 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Integration of Speech Emotion Recognition with Voice Activity Detection using Self-Supervised Learning Features
Paper and Code
Oct 17, 2024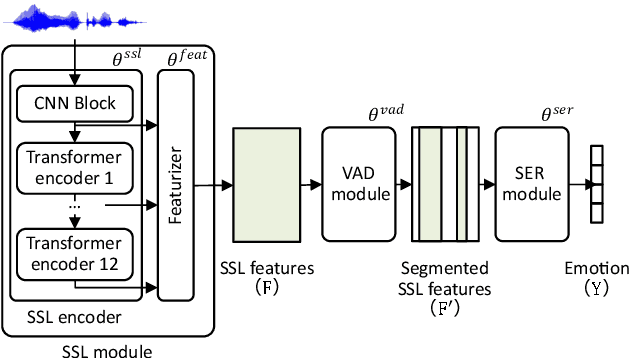
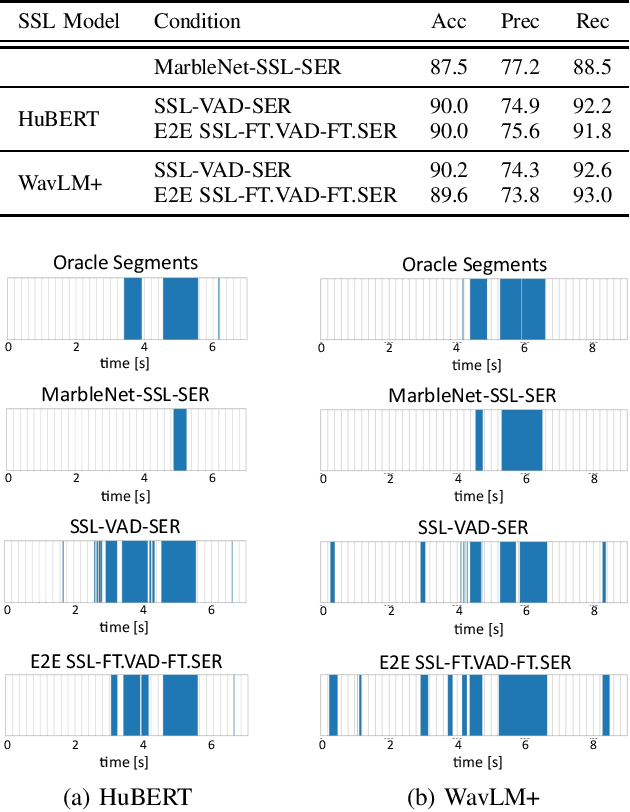
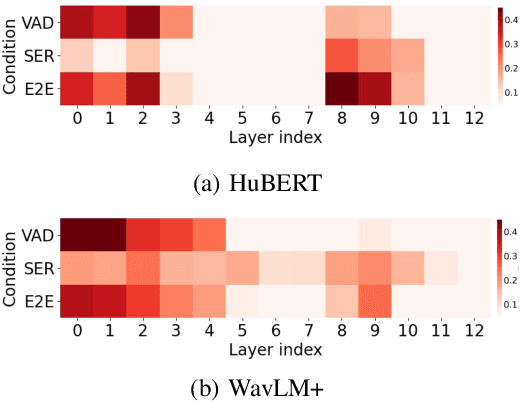
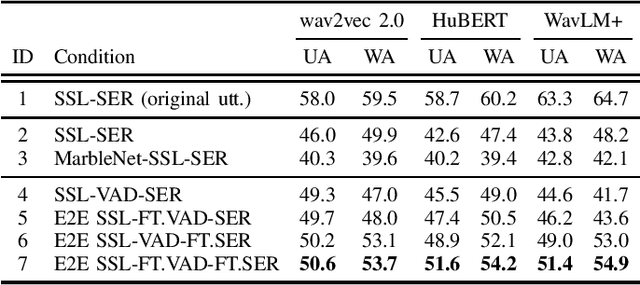
Speech Emotion Recognition (SER) often operates on speech segments detected by a Voice Activity Detection (VAD) model. However, VAD models may output flawed speech segments, especially in noisy environments, resulting in degraded performance of subsequent SER models. To address this issue, we propose an end-to-end (E2E) method that integrates VAD and SER using Self-Supervised Learning (SSL) features. The VAD module first receives the SSL features as input, and the segmented SSL features are then fed into the SER module. Both the VAD and SER modules are jointly trained to optimize SER performance. Experimental results on the IEMOCAP dataset demonstrate that our proposed method improves SER performance. Furthermore, to investigate the effect of our proposed method on the VAD and SSL modules, we present an analysis of the VAD outputs and the weights of each layer of the SSL encoder.