 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAP: Detecting Unauthorized Data Usage in Generative Models via Prompt Generation
Oct 08, 2024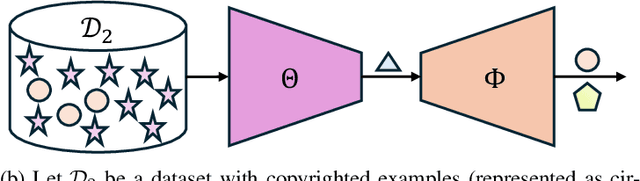

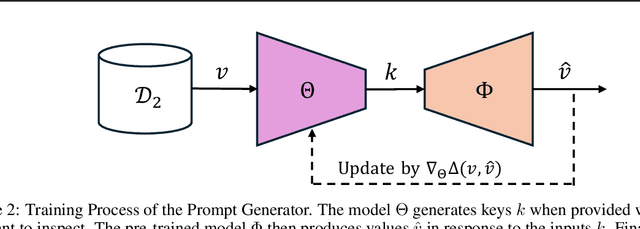

To achieve accurate and unbiased predictions, Machine Learning (ML) models rely on large, heterogeneous, and high-quality datasets. However, this could raise ethical and legal concerns regarding copyright and authorization aspects, especially when information is gathered from the Internet. With the rise of generative models, being able to track data has become of particular importance, especially since they may (un)intentionally replicate copyrighted contents. Therefore, this work proposes Copyright Audit via Prompts generation (CAP), a framework for automatically testing whether an ML model has been trained with unauthorized data. Specifically, we devise an approach to generate suitable keys inducing the model to reveal copyrighted contents. To prove its effectiveness, we conducted an extensive evaluation campaign on measurements collected in four IoT scenarios. The obtained results showcase the effectiveness of CAP, when used against both realistic and synthetic datasets.