 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChinese Grammatical Correction Using BERT-based Pre-trained Model
Nov 04, 2020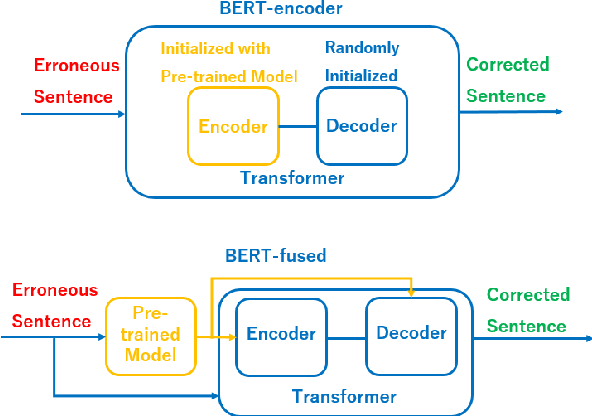
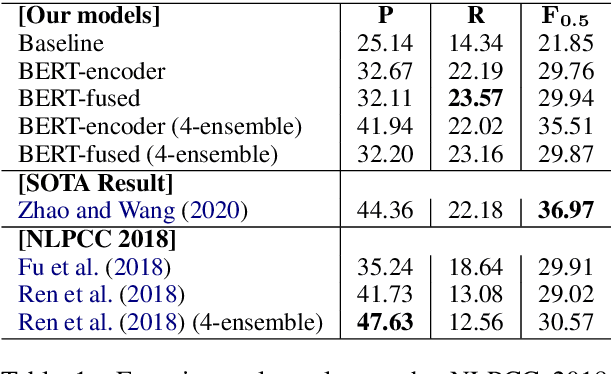


In recent years, pre-trained models have been extensively studied, and several downstream tasks have benefited from their utilization. In this study, we verify the effectiveness of two methods that incorporate a BERT-based pre-trained model developed by Cui et al. (2020) into an encoder-decoder model on Chinese grammatical error correction tasks. We also analyze the error type and conclude that sentence-level errors are yet to be addressed.
Dynamic Fusion: Attentional Language Model for Neural Machine Translation
Sep 11, 2019



Neural Machine Translation (NMT) can be used to generate fluent output. As such, language models have been investigated for incorporation with NMT. In prior investigations, two models have been used: a translation model and a language model. The translation model's predictions are weighted by the language model with a hand-crafted ratio in advance. However, these approaches fail to adopt the language model weighting with regard to the translation history. In another line of approach, language model prediction is incorporated into the translation model by jointly considering source and target information. However, this line of approach is limited because it largely ignores the adequacy of the translation output. Accordingly, this work employs two mechanisms, the translation model and the language model, with an attentive architecture to the language model as an auxiliary element of the translation model. Compared with previous work in English--Japanese machine translation using a language model, the experimental results obtained with the proposed Dynamic Fusion mechanism improve BLEU and Rank-based Intuitive Bilingual Evaluation Scores (RIBES) scores. Additionally, in the analyses of the attention and predictivity of the language model, the Dynamic Fusion mechanism allows predictive language modeling that conforms to the appropriate grammatical structure.
Japanese Predicate Conjugation for Neural Machine Translation
May 25, 2018

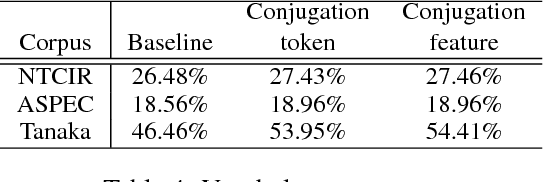
Neural machine translation (NMT) has a drawback in that can generate only high-frequency words owing to the computational costs of the softmax function in the output layer. In Japanese-English NMT, Japanese predicate conjugation causes an increase in vocabulary size. For example, one verb can have as many as 19 surface varieties. In this research, we focus on predicate conjugation for compressing the vocabulary size in Japanese. The vocabulary list is filled with the various forms of verbs. We propose methods using predicate conjugation information without discarding linguistic information. The proposed methods can generate low-frequency words and deal with unknown words. Two methods were considered to introduce conjugation information: the first considers it as a token (conjugation token) and the second considers it as an embedded vector (conjugation feature). The results using these methods demonstrate that the vocabulary size can be compressed by approximately 86.1% (Tanaka corpus) and the NMT models can output the words not in the training data set. Furthermore, BLEU scores improved by 0.91 points in Japanese-to-English translation, and 0.32 points in English-to-Japanese translation with ASPEC.