 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Neural Graph Sparsification
Oct 31, 2025Graphs are central to modeling complex systems in domains such as social networks, molecular chemistry, and neuroscience. While Graph Neural Networks, particularly Graph Convolutional Networks, have become standard tools for graph learning, they remain constrained by reliance on fixed structures and susceptibility to over-smoothing. We propose the Spectral Preservation Network, a new framework for graph representation learning that generates reduced graphs serving as faithful proxies of the original, enabling downstream tasks such as community detection, influence propagation, and information diffusion at a reduced computational cost. The Spectral Preservation Network introduces two key components: the Joint Graph Evolution layer and the Spectral Concordance loss. The former jointly transforms both the graph topology and the node feature matrix, allowing the structure and attributes to evolve adaptively across layers and overcoming the rigidity of static neighborhood aggregation. The latter regularizes these transformations by enforcing consistency in both the spectral properties of the graph and the feature vectors of the nodes. We evaluate the effectiveness of Spectral Preservation Network on node-level sparsification by analyzing well-established metrics and benchmarking against state-of-the-art methods. The experimental results demonstrate the superior performance and clear advantages of our approach.
CAP: Detecting Unauthorized Data Usage in Generative Models via Prompt Generation
Oct 08, 2024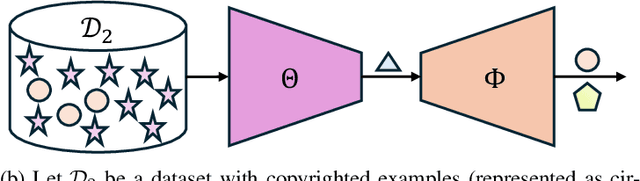

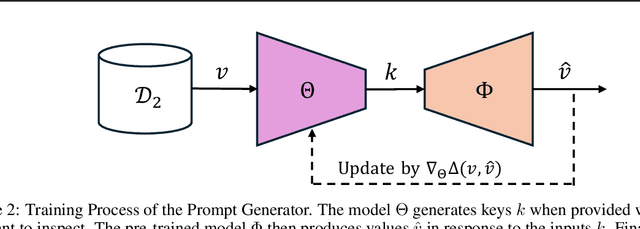

To achieve accurate and unbiased predictions, Machine Learning (ML) models rely on large, heterogeneous, and high-quality datasets. However, this could raise ethical and legal concerns regarding copyright and authorization aspects, especially when information is gathered from the Internet. With the rise of generative models, being able to track data has become of particular importance, especially since they may (un)intentionally replicate copyrighted contents. Therefore, this work proposes Copyright Audit via Prompts generation (CAP), a framework for automatically testing whether an ML model has been trained with unauthorized data. Specifically, we devise an approach to generate suitable keys inducing the model to reveal copyrighted contents. To prove its effectiveness, we conducted an extensive evaluation campaign on measurements collected in four IoT scenarios. The obtained results showcase the effectiveness of CAP, when used against both realistic and synthetic datasets.
Algorithmic Drift: A Simulation Framework to Study the Effects of Recommender Systems on User Preferences
Sep 24, 2024



Digital platforms such as social media and e-commerce websites adopt Recommender Systems to provide value to the user. However, the social consequences deriving from their adoption are still unclear. Many scholars argue that recommenders may lead to detrimental effects, such as bias-amplification deriving from the feedback loop between algorithmic suggestions and users' choices. Nonetheless, the extent to which recommenders influence changes in users leaning remains uncertain. In this context, it is important to provide a controlled environment for evaluating the recommendation algorithm before deployment. To address this, we propose a stochastic simulation framework that mimics user-recommender system interactions in a long-term scenario. In particular, we simulate the user choices by formalizing a user model, which comprises behavioral aspects, such as the user resistance towards the recommendation algorithm and their inertia in relying on the received suggestions. Additionally, we introduce two novel metrics for quantifying the algorithm's impact on user preferences, specifically in terms of drift over time. We conduct an extensive evaluation on multiple synthetic datasets, aiming at testing the robustness of our framework when considering different scenarios and hyper-parameters setting. The experimental results prove that the proposed methodology is effective in detecting and quantifying the drift over the users preferences by means of the simulation. All the code and data used to perform the experiments are publicly available.
GenRec: A Flexible Data Generator for Recommendations
Jul 23, 2024The scarcity of realistic datasets poses a significant challenge in benchmarking recommender systems and social network analysis methods and techniques. A common and effective solution is to generate synthetic data that simulates realistic interactions. However, although various methods have been proposed, the existing literature still lacks generators that are fully adaptable and allow easy manipulation of the underlying data distributions and structural properties. To address this issue, the present work introduces GenRec, a novel framework for generating synthetic user-item interactions that exhibit realistic and well-known properties observed in recommendation scenarios. The framework is based on a stochastic generative process based on latent factor modeling. Here, the latent factors can be exploited to yield long-tailed preference distributions, and at the same time they characterize subpopulations of users and topic-based item clusters. Notably, the proposed framework is highly flexible and offers a wide range of hyper-parameters for customizing the generation of user-item interactions. The code used to perform the experiments is publicly available at https://anonymous.4open.science/r/GenRec-DED3.
Neuro-Symbolic AI for Compliance Checking of Electrical Control Panels
May 17, 2023



Artificial Intelligence plays a main role in supporting and improving smart manufacturing and Industry 4.0, by enabling the automation of different types of tasks manually performed by domain experts. In particular, assessing the compliance of a product with the relative schematic is a time-consuming and prone-to-error process. In this paper, we address this problem in a specific industrial scenario. In particular, we define a Neuro-Symbolic approach for automating the compliance verification of the electrical control panels. Our approach is based on the combination of Deep Learning techniques with Answer Set Programming (ASP), and allows for identifying possible anomalies and errors in the final product even when a very limited amount of training data is available. The experiments conducted on a real test case provided by an Italian Company operating in electrical control panel production demonstrate the effectiveness of the proposed approach.
Sequential Variational Autoencoders for Collaborative Filtering
Nov 25, 2018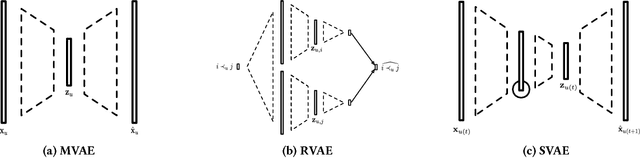
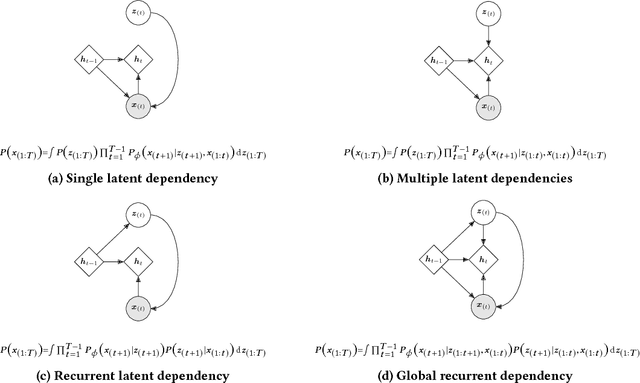
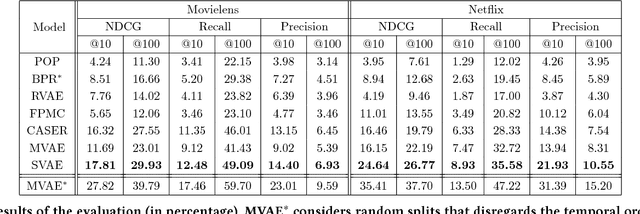
Variational autoencoders were proven successful in domains such as computer vision and speech processing. Their adoption for modeling user preferences is still unexplored, although recently it is starting to gain attention in the current literature. In this work, we propose a model which extends variational autoencoders by exploiting the rich information present in the past preference history. We introduce a recurrent version of the VAE, where instead of passing a subset of the whole history regardless of temporal dependencies, we rather pass the consumption sequence subset through a recurrent neural network. At each time-step of the RNN, the sequence is fed through a series of fully-connected layers, the output of which models the probability distribution of the most likely future preferences. We show that handling temporal information is crucial for improving the accuracy of the VAE: In fact, our model beats the current state-of-the-art by valuable margins because of its ability to capture temporal dependencies among the user-consumption sequence using the recurrent encoder still keeping the fundamentals of variational autoencoders intact.