Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Multi lingual TTS using Cross Lingual Voice Conversion
Paper and Code
Dec 28, 2020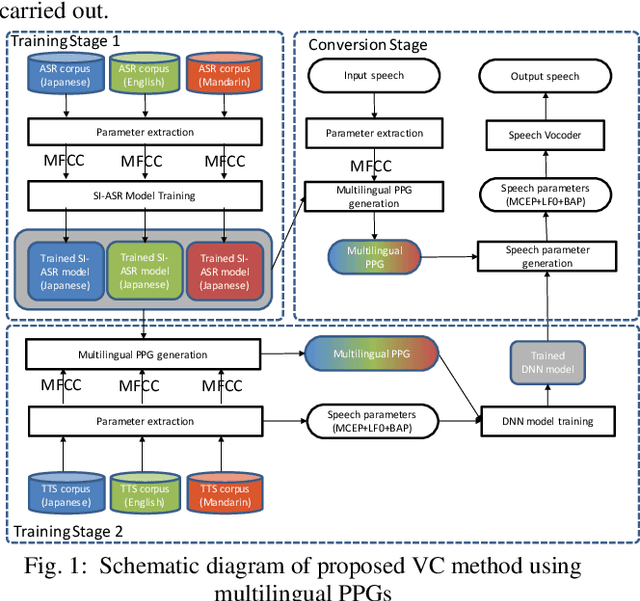
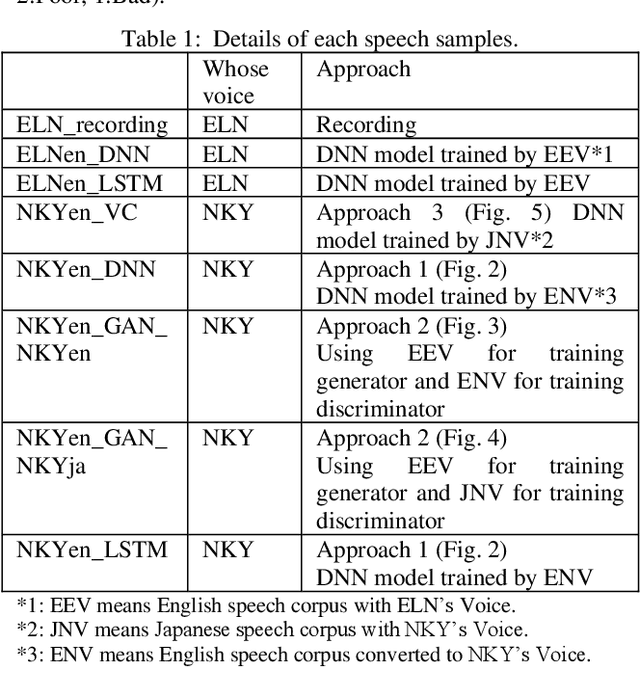
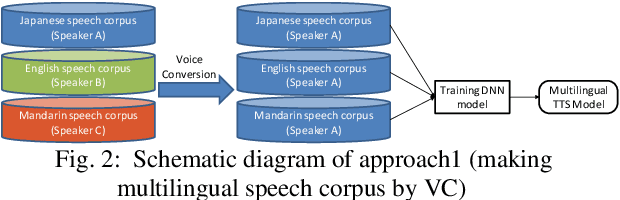
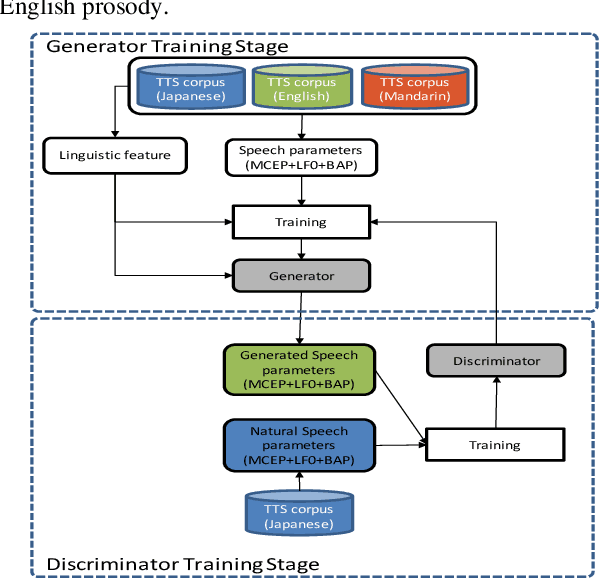
In this paper we propose a new cross-lingual Voice Conversion (VC) approach which can generate all speech parameters (MCEP, LF0, BAP) from one DNN model using PPGs (Phonetic PosteriorGrams) extracted from inputted speech using several ASR acoustic models. Using the proposed VC method, we tried three different approaches to build a multilingual TTS system without recording a multilingual speech corpus. A listening test was carried out to evaluate both speech quality (naturalness) and voice similarity between converted speech and target speech. The results show that Approach 1 achieved the highest level of naturalness (3.28 MOS on a 5-point scale) and similarity (2.77 MOS).
View paper on