 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLaSP: Learning Concepts for Time-Series Signals from Natural Language Supervision
Nov 13, 2024This paper proposes a foundation model called "CLaSP" that can search time series signals using natural language that describes the characteristics of the signals as queries. Previous efforts to represent time series signal data in natural language have had challenges in designing a conventional class of time series signal characteristics, formulating their quantification, and creating a dictionary of synonyms. To overcome these limitations, the proposed method introduces a neural network based on contrastive learning. This network is first trained using the datasets TRUCE and SUSHI, which consist of time series signals and their corresponding natural language descriptions. Previous studies have proposed vocabularies that data analysts use to describe signal characteristics, and SUSHI was designed to cover these terms. We believe that a neural network trained on these datasets will enable data analysts to search using natural language vocabulary. Furthermore, our method does not require a dictionary of predefined synonyms, and it leverages common sense knowledge embedded in a large-scale language model (LLM). Experimental results demonstrate that CLaSP enables natural language search of time series signal data and can accurately learn the points at which signal data changes.
Domain-Independent Automatic Generation of Descriptive Texts for Time-Series Data
Sep 25, 2024



Due to scarcity of time-series data annotated with descriptive texts, training a model to generate descriptive texts for time-series data is challenging. In this study, we propose a method to systematically generate domain-independent descriptive texts from time-series data. We identify two distinct approaches for creating pairs of time-series data and descriptive texts: the forward approach and the backward approach. By implementing the novel backward approach, we create the Temporal Automated Captions for Observations (TACO) dataset. Experimental results demonstrate that a contrastive learning based model trained using the TACO dataset is capable of generating descriptive texts for time-series data in novel domains.
Spoofing Attacker Also Benefits from Self-Supervised Pretrained Model
May 24, 2023

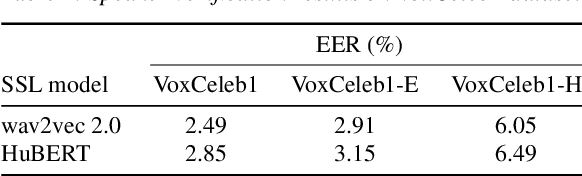

Large-scale pretrained models using self-supervised learning have reportedly improved the performance of speech anti-spoofing. However, the attacker side may also make use of such models. Also, since it is very expensive to train such models from scratch, pretrained models on the Internet are often used, but the attacker and defender may possibly use the same pretrained model. This paper investigates whether the improvement in anti-spoofing with pretrained models holds under the condition that the models are available to attackers. As the attacker, we train a model that enhances spoofed utterances so that the speaker embedding extractor based on the pretrained models cannot distinguish between bona fide and spoofed utterances. Experimental results show that the gains the anti-spoofing models obtained by using the pretrained models almost disappear if the attacker also makes use of the pretrained models.