 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting LLM Correctness in Prosthodontics Using Metadata and Hallucination Signals
Dec 27, 2025Large language models (LLMs) are increasingly adopted in high-stakes domains such as healthcare and medical education, where the risk of generating factually incorrect (i.e., hallucinated) information is a major concern. While significant efforts have been made to detect and mitigate such hallucinations, predicting whether an LLM's response is correct remains a critical yet underexplored problem. This study investigates the feasibility of predicting correctness by analyzing a general-purpose model (GPT-4o) and a reasoning-centric model (OSS-120B) on a multiple-choice prosthodontics exam. We utilize metadata and hallucination signals across three distinct prompting strategies to build a correctness predictor for each (model, prompting) pair. Our findings demonstrate that this metadata-based approach can improve accuracy by up to +7.14% and achieve a precision of 83.12% over a baseline that assumes all answers are correct. We further show that while actual hallucination is a strong indicator of incorrectness, metadata signals alone are not reliable predictors of hallucination. Finally, we reveal that prompting strategies, despite not affecting overall accuracy, significantly alter the models' internal behaviors and the predictive utility of their metadata. These results present a promising direction for developing reliability signals in LLMs but also highlight that the methods explored in this paper are not yet robust enough for critical, high-stakes deployment.
What Do Indonesians Really Need from Language Technology? A Nationwide Survey
Jun 09, 2025



There is an emerging effort to develop NLP for Indonesias 700+ local languages, but progress remains costly due to the need for direct engagement with native speakers. However, it is unclear what these language communities truly need from language technology. To address this, we conduct a nationwide survey to assess the actual needs of native speakers in Indonesia. Our findings indicate that addressing language barriers, particularly through machine translation and information retrieval, is the most critical priority. Although there is strong enthusiasm for advancements in language technology, concerns around privacy, bias, and the use of public data for AI training highlight the need for greater transparency and clear communication to support broader AI adoption.
NusaAksara: A Multimodal and Multilingual Benchmark for Preserving Indonesian Indigenous Scripts
Feb 25, 2025



Indonesia is rich in languages and scripts. However, most NLP progress has been made using romanized text. In this paper, we present NusaAksara, a novel public benchmark for Indonesian languages that includes their original scripts. Our benchmark covers both text and image modalities and encompasses diverse tasks such as image segmentation, OCR, transliteration, translation, and language identification. Our data is constructed by human experts through rigorous steps. NusaAksara covers 8 scripts across 7 languages, including low-resource languages not commonly seen in NLP benchmarks. Although unsupported by Unicode, the Lampung script is included in this dataset. We benchmark our data across several models, from LLMs and VLMs such as GPT-4o, Llama 3.2, and Aya 23 to task-specific systems such as PP-OCR and LangID, and show that most NLP technologies cannot handle Indonesia's local scripts, with many achieving near-zero performance.
MetaMetrics-MT: Tuning Meta-Metrics for Machine Translation via Human Preference Calibration
Nov 01, 2024We present MetaMetrics-MT, an innovative metric designed to evaluate machine translation (MT) tasks by aligning closely with human preferences through Bayesian optimization with Gaussian Processes. MetaMetrics-MT enhances existing MT metrics by optimizing their correlation with human judgments. Our experiments on the WMT24 metric shared task dataset demonstrate that MetaMetrics-MT outperforms all existing baselines, setting a new benchmark for state-of-the-art performance in the reference-based setting. Furthermore, it achieves comparable results to leading metrics in the reference-free setting, offering greater efficiency.
WorldCuisines: A Massive-Scale Benchmark for Multilingual and Multicultural Visual Question Answering on Global Cuisines
Oct 16, 2024



Vision Language Models (VLMs) often struggle with culture-specific knowledge, particularly in languages other than English and in underrepresented cultural contexts. To evaluate their understanding of such knowledge, we introduce WorldCuisines, a massive-scale benchmark for multilingual and multicultural, visually grounded language understanding. This benchmark includes a visual question answering (VQA) dataset with text-image pairs across 30 languages and dialects, spanning 9 language families and featuring over 1 million data points, making it the largest multicultural VQA benchmark to date. It includes tasks for identifying dish names and their origins. We provide evaluation datasets in two sizes (12k and 60k instances) alongside a training dataset (1 million instances). Our findings show that while VLMs perform better with correct location context, they struggle with adversarial contexts and predicting specific regional cuisines and languages. To support future research, we release a knowledge base with annotated food entries and images along with the VQA data.
MetaMetrics: Calibrating Metrics For Generation Tasks Using Human Preferences
Oct 03, 2024Understanding the quality of a performance evaluation metric is crucial for ensuring that model outputs align with human preferences. However, it remains unclear how well each metric captures the diverse aspects of these preferences, as metrics often excel in one particular area but not across all dimensions. To address this, it is essential to systematically calibrate metrics to specific aspects of human preference, catering to the unique characteristics of each aspect. We introduce MetaMetrics, a calibrated meta-metric designed to evaluate generation tasks across different modalities in a supervised manner. MetaMetrics optimizes the combination of existing metrics to enhance their alignment with human preferences. Our metric demonstrates flexibility and effectiveness in both language and vision downstream tasks, showing significant benefits across various multilingual and multi-domain scenarios. MetaMetrics aligns closely with human preferences and is highly extendable and easily integrable into any application. This makes MetaMetrics a powerful tool for improving the evaluation of generation tasks, ensuring that metrics are more representative of human judgment across diverse contexts.
IndoToxic2024: A Demographically-Enriched Dataset of Hate Speech and Toxicity Types for Indonesian Language
Jun 27, 2024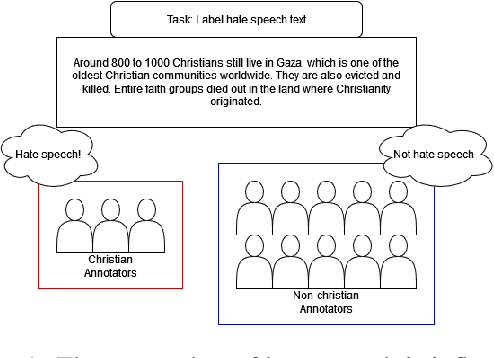



Hate speech poses a significant threat to social harmony. Over the past two years, Indonesia has seen a ten-fold increase in the online hate speech ratio, underscoring the urgent need for effective detection mechanisms. However, progress is hindered by the limited availability of labeled data for Indonesian texts. The condition is even worse for marginalized minorities, such as Shia, LGBTQ, and other ethnic minorities because hate speech is underreported and less understood by detection tools. Furthermore, the lack of accommodation for subjectivity in current datasets compounds this issue. To address this, we introduce IndoToxic2024, a comprehensive Indonesian hate speech and toxicity classification dataset. Comprising 43,692 entries annotated by 19 diverse individuals, the dataset focuses on texts targeting vulnerable groups in Indonesia, specifically during the hottest political event in the country: the presidential election. We establish baselines for seven binary classification tasks, achieving a macro-F1 score of 0.78 with a BERT model (IndoBERTweet) fine-tuned for hate speech classification. Furthermore, we demonstrate how incorporating demographic information can enhance the zero-shot performance of the large language model, gpt-3.5-turbo. However, we also caution that an overemphasis on demographic information can negatively impact the fine-tuned model performance due to data fragmentation.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024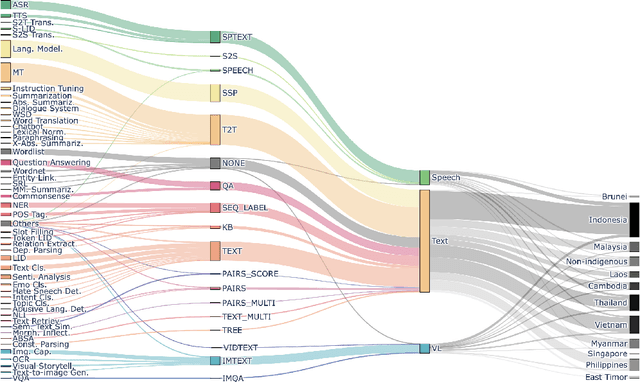
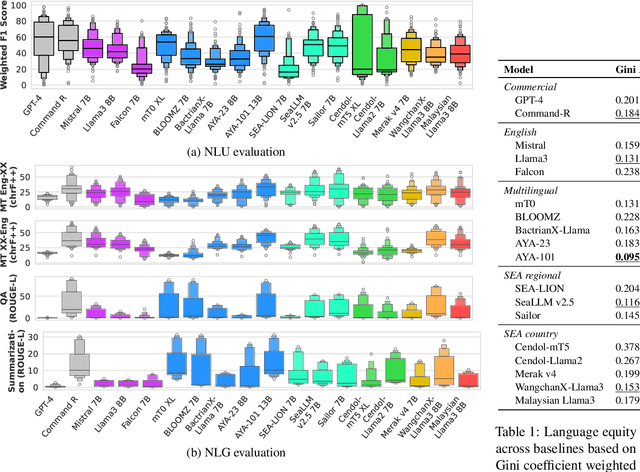
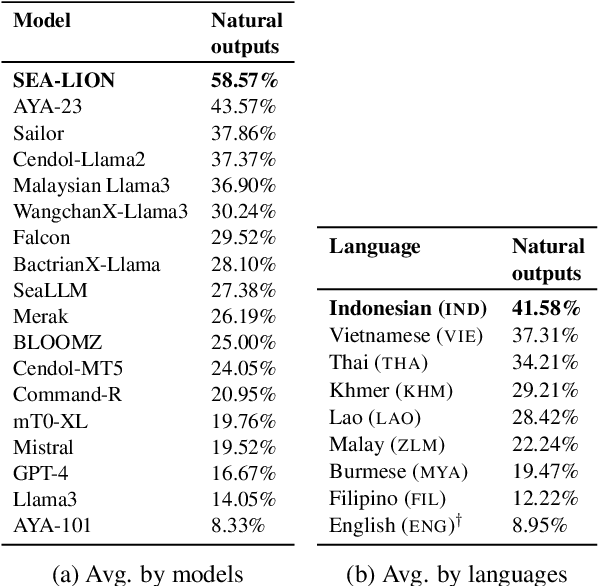
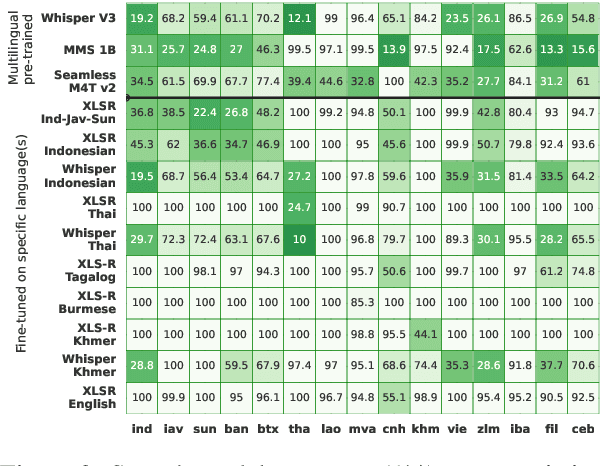
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.
What Linguistic Features and Languages are Important in LLM Translation?
Feb 21, 2024Large Language Models (LLMs) demonstrate strong capability across multiple tasks, including machine translation. Our study focuses on evaluating Llama2's machine translation capabilities and exploring how translation depends on languages in its training data. Our experiments show that the 7B Llama2 model yields above 10 BLEU score for all languages it has seen, but not always for languages it has not seen. Most gains for those unseen languages are observed the most with the model scale compared to using chat versions or adding shot count. Furthermore, our linguistic distance analysis reveals that syntactic similarity is not always the primary linguistic factor in determining translation quality. Interestingly, we discovered that under specific circumstances, some languages, despite having significantly less training data than English, exhibit strong correlations comparable to English. Our discoveries here give new perspectives for the current landscape of LLMs, raising the possibility that LLMs centered around languages other than English may offer a more effective foundation for a multilingual model.
Replicable Benchmarking of Neural Machine Translation (NMT) on Low-Resource Local Languages in Indonesia
Nov 02, 2023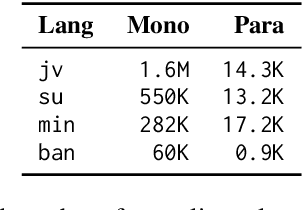
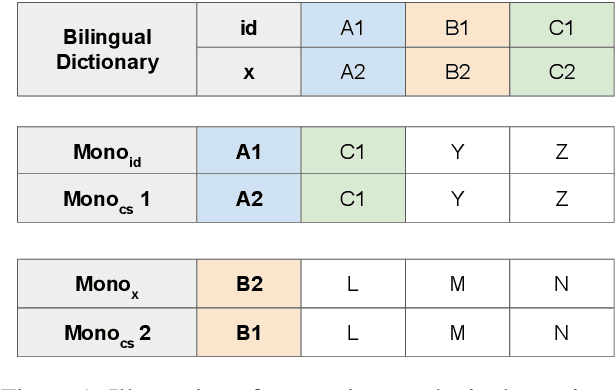
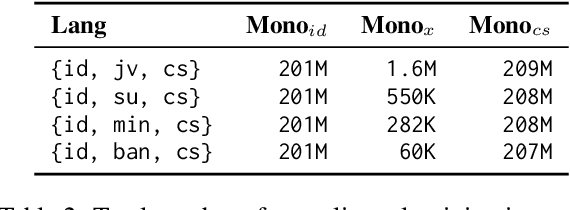
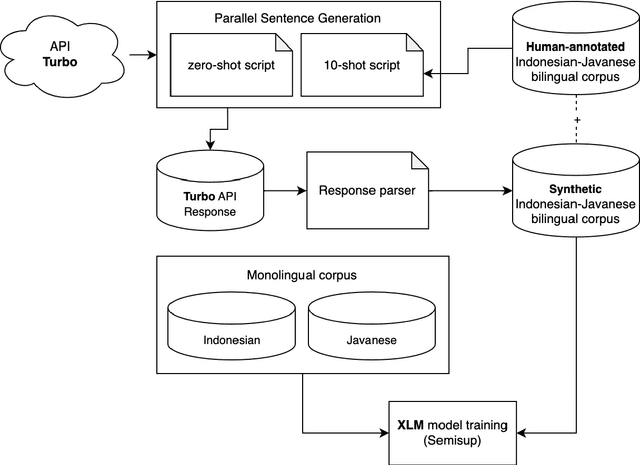
Neural machine translation (NMT) for low-resource local languages in Indonesia faces significant challenges, including the need for a representative benchmark and limited data availability. This work addresses these challenges by comprehensively analyzing training NMT systems for four low-resource local languages in Indonesia: Javanese, Sundanese, Minangkabau, and Balinese. Our study encompasses various training approaches, paradigms, data sizes, and a preliminary study into using large language models for synthetic low-resource languages parallel data generation. We reveal specific trends and insights into practical strategies for low-resource language translation. Our research demonstrates that despite limited computational resources and textual data, several of our NMT systems achieve competitive performances, rivaling the translation quality of zero-shot gpt-3.5-turbo. These findings significantly advance NMT for low-resource languages, offering valuable guidance for researchers in similar contexts.