 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting LLM Reasoning with Dynamic Notes Writing for Complex QA
May 22, 2025

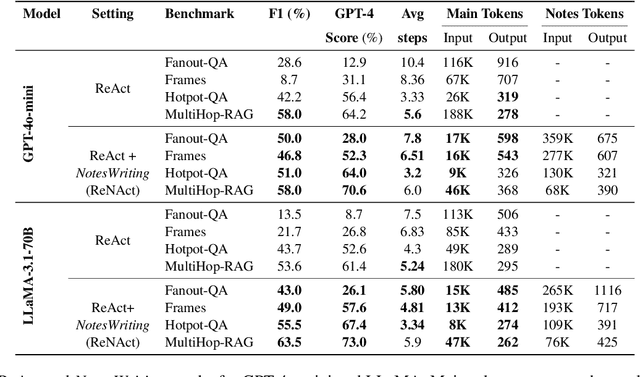
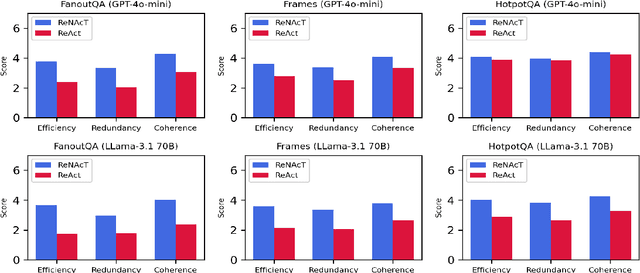
Iterative RAG for multi-hop question answering faces challenges with lengthy contexts and the buildup of irrelevant information. This hinders a model's capacity to process and reason over retrieved content and limits performance. While recent methods focus on compressing retrieved information, they are either restricted to single-round RAG, require finetuning or lack scalability in iterative RAG. To address these challenges, we propose Notes Writing, a method that generates concise and relevant notes from retrieved documents at each step, thereby reducing noise and retaining only essential information. This indirectly increases the effective context length of Large Language Models (LLMs), enabling them to reason and plan more effectively while processing larger volumes of input text. Notes Writing is framework agnostic and can be integrated with different iterative RAG methods. We demonstrate its effectiveness with three iterative RAG methods, across two models and four evaluation datasets. Notes writing yields an average improvement of 15.6 percentage points overall, with minimal increase in output tokens.
Kaleidoscope: In-language Exams for Massively Multilingual Vision Evaluation
Apr 09, 2025The evaluation of vision-language models (VLMs) has mainly relied on English-language benchmarks, leaving significant gaps in both multilingual and multicultural coverage. While multilingual benchmarks have expanded, both in size and languages, many rely on translations of English datasets, failing to capture cultural nuances. In this work, we propose Kaleidoscope, as the most comprehensive exam benchmark to date for the multilingual evaluation of vision-language models. Kaleidoscope is a large-scale, in-language multimodal benchmark designed to evaluate VLMs across diverse languages and visual inputs. Kaleidoscope covers 18 languages and 14 different subjects, amounting to a total of 20,911 multiple-choice questions. Built through an open science collaboration with a diverse group of researchers worldwide, Kaleidoscope ensures linguistic and cultural authenticity. We evaluate top-performing multilingual vision-language models and find that they perform poorly on low-resource languages and in complex multimodal scenarios. Our results highlight the need for progress on culturally inclusive multimodal evaluation frameworks.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Prompting with Phonemes: Enhancing LLM Multilinguality for non-Latin Script Languages
Nov 04, 2024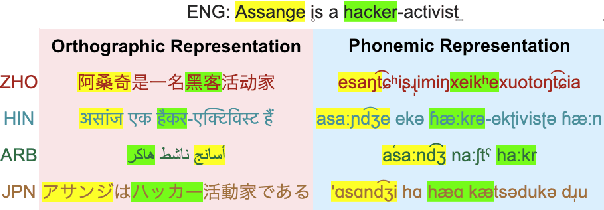

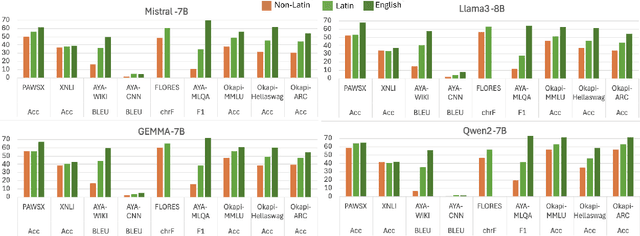

Multilingual LLMs have achieved remarkable benchmark performance, but we find they continue to underperform on non-Latin script languages across contemporary LLM families. This discrepancy arises from the fact that LLMs are pretrained with orthographic scripts, which are dominated by Latin characters that obscure their shared phonology with non-Latin scripts. We propose leveraging phonemic transcriptions as complementary signals to induce script-invariant representations. Our study demonstrates that integrating phonemic signals improves performance across both non-Latin and Latin languages, with a particularly significant impact on closing the performance gap between the two. Through detailed experiments, we show that phonemic and orthographic scripts retrieve distinct examples for in-context learning (ICL). This motivates our proposed Mixed-ICL retrieval strategy, where further aggregation leads to our significant performance improvements for both Latin script languages (up to 12.6%) and non-Latin script languages (up to 15.1%) compared to randomized ICL retrieval.
M-RewardBench: Evaluating Reward Models in Multilingual Settings
Oct 20, 2024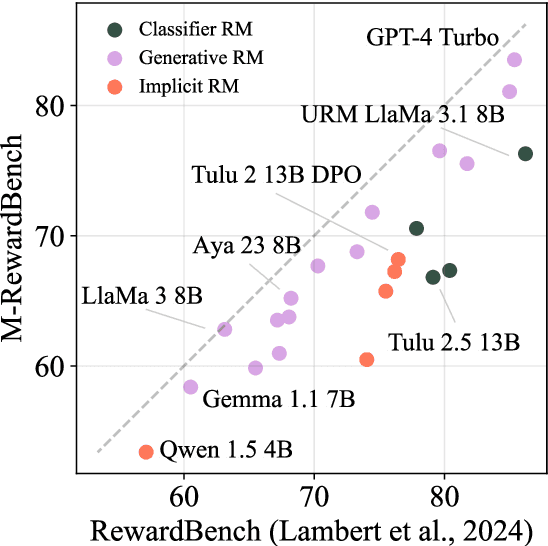



Reward models (RMs) have driven the state-of-the-art performance of LLMs today by enabling the integration of human feedback into the language modeling process. However, RMs are primarily trained and evaluated in English, and their capabilities in multilingual settings remain largely understudied. In this work, we conduct a systematic evaluation of several reward models in multilingual settings. We first construct the first-of-its-kind multilingual RM evaluation benchmark, M-RewardBench, consisting of 2.87k preference instances for 23 typologically diverse languages, that tests the chat, safety, reasoning, and translation capabilities of RMs. We then rigorously evaluate a wide range of reward models on M-RewardBench, offering fresh insights into their performance across diverse languages. We identify a significant gap in RMs' performances between English and non-English languages and show that RM preferences can change substantially from one language to another. We also present several findings on how different multilingual aspects impact RM performance. Specifically, we show that the performance of RMs is improved with improved translation quality. Similarly, we demonstrate that the models exhibit better performance for high-resource languages. We release M-RewardBench dataset and the codebase in this study to facilitate a better understanding of RM evaluation in multilingual settings.
Layer-Wise Quantization: A Pragmatic and Effective Method for Quantizing LLMs Beyond Integer Bit-Levels
Jun 26, 2024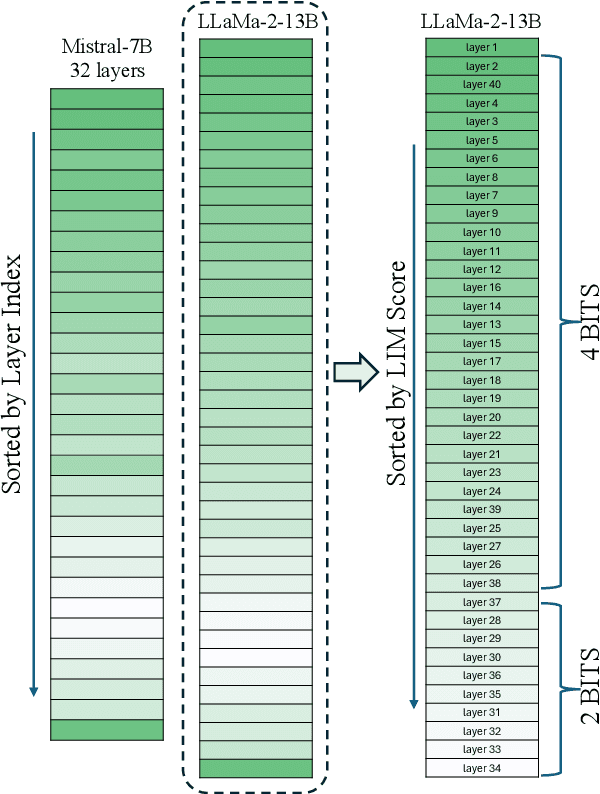



We present a simple variable quantization approach that quantizes different layers of a large language model (LLM) at different bit levels. Specifically, we quantize the most important layers to higher bit precision and less important layers to lower bits to achieve floating point quantization levels. We propose two effective strategies to measure the importance of layers within LLMs: the first measures the importance of a layer based on how different its output embeddings are from the input embeddings (the higher the better); the second estimates the importance of a layer using the number of layer weights that are much larger than average (the smaller the better). We show that quantizing different layers at varying bits according to our importance scores results in minimal performance drop with a far more compressed model size. Finally, we present several practical key takeaways from our variable layer-wise quantization experiments: (a) LLM performance under variable quantization remains close to the original model until 25-50% of layers are moved in lower quantization using our proposed ordering but only until 5-10% if moved using no specific ordering; (b) Quantizing LLMs to lower bits performs substantially better than pruning unless extreme quantization (2-bit) is used; and (c) Layer-wise quantization to lower bits works better in the case of larger LLMs with more layers compared to smaller LLMs with fewer layers. The code used to run the experiments is available at: https://github.com/RazvanDu/LayerwiseQuant.
M2Lingual: Enhancing Multilingual, Multi-Turn Instruction Alignment in Large Language Models
Jun 24, 2024



Instruction finetuning (IFT) is critical for aligning Large Language Models (LLMs) to follow instructions. Numerous effective IFT datasets have been proposed in the recent past, but most focus on high resource languages such as English. In this work, we propose a fully synthetic, novel taxonomy (Evol) guided Multilingual, Multi-turn instruction finetuning dataset, called M2Lingual, to better align LLMs on a diverse set of languages and tasks. M2Lingual contains a total of 182K IFT pairs that are built upon diverse seeds, covering 70 languages, 17 NLP tasks and general instruction-response pairs. LLMs finetuned with M2Lingual substantially outperform the majority of existing multilingual IFT datasets. Importantly, LLMs trained with M2Lingual consistently achieve competitive results across a wide variety of evaluation benchmarks compared to existing multilingual IFT datasets. Specifically, LLMs finetuned with M2Lingual achieve strong performance on our translated multilingual, multi-turn evaluation benchmark as well as a wide variety of multilingual tasks. Thus we contribute, and the 2 step Evol taxonomy used for its creation. M2Lingual repository - https://huggingface.co/datasets/ServiceNow-AI/M2Lingual
Curry-DPO: Enhancing Alignment using Curriculum Learning & Ranked Preferences
Mar 12, 2024
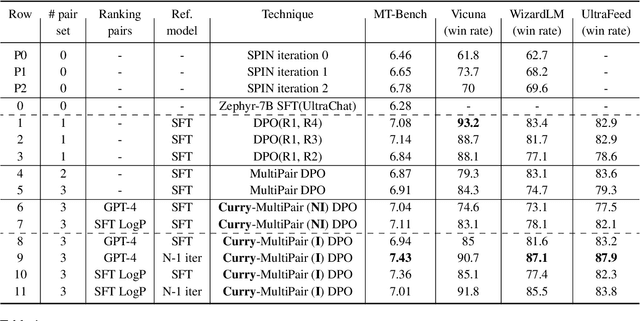
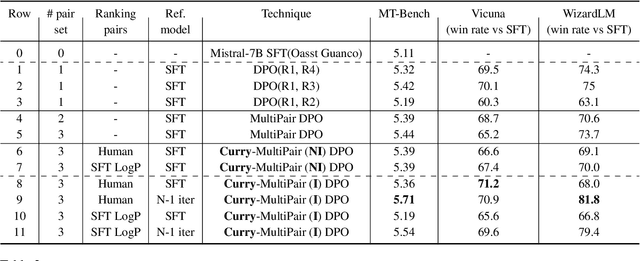

Direct Preference Optimization (DPO) is an effective technique that leverages pairwise preference data (usually one chosen and rejected response pair per user prompt) to align LLMs to human preferences. In practice, multiple responses can exist for a given prompt with varying quality relative to each other. With availability of such quality ratings for multiple responses, we propose utilizing these responses to create multiple preference pairs for a given prompt. Our work focuses on systematically using the constructed multiple preference pair in DPO training via curriculum learning methodology. In particular, we order these multiple pairs of preference data from easy to hard (emulating curriculum training) according to various criteria. We show detailed comparisons of our proposed approach to the standard single-pair DPO setting. Our method, which we call Curry-DPO consistently shows increased performance gains on MTbench, Vicuna, WizardLM, and the UltraFeedback test set, highlighting its effectiveness. More specifically, Curry-DPO achieves a score of 7.43 on MT-bench with Zephy-7B model outperforming majority of existing LLMs with similar parameter size. Curry-DPO also achieves the highest adjusted win rates on Vicuna, WizardLM, and UltraFeedback test datasets (90.7%, 87.1%, and 87.9% respectively) in our experiments, with notable gains of upto 7.5% when compared to standard DPO technique.
Improving Selective Visual Question Answering by Learning from Your Peers
Jun 14, 2023



Despite advances in Visual Question Answering (VQA), the ability of models to assess their own correctness remains underexplored. Recent work has shown that VQA models, out-of-the-box, can have difficulties abstaining from answering when they are wrong. The option to abstain, also called Selective Prediction, is highly relevant when deploying systems to users who must trust the system's output (e.g., VQA assistants for users with visual impairments). For such scenarios, abstention can be especially important as users may provide out-of-distribution (OOD) or adversarial inputs that make incorrect answers more likely. In this work, we explore Selective VQA in both in-distribution (ID) and OOD scenarios, where models are presented with mixtures of ID and OOD data. The goal is to maximize the number of questions answered while minimizing the risk of error on those questions. We propose a simple yet effective Learning from Your Peers (LYP) approach for training multimodal selection functions for making abstention decisions. Our approach uses predictions from models trained on distinct subsets of the training data as targets for optimizing a Selective VQA model. It does not require additional manual labels or held-out data and provides a signal for identifying examples that are easy/difficult to generalize to. In our extensive evaluations, we show this benefits a number of models across different architectures and scales. Overall, for ID, we reach 32.92% in the selective prediction metric coverage at 1% risk of error (C@1%) which doubles the previous best coverage of 15.79% on this task. For mixed ID/OOD, using models' softmax confidences for abstention decisions performs very poorly, answering <5% of questions at 1% risk of error even when faced with only 10% OOD examples, but a learned selection function with LYP can increase that to 25.38% C@1%.
Practice Makes a Solver Perfect: Data Augmentation for Math Word Problem Solvers
Apr 30, 2022
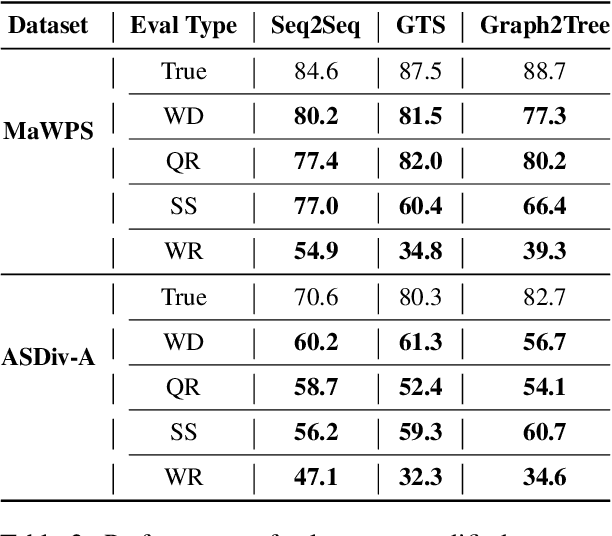
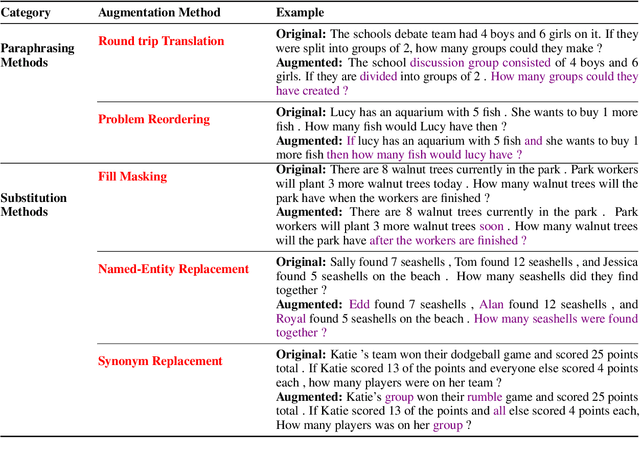
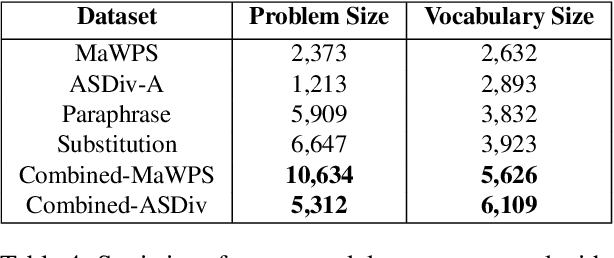
Existing Math Word Problem (MWP) solvers have achieved high accuracy on benchmark datasets. However, prior works have shown that such solvers do not generalize well and rely on superficial cues to achieve high performance. In this paper, we first conduct experiments to showcase that this behaviour is mainly associated with the limited size and diversity present in existing MWP datasets. Next, we propose several data augmentation techniques broadly categorized into Substitution and Paraphrasing based methods. By deploying these methods we increase the size of existing datasets by five folds. Extensive experiments on two benchmark datasets across three state-of-the-art MWP solvers show that proposed methods increase the generalization and robustness of existing solvers. On average, proposed methods significantly increase the state-of-the-art results by over five percentage points on benchmark datasets. Further, the solvers trained on the augmented dataset perform comparatively better on the challenge test set. We also show the effectiveness of proposed techniques through ablation studies and verify the quality of augmented samples through human evaluation.