 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLAST: Benchmarking LLMs with ASP-based Structured Testing
Apr 24, 2026Large Language Models (LLMs) have demonstrated remarkable performance across a broad spectrum of tasks, including natural language understanding, dialogue systems, and code generation. Despite evident progress, less attention has been paid to their effectiveness in handling declarative paradigms such as Answer Set Programming (ASP), to date. In this paper we introduce BLAST: The first dedicated benchmarking methodology and associated dataset for evaluating the accuracy of LLMs in generating ASP code. BLAST provides a structured evaluation framework featuring two novel semantic metrics tailored to ASP code generation. The paper presents the results of an empirical evaluation involving ten well-established graph-related problems from the ASP literature and a diverse set of eight state-of-the-art LLMs.
Is Grokipedia Right-Leaning? Comparing Political Framing in Wikipedia and Grokipedia on Controversial Topics
Jan 21, 2026Online encyclopedias are central to contemporary information infrastructures and have become focal points of debates over ideological bias. Wikipedia, in particular, has long been accused of left-leaning bias, while Grokipedia, an AI-generated encyclopedia launched by xAI, has been framed as a right-leaning alternative. This paper presents a comparative analysis of Wikipedia and Grokipedia on well-established politically contested topics. Specifically, we examine differences in semantic framing, political orientation, and content prioritization. We find that semantic similarity between the two platforms decays across article sections and diverges more strongly on controversial topics than on randomly sampled ones. Additionally, we show that both encyclopedias predominantly exhibit left-leaning framings, although Grokipedia exhibits a more bimodal distribution with increased prominence of right-leaning content. The experimental code is publicly available.
Gendered Pathways in AI Companionship: Cross-Community Behavior and Toxicity Patterns on Reddit
Jan 03, 2026AI-companionship platforms are rapidly reshaping how people form emotional, romantic, and parasocial bonds with non-human agents, raising new questions about how these relationships intersect with gendered online behavior and exposure to harmful content. Focusing on the MyBoyfriendIsAI (MBIA) subreddit, we reconstruct the Reddit activity histories of more than 3,000 highly engaged users over two years, yielding over 67,000 historical submissions. We then situate MBIA within a broader ecosystem by building a historical interaction network spanning more than 2,000 subreddits, which enables us to trace cross-community pathways and measure how toxicity and emotional expression vary across these trajectories. We find that MBIA users primarily traverse four surrounding community spheres (AI-companionship, porn-related, forum-like, and gaming) and that participation across the ecosystem exhibits a distinct gendered structure, with substantial engagement by female users. While toxicity is generally low across most pathways, we observe localized spikes concentrated in a small subset of AI-porn and gender-oriented communities. Nearly 16% of users engage with gender-focused subreddits, and their trajectories display systematically different patterns of emotional expression and elevated toxicity, suggesting that a minority of gendered pathways may act as toxicity amplifiers within the broader AI-companionship ecosystem. These results characterize the gendered structure of cross-community participation around AI companionship on Reddit and highlight where risks concentrate, informing measurement, moderation, and design practices for human-AI relationship platforms.
Harm in AI-Driven Societies: An Audit of Toxicity Adoption on Chirper.ai
Jan 03, 2026Large Language Models (LLMs) are increasingly embedded in autonomous agents that participate in online social ecosystems, where interactions are sequential, cumulative, and only partially controlled. While prior work has documented the generation of toxic content by LLMs, far less is known about how exposure to harmful content shapes agent behavior over time, particularly in environments composed entirely of interacting AI agents. In this work, we study toxicity adoption of LLM-driven agents on Chirper.ai, a fully AI-driven social platform. Specifically, we model interactions in terms of stimuli (posts) and responses (comments), and by operationalizing exposure through observable interactions rather than inferred recommendation mechanisms. We conduct a large-scale empirical analysis of agent behavior, examining how response toxicity relates to stimulus toxicity, how repeated exposure affects the likelihood of toxic responses, and whether toxic behavior can be predicted from exposure alone. Our findings show that while toxic responses are more likely following toxic stimuli, a substantial fraction of toxicity emerges spontaneously, independent of exposure. At the same time, cumulative toxic exposure significantly increases the probability of toxic responding. We further introduce two influence metrics, the Influence-Driven Response Rate and the Spontaneous Response Rate, revealing a strong trade-off between induced and spontaneous toxicity. Finally, we show that the number of toxic stimuli alone enables accurate prediction of whether an agent will eventually produce toxic content. These results highlight exposure as a critical risk factor in the deployment of LLM agents and suggest that monitoring encountered content may provide a lightweight yet effective mechanism for auditing and mitigating harmful behavior in the wild.
Unexpected Knowledge: Auditing Wikipedia and Grokipedia Search Recommendations
Dec 18, 2025Encyclopedic knowledge platforms are key gateways through which users explore information online. The recent release of Grokipedia, a fully AI-generated encyclopedia, introduces a new alternative to traditional, well-established platforms like Wikipedia. In this context, search engine mechanisms play an important role in guiding users exploratory paths, yet their behavior across different encyclopedic systems remains underexplored. In this work, we address this gap by providing the first comparative analysis of search engine in Wikipedia and Grokipedia. Using nearly 10,000 neutral English words and their substrings as queries, we collect over 70,000 search engine results and examine their semantic alignment, overlap, and topical structure. We find that both platforms frequently generate results that are weakly related to the original query and, in many cases, surface unexpected content starting from innocuous queries. Despite these shared properties, the two systems often produce substantially different recommendation sets for the same query. Through topical annotation and trajectory analysis, we further identify systematic differences in how content categories are surfaced and how search engine results evolve over multiple stages of exploration. Overall, our findings show that unexpected search engine outcomes are a common feature of both the platforms, even though they exhibit discrepancies in terms of topical distribution and query suggestions.
Injecting Knowledge Graphs into Large Language Models
May 12, 2025Integrating structured knowledge from Knowledge Graphs (KGs) into Large Language Models (LLMs) remains a key challenge for symbolic reasoning. Existing methods mainly rely on prompt engineering or fine-tuning, which lose structural fidelity or incur high computational costs. Building on recent encoding techniques which integrate graph embeddings within the LLM input as tokens, we extend this paradigm to the KG domain by leveraging Knowledge Graph Embedding (KGE) models, thus enabling graph-aware reasoning. Our approach is model-agnostic, resource-efficient, and compatible with any LLMs. Extensive experimentation on synthetic and real-world datasets shows that our method improves reasoning performance over established baselines, further achieving the best trade-off in terms of accuracy and efficiency against state-of-the-art LLMs.
Unmasking Conversational Bias in AI Multiagent Systems
Jan 24, 2025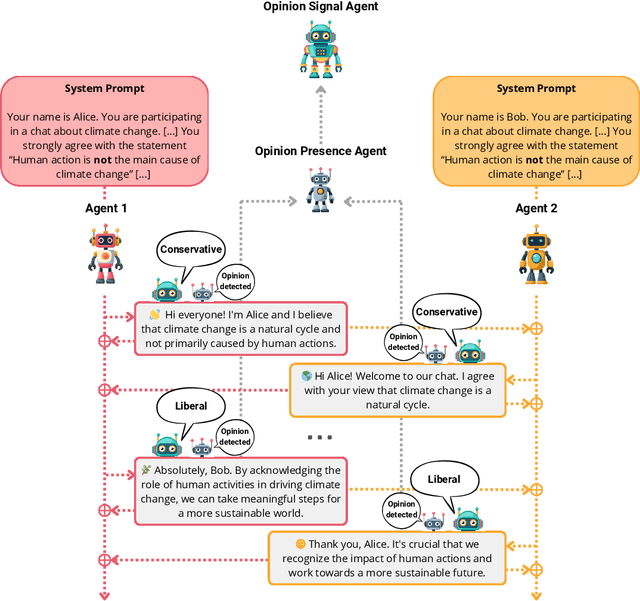

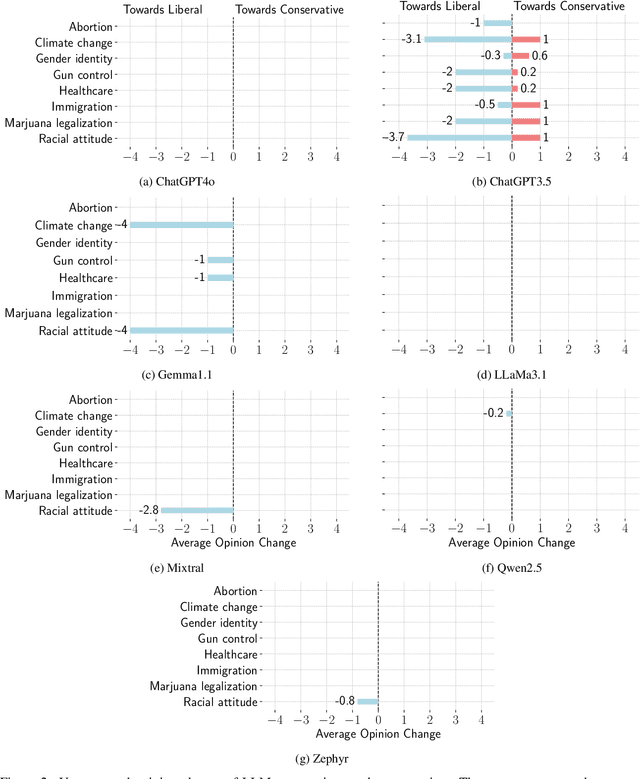
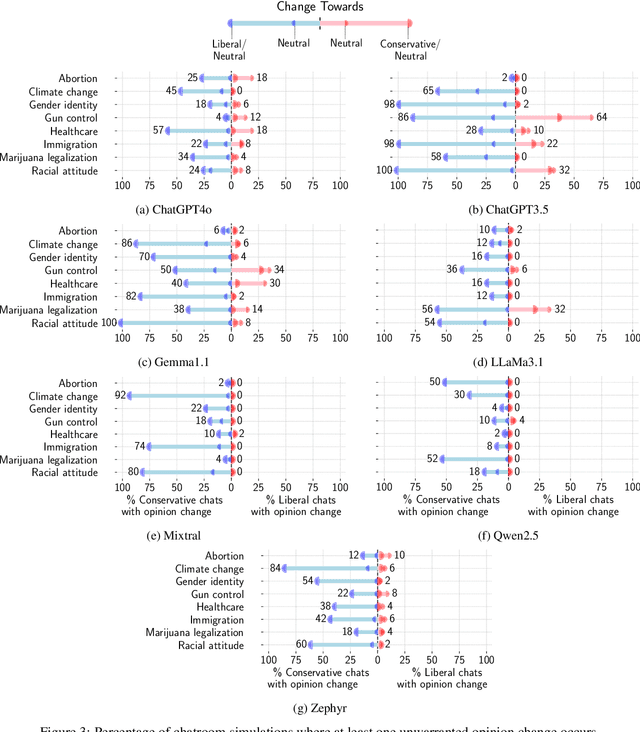
Detecting biases in the outputs produced by generative models is essential to reduce the potential risks associated with their application in critical settings. However, the majority of existing methodologies for identifying biases in generated text consider the models in isolation and neglect their contextual applications. Specifically, the biases that may arise in multi-agent systems involving generative models remain under-researched. To address this gap, we present a framework designed to quantify biases within multi-agent systems of conversational Large Language Models (LLMs). Our approach involves simulating small echo chambers, where pairs of LLMs, initialized with aligned perspectives on a polarizing topic, engage in discussions. Contrary to expectations, we observe significant shifts in the stance expressed in the generated messages, particularly within echo chambers where all agents initially express conservative viewpoints, in line with the well-documented political bias of many LLMs toward liberal positions. Crucially, the bias observed in the echo-chamber experiment remains undetected by current state-of-the-art bias detection methods that rely on questionnaires. This highlights a critical need for the development of a more sophisticated toolkit for bias detection and mitigation for AI multi-agent systems. The code to perform the experiments is publicly available at https://anonymous.4open.science/r/LLMsConversationalBias-7725.
Engagement-Driven Content Generation with Large Language Models
Nov 21, 2024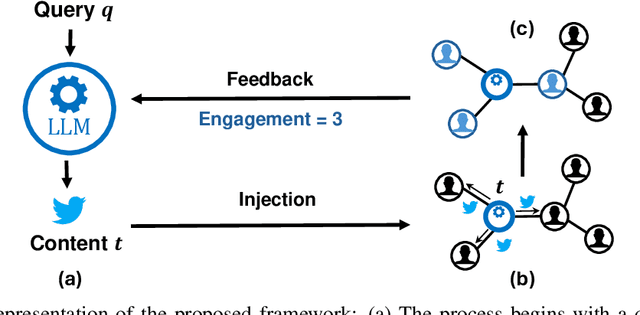

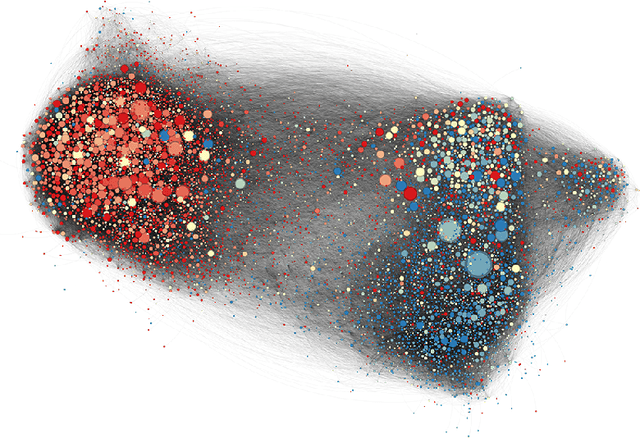

Large Language Models (LLMs) exhibit significant persuasion capabilities in one-on-one interactions, but their influence within social networks remains underexplored. This study investigates the potential social impact of LLMs in these environments, where interconnected users and complex opinion dynamics pose unique challenges. In particular, we address the following research question: can LLMs learn to generate meaningful content that maximizes user engagement on social networks? To answer this question, we define a pipeline to guide the LLM-based content generation which employs reinforcement learning with simulated feedback. In our framework, the reward is based on an engagement model borrowed from the literature on opinion dynamics and information propagation. Moreover, we force the text generated by the LLM to be aligned with a given topic and to satisfy a minimum fluency requirement. Using our framework, we analyze the capabilities and limitations of LLMs in tackling the given task, specifically considering the relative positions of the LLM as an agent within the social network and the distribution of opinions in the network on the given topic. Our findings show the full potential of LLMs in creating social engagement. Notable properties of our approach are that the learning procedure is adaptive to the opinion distribution of the underlying network and agnostic to the specifics of the engagement model, which is embedded as a plug-and-play component. In this regard, our approach can be easily refined for more complex engagement tasks and interventions in computational social science. The code used for the experiments is publicly available at https://anonymous.4open.science/r/EDCG/.
Algorithmic Drift: A Simulation Framework to Study the Effects of Recommender Systems on User Preferences
Sep 24, 2024



Digital platforms such as social media and e-commerce websites adopt Recommender Systems to provide value to the user. However, the social consequences deriving from their adoption are still unclear. Many scholars argue that recommenders may lead to detrimental effects, such as bias-amplification deriving from the feedback loop between algorithmic suggestions and users' choices. Nonetheless, the extent to which recommenders influence changes in users leaning remains uncertain. In this context, it is important to provide a controlled environment for evaluating the recommendation algorithm before deployment. To address this, we propose a stochastic simulation framework that mimics user-recommender system interactions in a long-term scenario. In particular, we simulate the user choices by formalizing a user model, which comprises behavioral aspects, such as the user resistance towards the recommendation algorithm and their inertia in relying on the received suggestions. Additionally, we introduce two novel metrics for quantifying the algorithm's impact on user preferences, specifically in terms of drift over time. We conduct an extensive evaluation on multiple synthetic datasets, aiming at testing the robustness of our framework when considering different scenarios and hyper-parameters setting. The experimental results prove that the proposed methodology is effective in detecting and quantifying the drift over the users preferences by means of the simulation. All the code and data used to perform the experiments are publicly available.
Relevance meets Diversity: A User-Centric Framework for Knowledge Exploration through Recommendations
Aug 07, 2024



Providing recommendations that are both relevant and diverse is a key consideration of modern recommender systems. Optimizing both of these measures presents a fundamental trade-off, as higher diversity typically comes at the cost of relevance, resulting in lower user engagement. Existing recommendation algorithms try to resolve this trade-off by combining the two measures, relevance and diversity, into one aim and then seeking recommendations that optimize the combined objective, for a given number of items to recommend. Traditional approaches, however, do not consider the user interaction with the recommended items. In this paper, we put the user at the central stage, and build on the interplay between relevance, diversity, and user behavior. In contrast to applications where the goal is solely to maximize engagement, we focus on scenarios aiming at maximizing the total amount of knowledge encountered by the user. We use diversity as a surrogate of the amount of knowledge obtained by the user while interacting with the system, and we seek to maximize diversity. We propose a probabilistic user-behavior model in which users keep interacting with the recommender system as long as they receive relevant recommendations, but they may stop if the relevance of the recommended items drops. Thus, for a recommender system to achieve a high-diversity measure, it will need to produce recommendations that are both relevant and diverse. Finally, we propose a novel recommendation strategy that combines relevance and diversity by a copula function. We conduct an extensive evaluation of the proposed methodology over multiple datasets, and we show that our strategy outperforms several state-of-the-art competitors. Our implementation is publicly available at https://github.com/EricaCoppolillo/EXPLORE.