementations will be publicly available at GitHub.
Towards Unsupervised Grammatical Error Correction using Statistical Machine Translation with Synthetic Comparable Corpus
Jul 23, 2019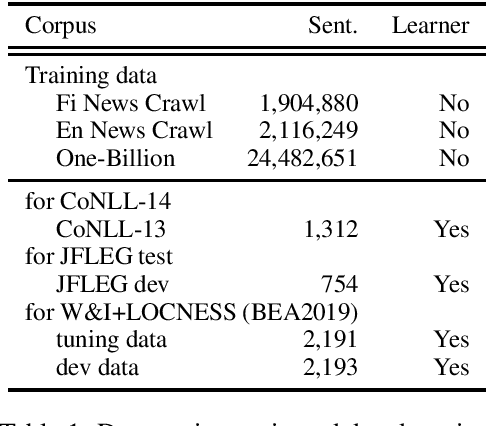
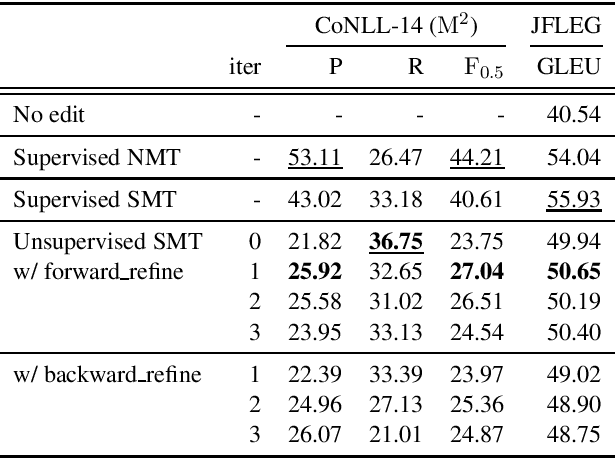
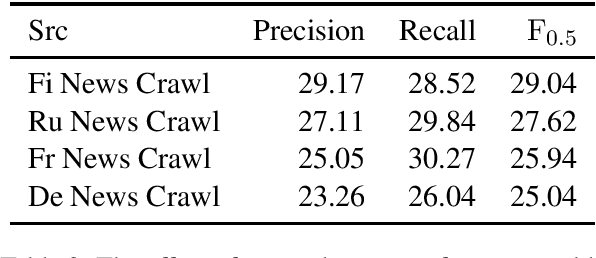
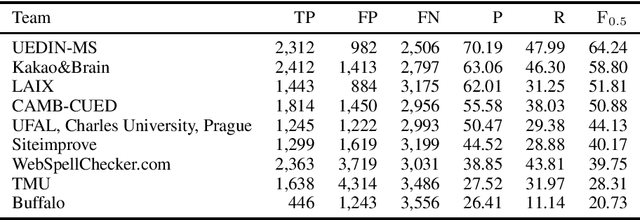
We introduce unsupervised techniques based on phrase-based statistical machine translation for grammatical error correction (GEC) trained on a pseudo learner corpus created by Google Translation. We verified our GEC system through experiments on various GEC dataset, includi ng a low resource track of the shared task at Building Educational Applications 2019 (BEA 2019). As a result, we achieved an F_0.5 score of 28.31 points with the test data of the low resource track.
Graph-based Filtering of Out-of-Vocabulary Words for Encoder-Decoder Models
May 28, 2018



Encoder-decoder models typically only employ words that are frequently used in the training corpus to reduce the computational costs and exclude noise. However, this vocabulary set may still include words that interfere with learning in encoder-decoder models. This paper proposes a method for selecting more suitable words for learning encoders by utilizing not only frequency, but also co-occurrence information, which we capture using the HITS algorithm. We apply our proposed method to two tasks: machine translation and grammatical error correction. For Japanese-to-English translation, this method achieves a BLEU score that is 0.56 points more than that of a baseline. It also outperforms the baseline method for English grammatical error correction, with an F0.5-measure that is 1.48 points higher.