 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Context-aware Neural Machine Translation with Target-side Context
Sep 02, 2019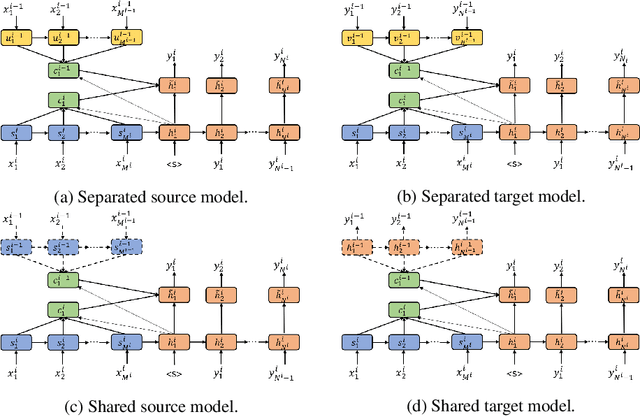
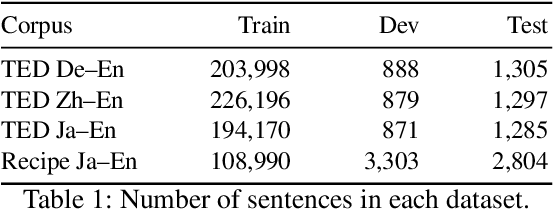
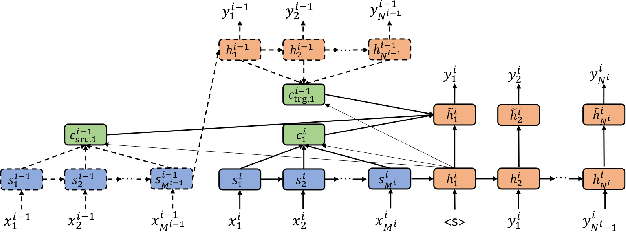
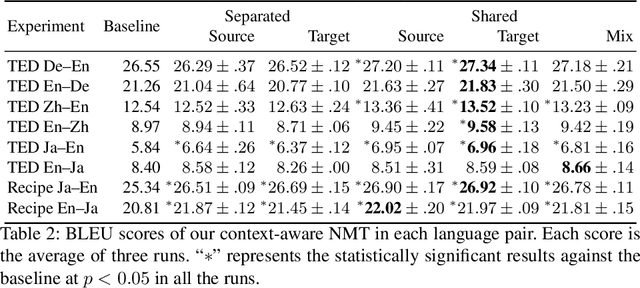
In recent years, several studies on neural machine translation (NMT) have attempted to use document-level context by using a multi-encoder and two attention mechanisms to read the current and previous sentences to incorporate the context of the previous sentences. These studies concluded that the target-side context is less useful than the source-side context. However, we considered that the reason why the target-side context is less useful lies in the architecture used to model these contexts. Therefore, in this study, we investigate how the target-side context can improve context-aware neural machine translation. We propose a weight sharing method wherein NMT saves decoder states and calculates an attention vector using the saved states when translating a current sentence. Our experiments show that the target-side context is also useful if we plug it into NMT as the decoder state when translating a previous sentence.
Multimodal Machine Translation with Embedding Prediction
Apr 01, 2019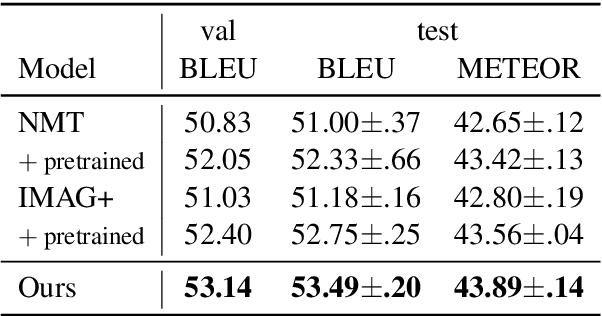
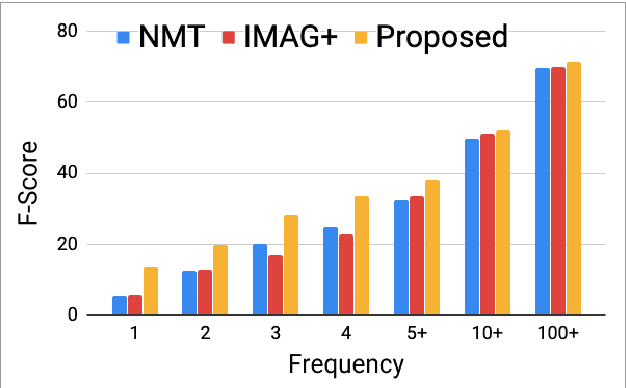
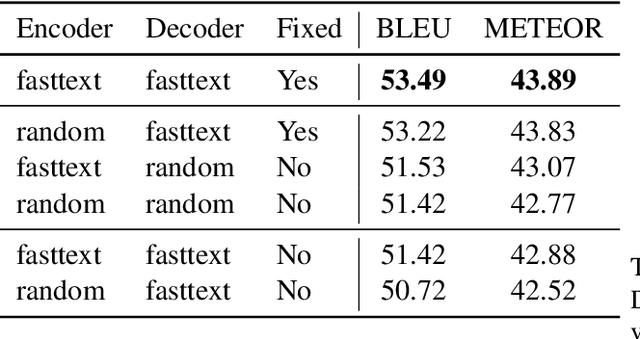
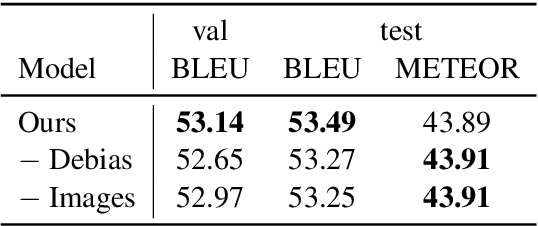
Multimodal machine translation is an attractive application of neural machine translation (NMT). It helps computers to deeply understand visual objects and their relations with natural languages. However, multimodal NMT systems suffer from a shortage of available training data, resulting in poor performance for translating rare words. In NMT, pretrained word embeddings have been shown to improve NMT of low-resource domains, and a search-based approach is proposed to address the rare word problem. In this study, we effectively combine these two approaches in the context of multimodal NMT and explore how we can take full advantage of pretrained word embeddings to better translate rare words. We report overall performance improvements of 1.24 METEOR and 2.49 BLEU and achieve an improvement of 7.67 F-score for rare word translation.
Graph-based Filtering of Out-of-Vocabulary Words for Encoder-Decoder Models
May 28, 2018



Encoder-decoder models typically only employ words that are frequently used in the training corpus to reduce the computational costs and exclude noise. However, this vocabulary set may still include words that interfere with learning in encoder-decoder models. This paper proposes a method for selecting more suitable words for learning encoders by utilizing not only frequency, but also co-occurrence information, which we capture using the HITS algorithm. We apply our proposed method to two tasks: machine translation and grammatical error correction. For Japanese-to-English translation, this method achieves a BLEU score that is 0.56 points more than that of a baseline. It also outperforms the baseline method for English grammatical error correction, with an F0.5-measure that is 1.48 points higher.
Japanese Predicate Conjugation for Neural Machine Translation
May 25, 2018

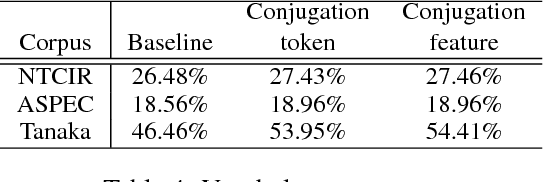
Neural machine translation (NMT) has a drawback in that can generate only high-frequency words owing to the computational costs of the softmax function in the output layer. In Japanese-English NMT, Japanese predicate conjugation causes an increase in vocabulary size. For example, one verb can have as many as 19 surface varieties. In this research, we focus on predicate conjugation for compressing the vocabulary size in Japanese. The vocabulary list is filled with the various forms of verbs. We propose methods using predicate conjugation information without discarding linguistic information. The proposed methods can generate low-frequency words and deal with unknown words. Two methods were considered to introduce conjugation information: the first considers it as a token (conjugation token) and the second considers it as an embedded vector (conjugation feature). The results using these methods demonstrate that the vocabulary size can be compressed by approximately 86.1% (Tanaka corpus) and the NMT models can output the words not in the training data set. Furthermore, BLEU scores improved by 0.91 points in Japanese-to-English translation, and 0.32 points in English-to-Japanese translation with ASPEC.