 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtterance-Wise Meeting Transcription System Using Asynchronous Distributed Microphones
Paper and Code
Jul 31, 2020
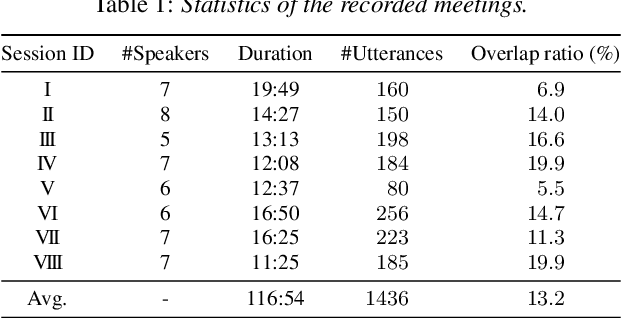
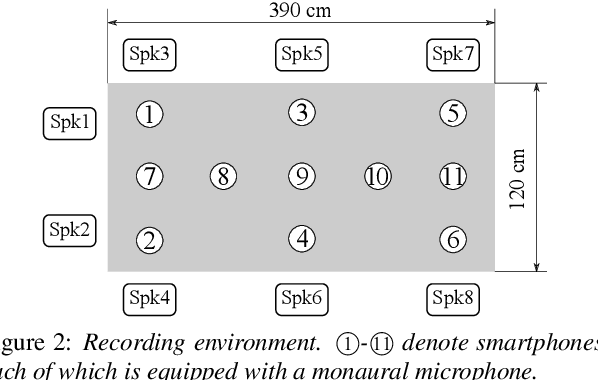
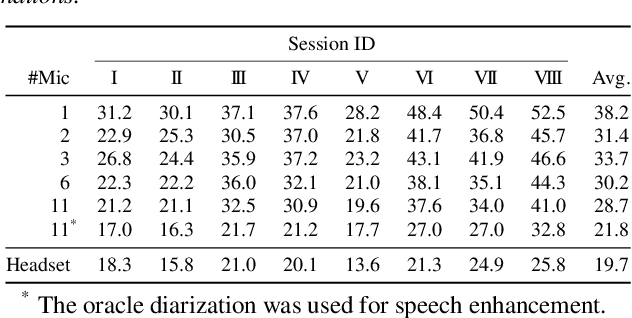
A novel framework for meeting transcription using asynchronous microphones is proposed in this paper. It consists of audio synchronization, speaker diarization, utterance-wise speech enhancement using guided source separation, automatic speech recognition, and duplication reduction. Doing speaker diarization before speech enhancement enables the system to deal with overlapped speech without considering sampling frequency mismatch between microphones. Evaluation on our real meeting datasets showed that our framework achieved a character error rate (CER) of 28.7 % by using 11 distributed microphones, while a monaural microphone placed on the center of the table had a CER of 38.2 %. We also showed that our framework achieved CER of 21.8 %, which is only 2.1 percentage points higher than the CER in headset microphone-based transcription.