 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Generalizability of Deep Learning Models Using Indian-COVID-19 CT Dataset
Dec 28, 2022Computer tomography (CT) have been routinely used for the diagnosis of lung diseases and recently, during the pandemic, for detecting the infectivity and severity of COVID-19 disease. One of the major concerns in using ma-chine learning (ML) approaches for automatic processing of CT scan images in clinical setting is that these methods are trained on limited and biased sub-sets of publicly available COVID-19 data. This has raised concerns regarding the generalizability of these models on external datasets, not seen by the model during training. To address some of these issues, in this work CT scan images from confirmed COVID-19 data obtained from one of the largest public repositories, COVIDx CT 2A were used for training and internal vali-dation of machine learning models. For the external validation we generated Indian-COVID-19 CT dataset, an open-source repository containing 3D CT volumes and 12096 chest CT images from 288 COVID-19 patients from In-dia. Comparative performance evaluation of four state-of-the-art machine learning models, viz., a lightweight convolutional neural network (CNN), and three other CNN based deep learning (DL) models such as VGG-16, ResNet-50 and Inception-v3 in classifying CT images into three classes, viz., normal, non-covid pneumonia, and COVID-19 is carried out on these two datasets. Our analysis showed that the performance of all the models is comparable on the hold-out COVIDx CT 2A test set with 90% - 99% accuracies (96% for CNN), while on the external Indian-COVID-19 CT dataset a drop in the performance is observed for all the models (8% - 19%). The traditional ma-chine learning model, CNN performed the best on the external dataset (accu-racy 88%) in comparison to the deep learning models, indicating that a light-weight CNN is better generalizable on unseen data. The data and code are made available at https://github.com/aleesuss/c19.
Multilinguals at SemEval-2022 Task 11: Complex NER in Semantically Ambiguous Settings for Low Resource Languages
Jul 14, 2022
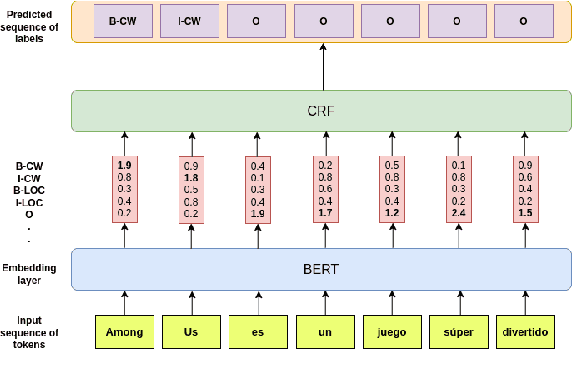

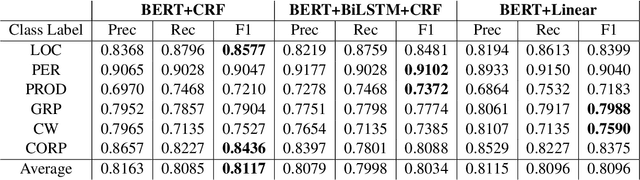
We leverage pre-trained language models to solve the task of complex NER for two low-resource languages: Chinese and Spanish. We use the technique of Whole Word Masking(WWM) to boost the performance of masked language modeling objective on large and unsupervised corpora. We experiment with multiple neural network architectures, incorporating CRF, BiLSTMs, and Linear Classifiers on top of a fine-tuned BERT layer. All our models outperform the baseline by a significant margin and our best performing model obtains a competitive position on the evaluation leaderboard for the blind test set.
Practice Makes a Solver Perfect: Data Augmentation for Math Word Problem Solvers
Apr 30, 2022
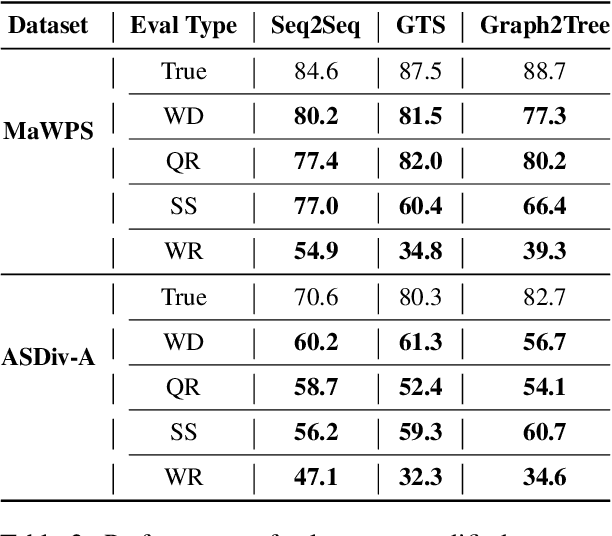
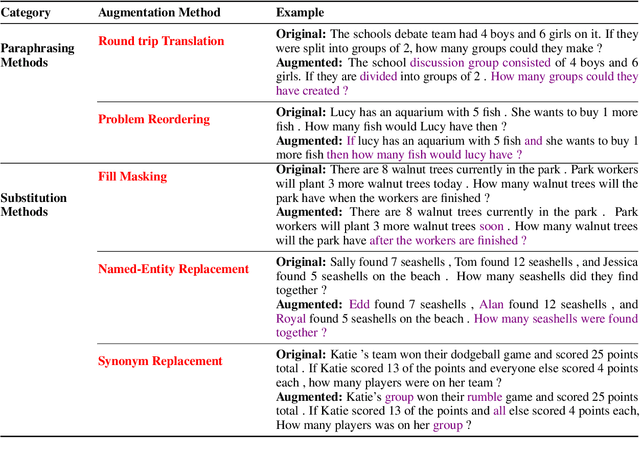
Existing Math Word Problem (MWP) solvers have achieved high accuracy on benchmark datasets. However, prior works have shown that such solvers do not generalize well and rely on superficial cues to achieve high performance. In this paper, we first conduct experiments to showcase that this behaviour is mainly associated with the limited size and diversity present in existing MWP datasets. Next, we propose several data augmentation techniques broadly categorized into Substitution and Paraphrasing based methods. By deploying these methods we increase the size of existing datasets by five folds. Extensive experiments on two benchmark datasets across three state-of-the-art MWP solvers show that proposed methods increase the generalization and robustness of existing solvers. On average, proposed methods significantly increase the state-of-the-art results by over five percentage points on benchmark datasets. Further, the solvers trained on the augmented dataset perform comparatively better on the challenge test set. We also show the effectiveness of proposed techniques through ablation studies and verify the quality of augmented samples through human evaluation.
Multilinguals at SemEval-2022 Task 11: Transformer Based Architecture for Complex NER
Apr 05, 2022
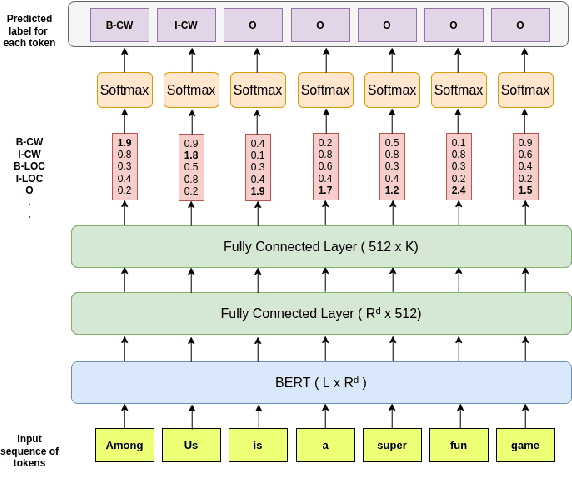
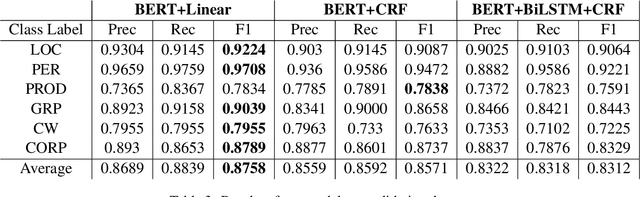

We investigate the task of complex NER for the English language. The task is non-trivial due to the semantic ambiguity of the textual structure and the rarity of occurrence of such entities in the prevalent literature. Using pre-trained language models such as BERT, we obtain a competitive performance on this task. We qualitatively analyze the performance of multiple architectures for this task. All our models are able to outperform the baseline by a significant margin. Our best performing model beats the baseline F1-score by over 9%.
Adversarial Examples for Evaluating Math Word Problem Solvers
Sep 13, 2021
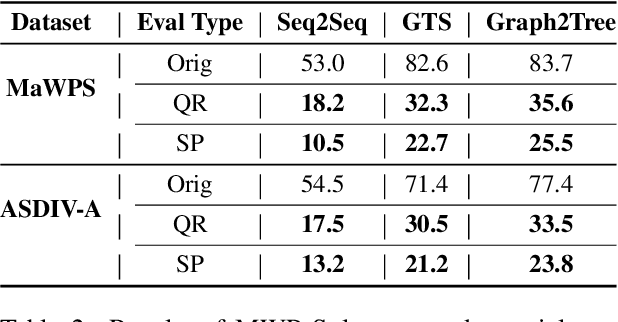
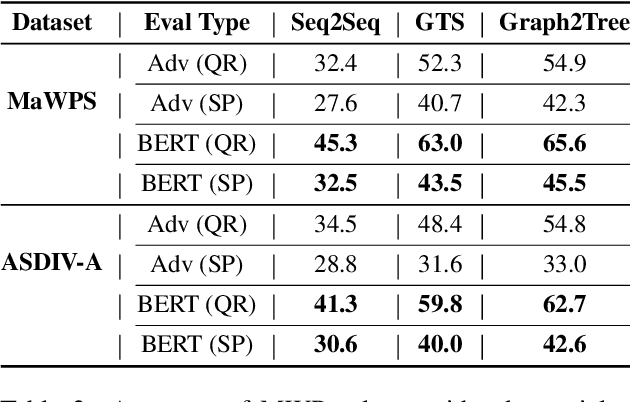
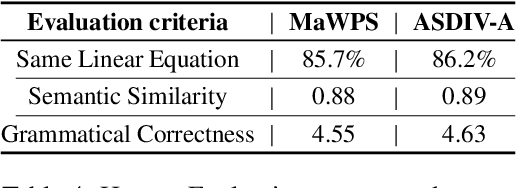
Standard accuracy metrics have shown that Math Word Problem (MWP) solvers have achieved high performance on benchmark datasets. However, the extent to which existing MWP solvers truly understand language and its relation with numbers is still unclear. In this paper, we generate adversarial attacks to evaluate the robustness of state-of-the-art MWP solvers. We propose two methods Question Reordering and Sentence Paraphrasing to generate adversarial attacks. We conduct experiments across three neural MWP solvers over two benchmark datasets. On average, our attack method is able to reduce the accuracy of MWP solvers by over 40 percentage points on these datasets. Our results demonstrate that existing MWP solvers are sensitive to linguistic variations in the problem text. We verify the validity and quality of generated adversarial examples through human evaluation.
A Strong Baseline for Query Efficient Attacks in a Black Box Setting
Sep 10, 2021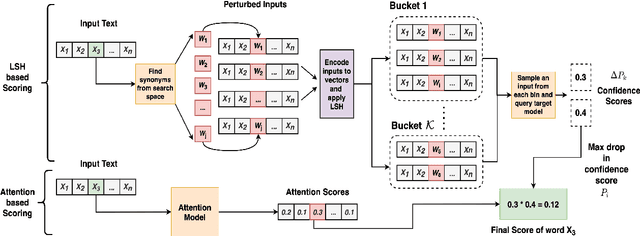
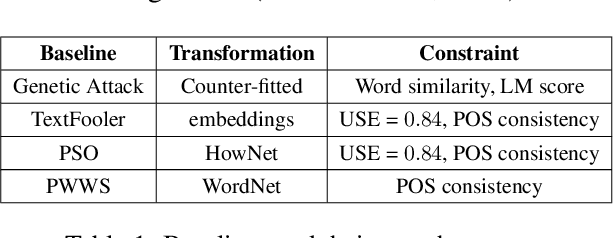
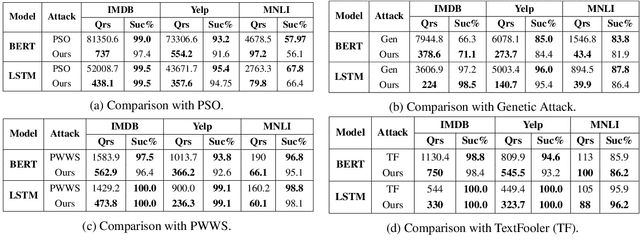

Existing black box search methods have achieved high success rate in generating adversarial attacks against NLP models. However, such search methods are inefficient as they do not consider the amount of queries required to generate adversarial attacks. Also, prior attacks do not maintain a consistent search space while comparing different search methods. In this paper, we propose a query efficient attack strategy to generate plausible adversarial examples on text classification and entailment tasks. Our attack jointly leverages attention mechanism and locality sensitive hashing (LSH) to reduce the query count. We demonstrate the efficacy of our approach by comparing our attack with four baselines across three different search spaces. Further, we benchmark our results across the same search space used in prior attacks. In comparison to attacks proposed, on an average, we are able to reduce the query count by 75% across all datasets and target models. We also demonstrate that our attack achieves a higher success rate when compared to prior attacks in a limited query setting.
Generating Natural Language Attacks in a Hard Label Black Box Setting
Dec 29, 2020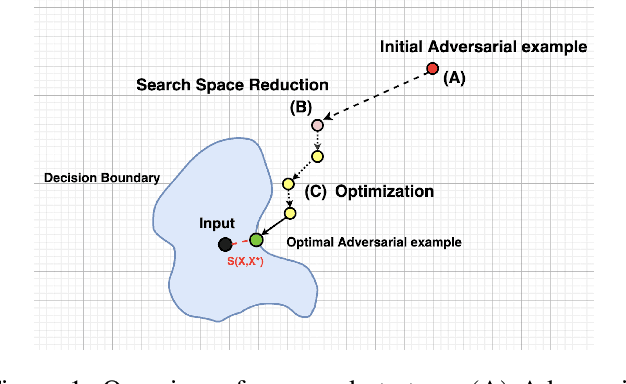
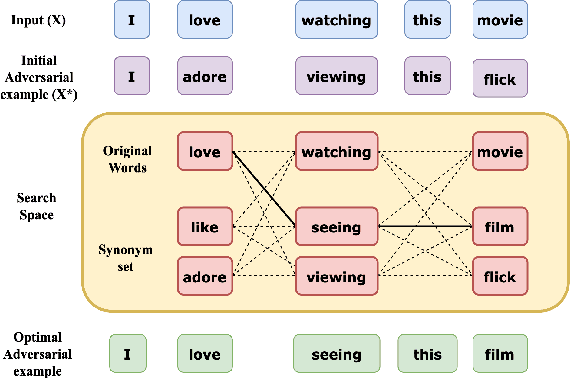
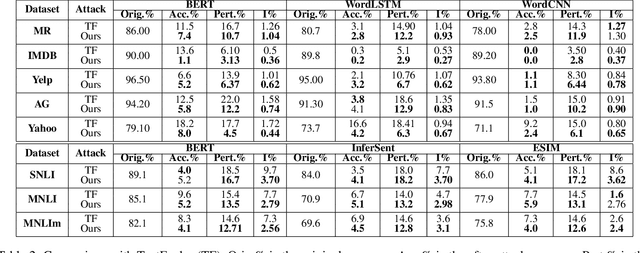
We study an important and challenging task of attacking natural language processing models in a hard label black box setting. We propose a decision-based attack strategy that crafts high quality adversarial examples on text classification and entailment tasks. Our proposed attack strategy leverages population-based optimization algorithm to craft plausible and semantically similar adversarial examples by observing only the top label predicted by the target model. At each iteration, the optimization procedure allow word replacements that maximizes the overall semantic similarity between the original and the adversarial text. Further, our approach does not rely on using substitute models or any kind of training data. We demonstrate the efficacy of our proposed approach through extensive experimentation and ablation studies on five state-of-the-art target models across seven benchmark datasets. In comparison to attacks proposed in prior literature, we are able to achieve a higher success rate with lower word perturbation percentage that too in a highly restricted setting.
A Context Aware Approach for Generating Natural Language Attacks
Dec 24, 2020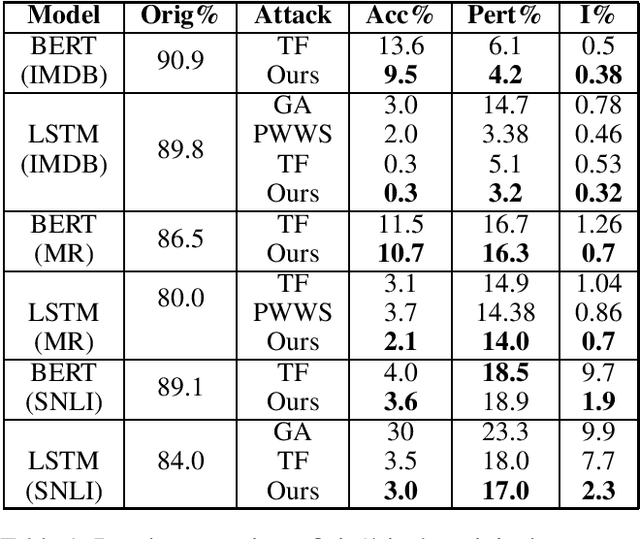

We study an important task of attacking natural language processing models in a black box setting. We propose an attack strategy that crafts semantically similar adversarial examples on text classification and entailment tasks. Our proposed attack finds candidate words by considering the information of both the original word and its surrounding context. It jointly leverages masked language modelling and next sentence prediction for context understanding. In comparison to attacks proposed in prior literature, we are able to generate high quality adversarial examples that do significantly better both in terms of success rate and word perturbation percentage.
Sequential Variational Autoencoders for Collaborative Filtering
Nov 25, 2018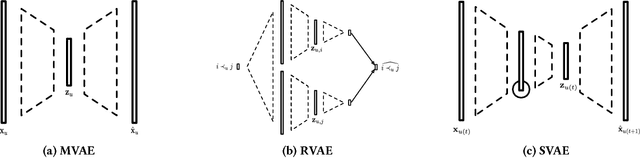
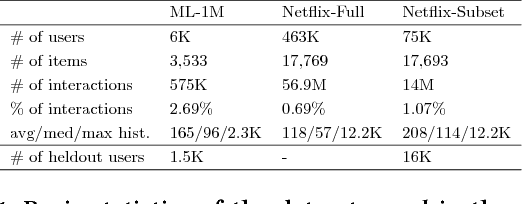
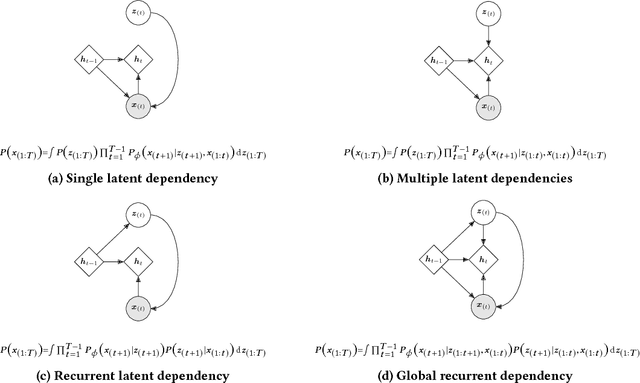
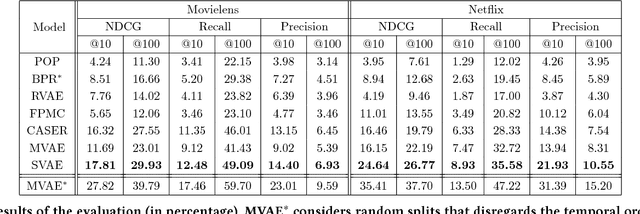
Variational autoencoders were proven successful in domains such as computer vision and speech processing. Their adoption for modeling user preferences is still unexplored, although recently it is starting to gain attention in the current literature. In this work, we propose a model which extends variational autoencoders by exploiting the rich information present in the past preference history. We introduce a recurrent version of the VAE, where instead of passing a subset of the whole history regardless of temporal dependencies, we rather pass the consumption sequence subset through a recurrent neural network. At each time-step of the RNN, the sequence is fed through a series of fully-connected layers, the output of which models the probability distribution of the most likely future preferences. We show that handling temporal information is crucial for improving the accuracy of the VAE: In fact, our model beats the current state-of-the-art by valuable margins because of its ability to capture temporal dependencies among the user-consumption sequence using the recurrent encoder still keeping the fundamentals of variational autoencoders intact.