 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotional Speech Synthesis for Companion Robot to Imitate Professional Caregiver Speech
Sep 27, 2021
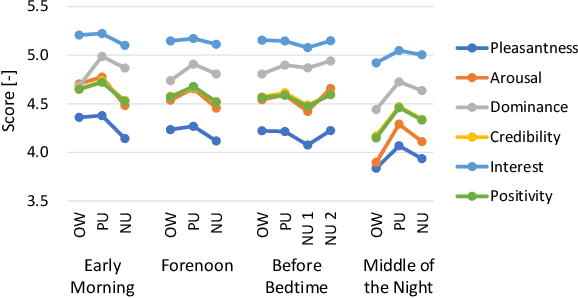


When people try to influence others to do something, they subconsciously adjust their speech to include appropriate emotional information. In order for a robot to influence people in the same way, the robot should be able to imitate the range of human emotions when speaking. To achieve this, we propose a speech synthesis method for imitating the emotional states in human speech. In contrast to previous methods, the advantage of our method is that it requires less manual effort to adjust the emotion of the synthesized speech. Our synthesizer receives an emotion vector to characterize the emotion of synthesized speech. The vector is automatically obtained from human utterances by using a speech emotion recognizer. We evaluated our method in a scenario when a robot tries to regulate an elderly person's circadian rhythm by speaking to the person using appropriate emotional states. For the target speech to imitate, we collected utterances from professional caregivers when they speak to elderly people at different times of the day. Then we conducted a subjective evaluation where the elderly participants listened to the speech samples generated by our method. The results showed that listening to the samples made the participants feel more active in the early morning and calmer in the middle of the night. This suggests that the robot may be able to adjust the participants' circadian rhythm and that the robot can potentially exert influence similarly to a person.
Building Multi lingual TTS using Cross Lingual Voice Conversion
Dec 28, 2020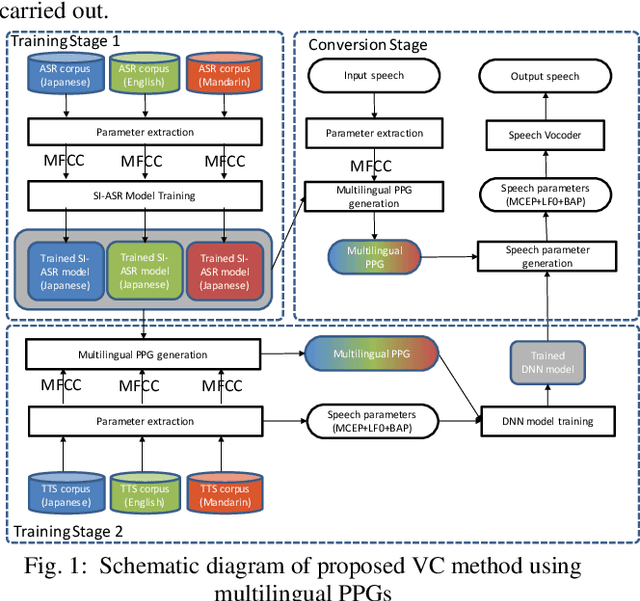
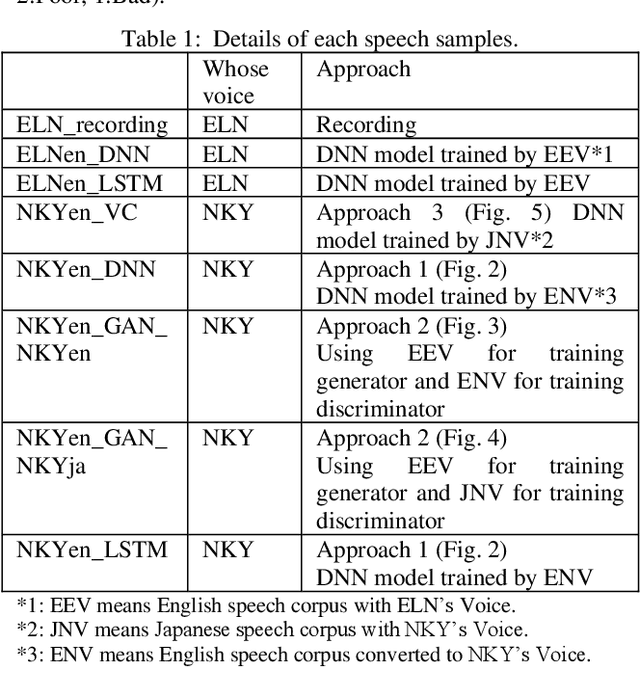
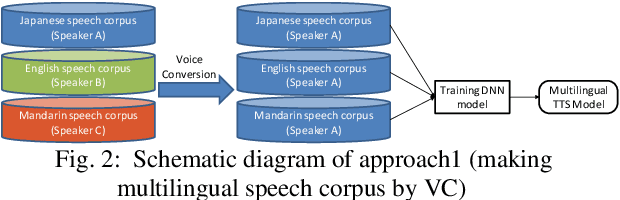
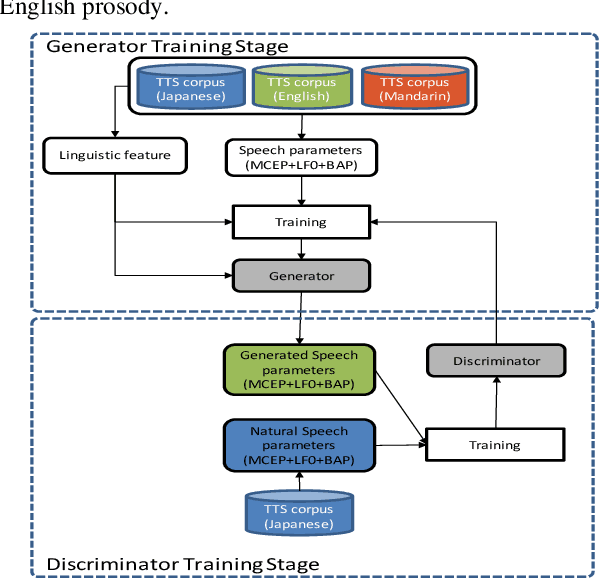
In this paper we propose a new cross-lingual Voice Conversion (VC) approach which can generate all speech parameters (MCEP, LF0, BAP) from one DNN model using PPGs (Phonetic PosteriorGrams) extracted from inputted speech using several ASR acoustic models. Using the proposed VC method, we tried three different approaches to build a multilingual TTS system without recording a multilingual speech corpus. A listening test was carried out to evaluate both speech quality (naturalness) and voice similarity between converted speech and target speech. The results show that Approach 1 achieved the highest level of naturalness (3.28 MOS on a 5-point scale) and similarity (2.77 MOS).