 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Surveys to Narratives: Rethinking Cultural Value Adaptation in LLMs
May 22, 2025Adapting cultural values in Large Language Models (LLMs) presents significant challenges, particularly due to biases and limited training data. Prior work primarily aligns LLMs with different cultural values using World Values Survey (WVS) data. However, it remains unclear whether this approach effectively captures cultural nuances or produces distinct cultural representations for various downstream tasks. In this paper, we systematically investigate WVS-based training for cultural value adaptation and find that relying solely on survey data can homogenize cultural norms and interfere with factual knowledge. To investigate these issues, we augment WVS with encyclopedic and scenario-based cultural narratives from Wikipedia and NormAd. While these narratives may have variable effects on downstream tasks, they consistently improve cultural distinctiveness than survey data alone. Our work highlights the inherent complexity of aligning cultural values with the goal of guiding task-specific behavior.
NusaAksara: A Multimodal and Multilingual Benchmark for Preserving Indonesian Indigenous Scripts
Feb 25, 2025



Indonesia is rich in languages and scripts. However, most NLP progress has been made using romanized text. In this paper, we present NusaAksara, a novel public benchmark for Indonesian languages that includes their original scripts. Our benchmark covers both text and image modalities and encompasses diverse tasks such as image segmentation, OCR, transliteration, translation, and language identification. Our data is constructed by human experts through rigorous steps. NusaAksara covers 8 scripts across 7 languages, including low-resource languages not commonly seen in NLP benchmarks. Although unsupported by Unicode, the Lampung script is included in this dataset. We benchmark our data across several models, from LLMs and VLMs such as GPT-4o, Llama 3.2, and Aya 23 to task-specific systems such as PP-OCR and LangID, and show that most NLP technologies cannot handle Indonesia's local scripts, with many achieving near-zero performance.
QLESS: A Quantized Approach for Data Valuation and Selection in Large Language Model Fine-Tuning
Feb 03, 2025Fine-tuning large language models (LLMs) is often constrained by the computational costs of processing massive datasets. We propose \textbf{QLESS} (Quantized Low-rank Gradient Similarity Search), which integrates gradient quantization with the LESS framework to enable memory-efficient data valuation and selection. QLESS employs a two-step compression process: first, it obtains low-dimensional gradient representations through LoRA-based random projection; then, it quantizes these gradients to low-bitwidth representations. Experiments on multiple LLM architectures (LLaMA, Mistral, Qwen) and benchmarks (MMLU, BBH, TyDiQA) show that QLESS achieves comparable data selection performance to LESS while reducing memory usage by up to 16x. Even 1-bit gradient quantization preserves data valuation quality. These findings underscore QLESS as a practical, scalable approach to identifying informative examples within strict memory constraints.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
Cultural Conditioning or Placebo? On the Effectiveness of Socio-Demographic Prompting
Jun 17, 2024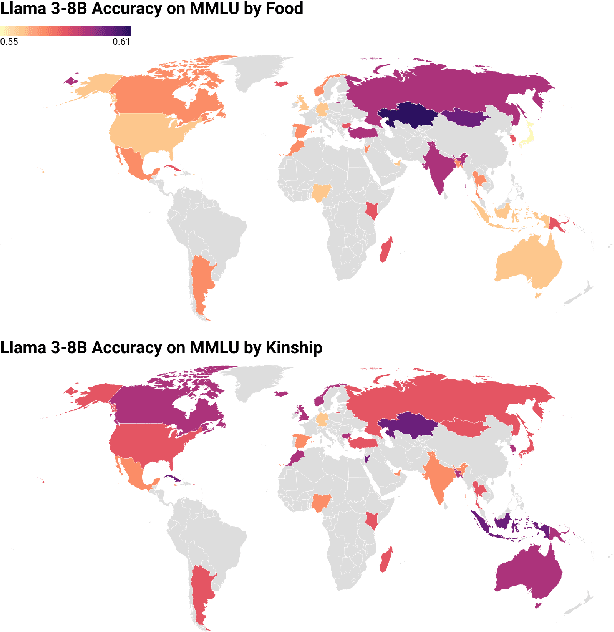

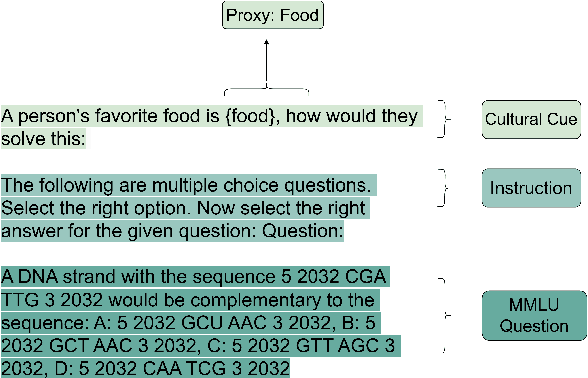
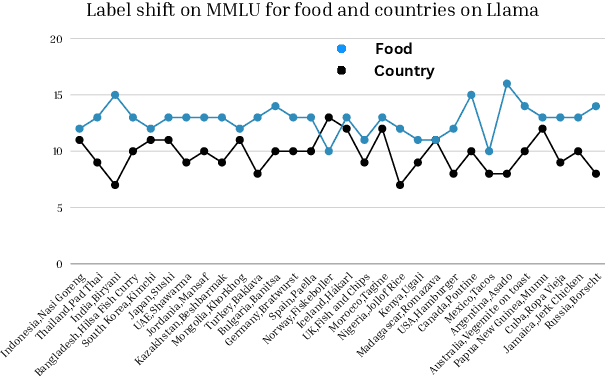
Socio-demographic prompting is a commonly employed approach to study cultural biases in LLMs as well as for aligning models to certain cultures. In this paper, we systematically probe four LLMs (Llama 3, Mistral v0.2, GPT-3.5 Turbo and GPT-4) with prompts that are conditioned on culturally sensitive and non-sensitive cues, on datasets that are supposed to be culturally sensitive (EtiCor and CALI) or neutral (MMLU and ETHICS). We observe that all models except GPT-4 show significant variations in their responses on both kinds of datasets for both kinds of prompts, casting doubt on the robustness of the culturally-conditioned prompting as a method for eliciting cultural bias in models or as an alignment strategy. The work also calls rethinking the control experiment design to tease apart the cultural conditioning of responses from "placebo effect", i.e., random perturbations of model responses due to arbitrary tokens in the prompt.
MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
Jun 16, 2024



Auto-regressive inference of transformers benefit greatly from Key-Value (KV) caching, but can lead to major memory bottlenecks as model size, batch size, and sequence length grow at scale. We introduce Multi-Layer Key-Value (MLKV) sharing, a novel approach extending KV sharing across transformer layers to reduce memory usage beyond what was possible with Multi-Query Attention (MQA) and Grouped-Query Attention (GQA). Evaluations on various NLP benchmarks and inference metrics using uptrained Pythia-160M variants demonstrate that MLKV significantly reduces memory usage with minimal performance loss, reducing KV cache size down to a factor of 6x compared to MQA. These results highlight MLKV's potential for efficient deployment of transformer models at scale. We provide code at https://github.com/zaydzuhri/pythia-mlkv
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024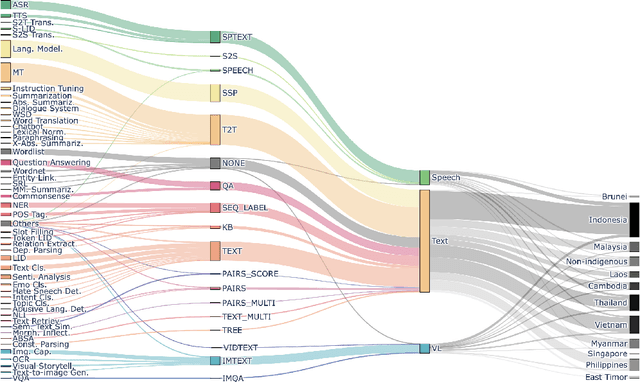
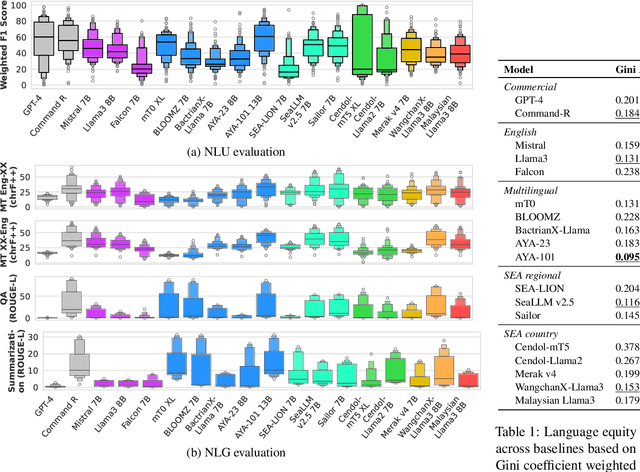
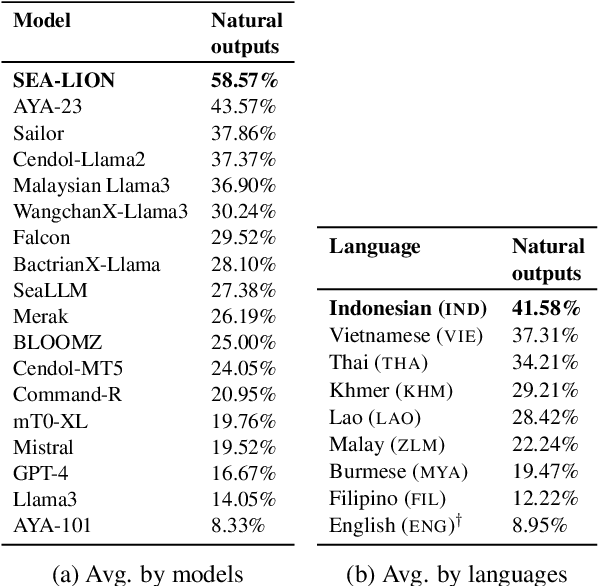
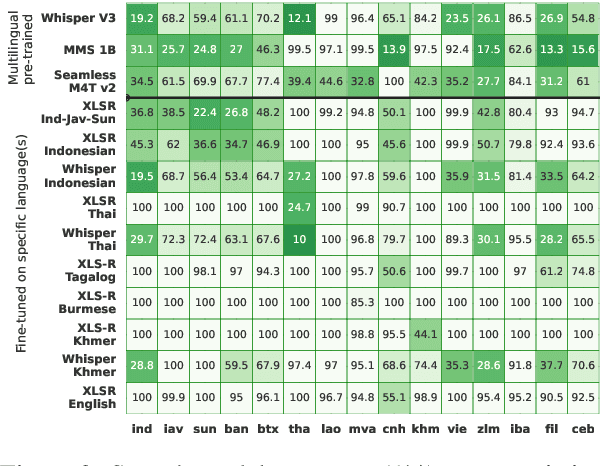
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
LinguAlchemy: Fusing Typological and Geographical Elements for Unseen Language Generalization
Feb 01, 2024

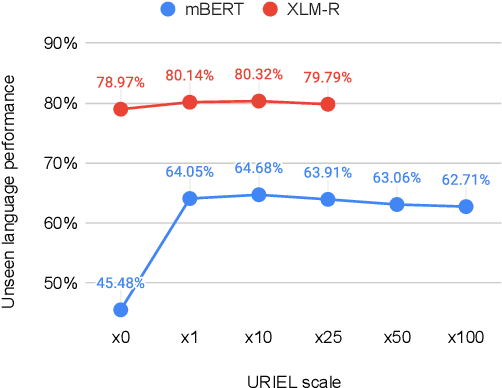
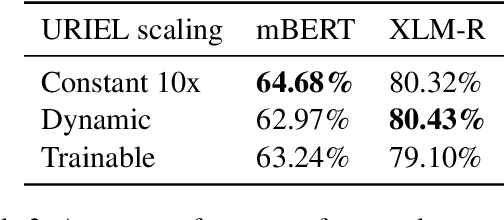
Pretrained language models (PLMs) have shown remarkable generalization toward multiple tasks and languages. Nonetheless, the generalization of PLMs towards unseen languages is poor, resulting in significantly worse language performance, or even generating nonsensical responses that are comparable to a random baseline. This limitation has been a longstanding problem of PLMs raising the problem of diversity and equal access to language modeling technology. In this work, we solve this limitation by introducing LinguAlchemy, a regularization technique that incorporates various aspects of languages covering typological, geographical, and phylogenetic constraining the resulting representation of PLMs to better characterize the corresponding linguistics constraints. LinguAlchemy significantly improves the accuracy performance of mBERT and XLM-R on unseen languages by ~18% and ~2%, respectively compared to fully finetuned models and displaying a high degree of unseen language generalization. We further introduce AlchemyScale and AlchemyTune, extension of LinguAlchemy which adjusts the linguistic regularization weights automatically, alleviating the need for hyperparameter search. LinguAlchemy enables better cross-lingual generalization to unseen languages which is vital for better inclusivity and accessibility of PLMs.
Beyond Turing: A Comparative Analysis of Approaches for Detecting Machine-Generated Text
Nov 21, 2023


Significant progress has been made on text generation by pre-trained language models (PLMs), yet distinguishing between human and machine-generated text poses an escalating challenge. This paper offers an in-depth evaluation of three distinct methods used to address this task: traditional shallow learning, Language Model (LM) fine-tuning, and Multilingual Model fine-tuning. These approaches are rigorously tested on a wide range of machine-generated texts, providing a benchmark of their competence in distinguishing between human-authored and machine-authored linguistic constructs. The results reveal considerable differences in performance across methods, thus emphasizing the continued need for advancement in this crucial area of NLP. This study offers valuable insights and paves the way for future research aimed at creating robust and highly discriminative models.