Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStronger Baselines for Grammatical Error Correction Using Pretrained Encoder-Decoder Model
Paper and Code
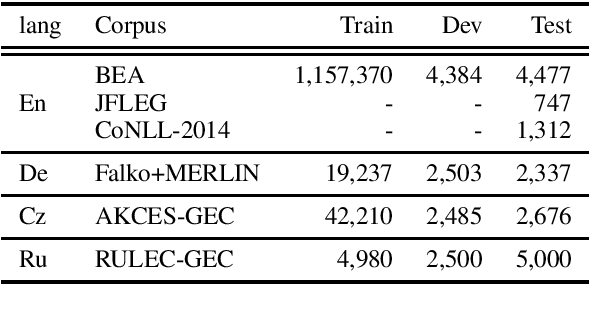
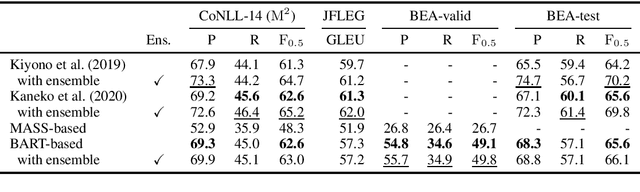
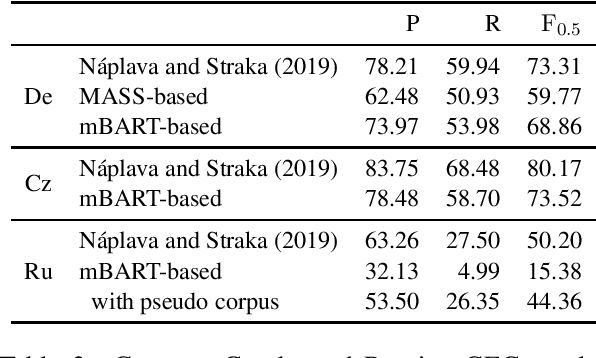
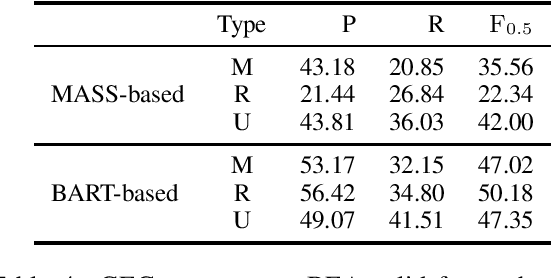
Grammatical error correction (GEC) literature has reported on the effectiveness of pretraining a Seq2Seq model with a large amount of pseudo data. In this study, we explored two generic pretrained encoder-decoder (Enc-Dec) models, including BART, which reported the state-of-the-art (SOTA) results for several Seq2Seq tasks other than GEC. We found that monolingual and multilingual BART models achieve high performance in GEC, including a competitive result compared with the current SOTA result in English GEC. Our implementations will be publicly available at GitHub.
View paper on