 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Naturalness of Simulated Conversations for End-to-End Neural Diarization
Paper and Code
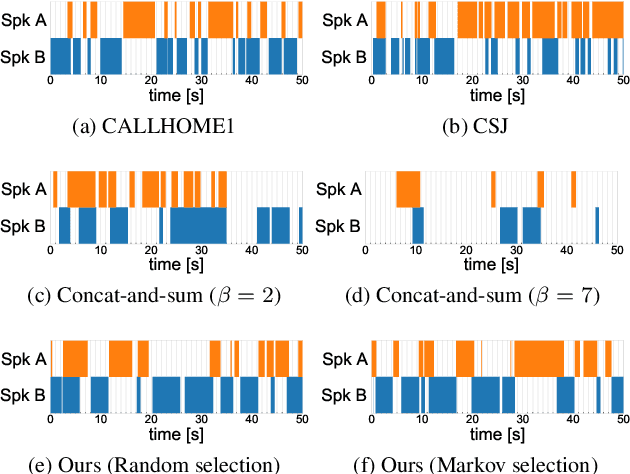
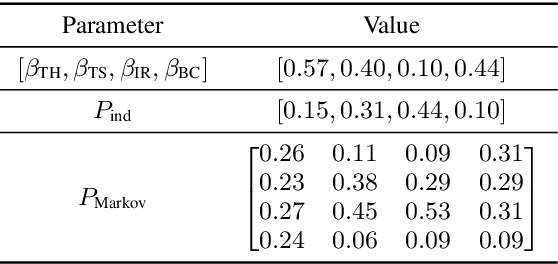
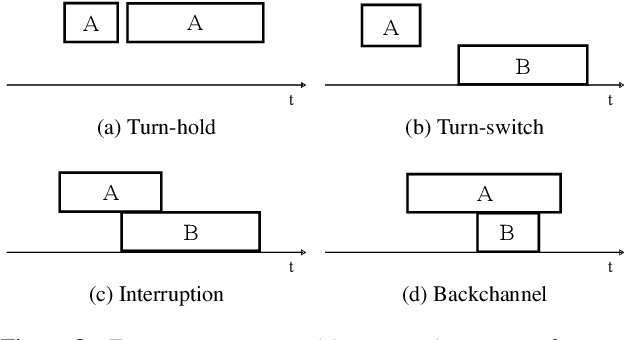
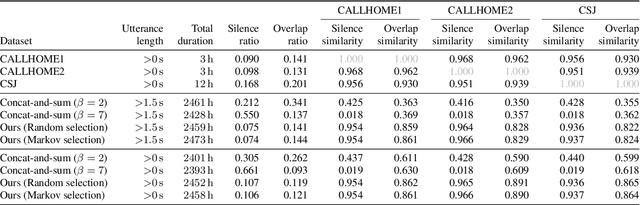
This paper investigates a method for simulating natural conversation in the model training of end-to-end neural diarization (EEND). Due to the lack of any annotated real conversational dataset, EEND is usually pretrained on a large-scale simulated conversational dataset first and then adapted to the target real dataset. Simulated datasets play an essential role in the training of EEND, but as yet there has been insufficient investigation into an optimal simulation method. We thus propose a method to simulate natural conversational speech. In contrast to conventional methods, which simply combine the speech of multiple speakers, our method takes turn-taking into account. We define four types of speaker transition and sequentially arrange them to simulate natural conversations. The dataset simulated using our method was found to be statistically similar to the real dataset in terms of the silence and overlap ratios. The experimental results on two-speaker diarization using the CALLHOME and CSJ datasets showed that the simulated dataset contributes to improving the performance of EEND.