 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Context-aware Neural Machine Translation with Target-side Context
Paper and Code
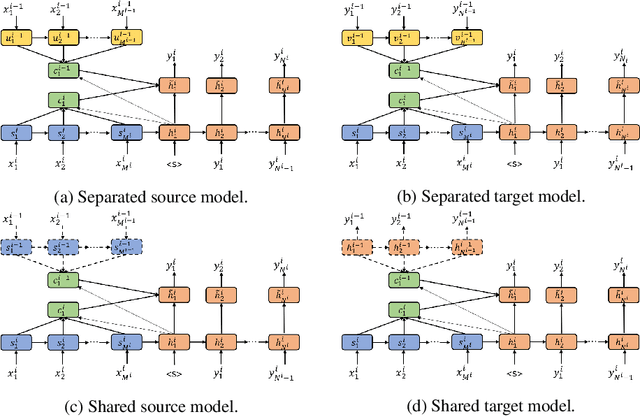
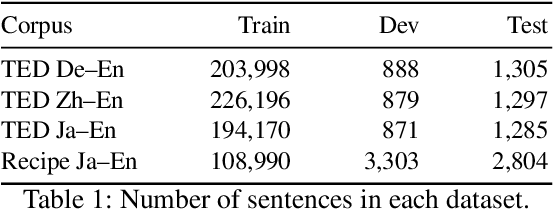
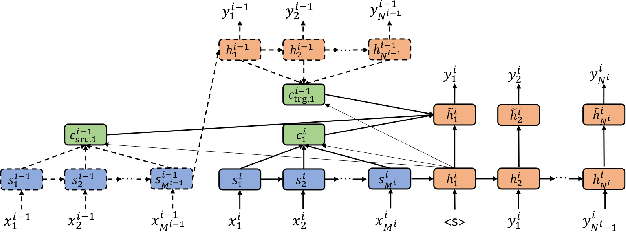
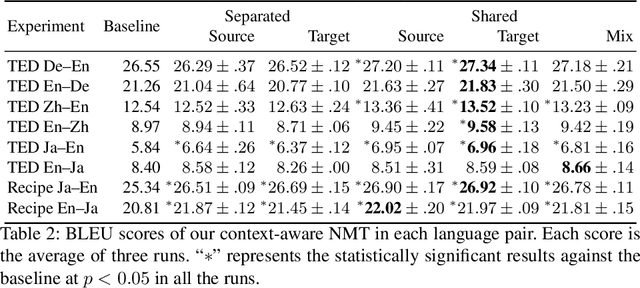
In recent years, several studies on neural machine translation (NMT) have attempted to use document-level context by using a multi-encoder and two attention mechanisms to read the current and previous sentences to incorporate the context of the previous sentences. These studies concluded that the target-side context is less useful than the source-side context. However, we considered that the reason why the target-side context is less useful lies in the architecture used to model these contexts. Therefore, in this study, we investigate how the target-side context can improve context-aware neural machine translation. We propose a weight sharing method wherein NMT saves decoder states and calculates an attention vector using the saved states when translating a current sentence. Our experiments show that the target-side context is also useful if we plug it into NMT as the decoder state when translating a previous sentence.