 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyglot Teachers: Evaluating Language Models for Multilingual Synthetic Data Generation
Apr 13, 2026Synthesizing supervised finetuning (SFT) data from language models (LMs) to teach smaller models multilingual tasks has become increasingly common. However, teacher model selection is often ad hoc, typically defaulting to the largest available option, even though such models may have significant capability gaps in non-English languages. This practice can result in poor-quality synthetic data and suboptimal student downstream performance. In this work, we systematically characterize what makes an effective multilingual teacher. We measure intrinsic measures of data quality with extrinsic student model performance in a metric we call Polyglot Score; evaluating 10 LMs across 6 typologically diverse languages, generating over 1.4M SFT examples and training 240 student models. Among the models tested, Gemma 3 27B and Aya Expanse 32B emerge as consistently effective teachers across different student base model families. Further analyses reveal that model scale alone does not significantly predict teacher effectiveness; instead, data qualities such as prompt diversity, length, and response fluency capture over 93.3% of variance in intrinsic data quality and predict student performance. Finally, we provide practical recommendations, including matching the model families of teacher-student pairs and translating from or responding to existing prompts, which can yield improvements for less-resourced languages. We hope that our work advances data-centric research in multilingual synthetic data and LM development.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
The UD-NewsCrawl Treebank: Reflections and Challenges from a Large-scale Tagalog Syntactic Annotation Project
May 26, 2025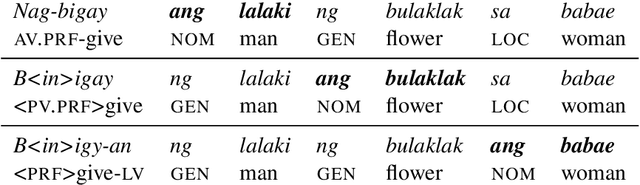

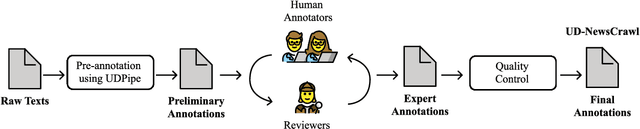
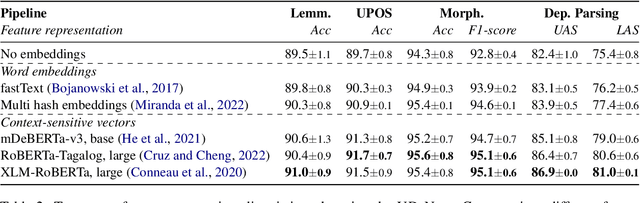
This paper presents UD-NewsCrawl, the largest Tagalog treebank to date, containing 15.6k trees manually annotated according to the Universal Dependencies framework. We detail our treebank development process, including data collection, pre-processing, manual annotation, and quality assurance procedures. We provide baseline evaluations using multiple transformer-based models to assess the performance of state-of-the-art dependency parsers on Tagalog. We also highlight challenges in the syntactic analysis of Tagalog given its distinctive grammatical properties, and discuss its implications for the annotation of this treebank. We anticipate that UD-NewsCrawl and our baseline model implementations will serve as valuable resources for advancing computational linguistics research in underrepresented languages like Tagalog.
R3: Robust Rubric-Agnostic Reward Models
May 19, 2025Reward models are essential for aligning language model outputs with human preferences, yet existing approaches often lack both controllability and interpretability. These models are typically optimized for narrow objectives, limiting their generalizability to broader downstream tasks. Moreover, their scalar outputs are difficult to interpret without contextual reasoning. To address these limitations, we introduce R3, a novel reward modeling framework that is rubric-agnostic, generalizable across evaluation dimensions, and provides interpretable, reasoned score assignments. R3 enables more transparent and flexible evaluation of language models, supporting robust alignment with diverse human values and use cases. Our models, data, and code are available as open source at https://github.com/rubricreward/r3
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024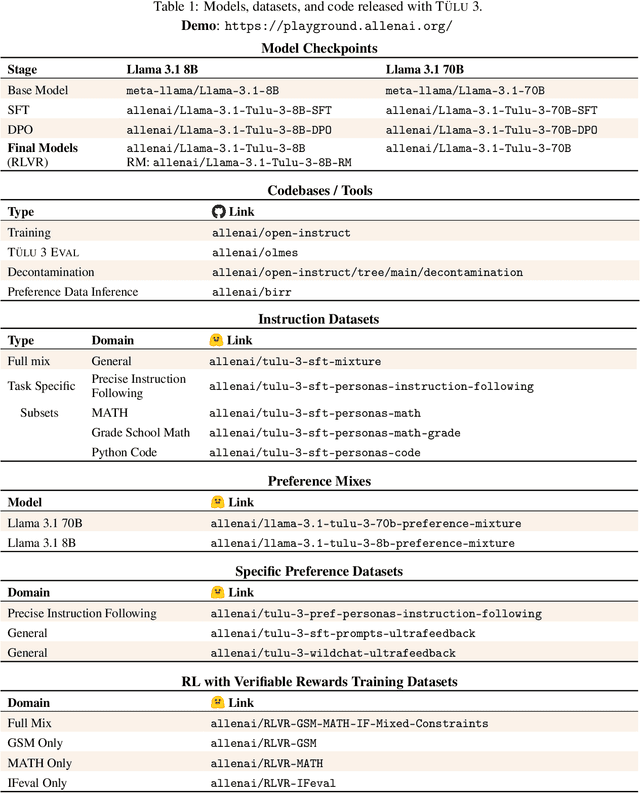



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
Oct 24, 2024



Learning from human feedback has enabled the alignment of language models (LMs) with human preferences. However, directly collecting human preferences can be expensive, time-consuming, and can have high variance. An appealing alternative is to distill preferences from LMs as a source of synthetic annotations as they are more consistent, cheaper, and scale better than human annotation; however, they are also prone to biases and errors. In this work, we introduce a routing framework that combines inputs from humans and LMs to achieve better annotation quality, while reducing the total cost of human annotation. The crux of our approach is to identify preference instances that will benefit from human annotations. We formulate this as an optimization problem: given a preference dataset and an evaluation metric, we train a performance prediction model to predict a reward model's performance on an arbitrary combination of human and LM annotations and employ a routing strategy that selects a combination that maximizes predicted performance. We train the performance prediction model on MultiPref, a new preference dataset with 10K instances paired with human and LM labels. We show that the selected hybrid mixture of LM and direct human preferences using our routing framework achieves better reward model performance compared to using either one exclusively. We simulate selective human preference collection on three other datasets and show that our method generalizes well to all three. We analyze features from the routing model to identify characteristics of instances that can benefit from human feedback, e.g., prompts with a moderate safety concern or moderate intent complexity. We release the dataset, annotation platform, and source code used in this study to foster more efficient and accurate preference collection in the future.
M-RewardBench: Evaluating Reward Models in Multilingual Settings
Oct 20, 2024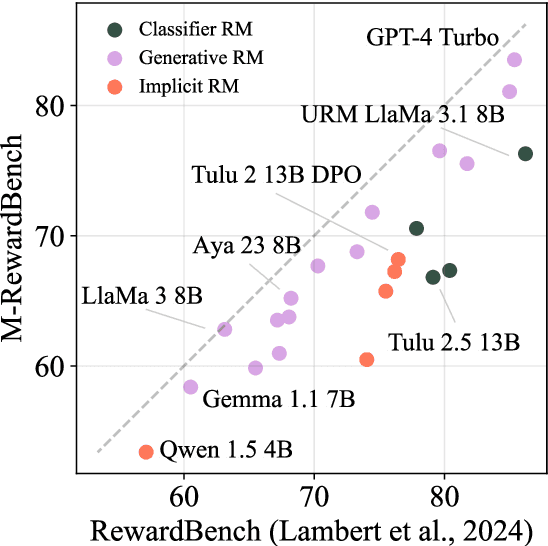



Reward models (RMs) have driven the state-of-the-art performance of LLMs today by enabling the integration of human feedback into the language modeling process. However, RMs are primarily trained and evaluated in English, and their capabilities in multilingual settings remain largely understudied. In this work, we conduct a systematic evaluation of several reward models in multilingual settings. We first construct the first-of-its-kind multilingual RM evaluation benchmark, M-RewardBench, consisting of 2.87k preference instances for 23 typologically diverse languages, that tests the chat, safety, reasoning, and translation capabilities of RMs. We then rigorously evaluate a wide range of reward models on M-RewardBench, offering fresh insights into their performance across diverse languages. We identify a significant gap in RMs' performances between English and non-English languages and show that RM preferences can change substantially from one language to another. We also present several findings on how different multilingual aspects impact RM performance. Specifically, we show that the performance of RMs is improved with improved translation quality. Similarly, we demonstrate that the models exhibit better performance for high-resource languages. We release M-RewardBench dataset and the codebase in this study to facilitate a better understanding of RM evaluation in multilingual settings.
SEACrowd: A Multilingual Multimodal Data Hub and Benchmark Suite for Southeast Asian Languages
Jun 14, 2024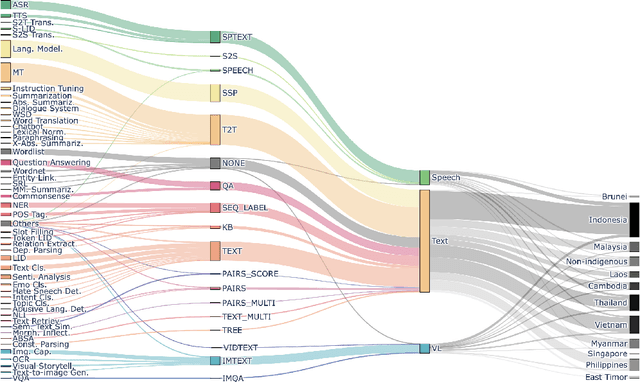
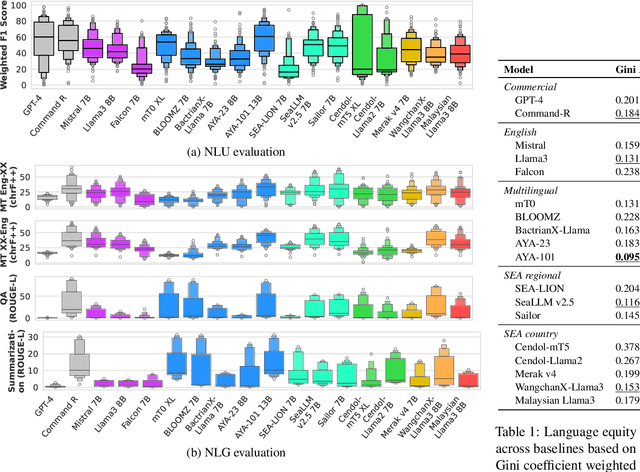
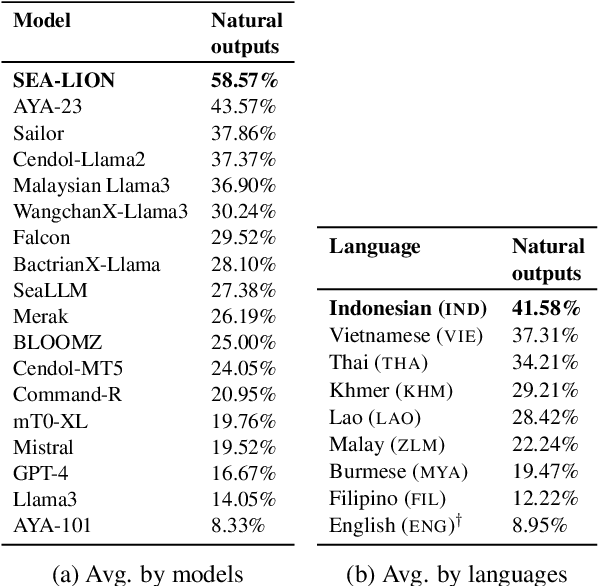
Southeast Asia (SEA) is a region rich in linguistic diversity and cultural variety, with over 1,300 indigenous languages and a population of 671 million people. However, prevailing AI models suffer from a significant lack of representation of texts, images, and audio datasets from SEA, compromising the quality of AI models for SEA languages. Evaluating models for SEA languages is challenging due to the scarcity of high-quality datasets, compounded by the dominance of English training data, raising concerns about potential cultural misrepresentation. To address these challenges, we introduce SEACrowd, a collaborative initiative that consolidates a comprehensive resource hub that fills the resource gap by providing standardized corpora in nearly 1,000 SEA languages across three modalities. Through our SEACrowd benchmarks, we assess the quality of AI models on 36 indigenous languages across 13 tasks, offering valuable insights into the current AI landscape in SEA. Furthermore, we propose strategies to facilitate greater AI advancements, maximizing potential utility and resource equity for the future of AI in SEA.