 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Stochastic Submodular Maximization with On-Demand User Requests
Jan 15, 2026We explore a novel problem in streaming submodular maximization, inspired by the dynamics of news-recommendation platforms. We consider a setting where users can visit a news website at any time, and upon each visit, the website must display up to $k$ news items. User interactions are inherently stochastic: each news item presented to the user is consumed with a certain acceptance probability by the user, and each news item covers certain topics. Our goal is to design a streaming algorithm that maximizes the expected total topic coverage. To address this problem, we establish a connection to submodular maximization subject to a matroid constraint. We show that we can effectively adapt previous methods to address our problem when the number of user visits is known in advance or linear-size memory in the stream length is available. However, in more realistic scenarios where only an upper bound on the visits and sublinear memory is available, the algorithms fail to guarantee any bounded performance. To overcome these limitations, we introduce a new online streaming algorithm that achieves a competitive ratio of $1/(8δ)$, where $δ$ controls the approximation quality. Moreover, it requires only a single pass over the stream, and uses memory independent of the stream length. Empirically, our algorithms consistently outperform the baselines.
Label-consistent clustering for evolving data
Dec 17, 2025Data analysis often involves an iterative process, where solutions must be continuously refined in response to new data. Typically, as new data becomes available, an existing solution must be updated to incorporate the latest information. In addition to seeking a high-quality solution for the task at hand, it is also crucial to ensure consistency by minimizing drastic changes from previous solutions. Applying this approach across many iterations, ensures that the solution evolves gradually and smoothly. In this paper, we study the above problem in the context of clustering, specifically focusing on the $k$-center problem. More precisely, we study the following problem: Given a set of points $X$, parameters $k$ and $b$, and a prior clustering solution $H$ for $X$, our goal is to compute a new solution $C$ for $X$, consisting of $k$ centers, which minimizes the clustering cost while introducing at most $b$ changes from $H$. We refer to this problem as label-consistent $k$-center, and we propose two constant-factor approximation algorithms for it. We complement our theoretical findings with an experimental evaluation demonstrating the effectiveness of our methods on real-world datasets.
Fairness-aware PageRank via Edge Reweighting
Dec 12, 2025Link-analysis algorithms, such as PageRank, are instrumental in understanding the structural dynamics of networks by evaluating the importance of individual vertices based on their connectivity. Recently, with the rising importance of responsible AI, the question of fairness in link-analysis algorithms has gained traction. In this paper, we present a new approach for incorporating group fairness into the PageRank algorithm by reweighting the transition probabilities in the underlying transition matrix. We formulate the problem of achieving fair PageRank by seeking to minimize the fairness loss, which is the difference between the original group-wise PageRank distribution and a target PageRank distribution. We further define a group-adapted fairness notion, which accounts for group homophily by considering random walks with group-biased restart for each group. Since the fairness loss is non-convex, we propose an efficient projected gradient-descent method for computing locally-optimal edge weights. Unlike earlier approaches, we do not recommend adding new edges to the network, nor do we adjust the restart vector. Instead, we keep the topology of the underlying network unchanged and only modify the relative importance of existing edges. We empirically compare our approach with state-of-the-art baselines and demonstrate the efficacy of our method, where very small changes in the transition matrix lead to significant improvement in the fairness of the PageRank algorithm.
Fair Clustering for Data Summarization: Improved Approximation Algorithms and Complexity Insights
Oct 16, 2024Data summarization tasks are often modeled as $k$-clustering problems, where the goal is to choose $k$ data points, called cluster centers, that best represent the dataset by minimizing a clustering objective. A popular objective is to minimize the maximum distance between any data point and its nearest center, which is formalized as the $k$-center problem. While in some applications all data points can be chosen as centers, in the general setting, centers must be chosen from a predefined subset of points, referred as facilities or suppliers; this is known as the $k$-supplier problem. In this work, we focus on fair data summarization modeled as the fair $k$-supplier problem, where data consists of several groups, and a minimum number of centers must be selected from each group while minimizing the $k$-supplier objective. The groups can be disjoint or overlapping, leading to two distinct problem variants each with different computational complexity. We present $3$-approximation algorithms for both variants, improving the previously known factor of $5$. For disjoint groups, our algorithm runs in polynomial time, while for overlapping groups, we present a fixed-parameter tractable algorithm, where the exponential runtime depends only on the number of groups and centers. We show that these approximation factors match the theoretical lower bounds, assuming standard complexity theory conjectures. Finally, using an open-source implementation, we demonstrate the scalability of our algorithms on large synthetic datasets and assess the price of fairness on real-world data, comparing solution quality with and without fairness constraints.
Relevance meets Diversity: A User-Centric Framework for Knowledge Exploration through Recommendations
Aug 07, 2024



Providing recommendations that are both relevant and diverse is a key consideration of modern recommender systems. Optimizing both of these measures presents a fundamental trade-off, as higher diversity typically comes at the cost of relevance, resulting in lower user engagement. Existing recommendation algorithms try to resolve this trade-off by combining the two measures, relevance and diversity, into one aim and then seeking recommendations that optimize the combined objective, for a given number of items to recommend. Traditional approaches, however, do not consider the user interaction with the recommended items. In this paper, we put the user at the central stage, and build on the interplay between relevance, diversity, and user behavior. In contrast to applications where the goal is solely to maximize engagement, we focus on scenarios aiming at maximizing the total amount of knowledge encountered by the user. We use diversity as a surrogate of the amount of knowledge obtained by the user while interacting with the system, and we seek to maximize diversity. We propose a probabilistic user-behavior model in which users keep interacting with the recommender system as long as they receive relevant recommendations, but they may stop if the relevance of the recommended items drops. Thus, for a recommender system to achieve a high-diversity measure, it will need to produce recommendations that are both relevant and diverse. Finally, we propose a novel recommendation strategy that combines relevance and diversity by a copula function. We conduct an extensive evaluation of the proposed methodology over multiple datasets, and we show that our strategy outperforms several state-of-the-art competitors. Our implementation is publicly available at https://github.com/EricaCoppolillo/EXPLORE.
Efficient Exploration of the Rashomon Set of Rule Set Models
Jun 05, 2024



Today, as increasingly complex predictive models are developed, simple rule sets remain a crucial tool to obtain interpretable predictions and drive high-stakes decision making. However, a single rule set provides a partial representation of a learning task. An emerging paradigm in interpretable machine learning aims at exploring the Rashomon set of all models exhibiting near-optimal performance. Existing work on Rashomon-set exploration focuses on exhaustive search of the Rashomon set for particular classes of models, which can be a computationally challenging task. On the other hand, exhaustive enumeration leads to redundancy that often is not necessary, and a representative sample or an estimate of the size of the Rashomon set is sufficient for many applications. In this work, we propose, for the first time, efficient methods to explore the Rashomon set of rule set models with or without exhaustive search. Extensive experiments demonstrate the effectiveness of the proposed methods in a variety of scenarios.
Diversity-aware clustering: Computational Complexity and Approximation Algorithms
Jan 10, 2024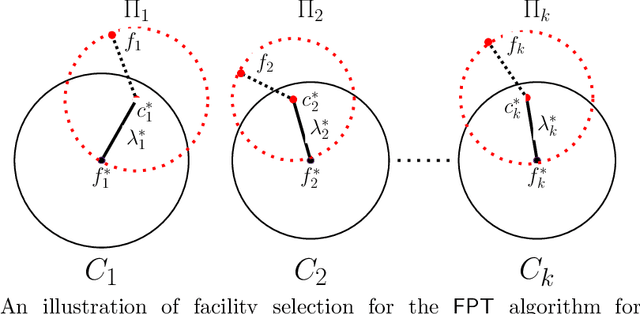
In this work, we study diversity-aware clustering problems where the data points are associated with multiple attributes resulting in intersecting groups. A clustering solution need to ensure that a minimum number of cluster centers are chosen from each group while simultaneously minimizing the clustering objective, which can be either $k$-median, $k$-means or $k$-supplier. We present parameterized approximation algorithms with approximation ratios $1+ \frac{2}{e}$, $1+\frac{8}{e}$ and $3$ for diversity-aware $k$-median, diversity-aware $k$-means and diversity-aware $k$-supplier, respectively. The approximation ratios are tight assuming Gap-ETH and FPT $\neq$ W[2]. For fair $k$-median and fair $k$-means with disjoint faicility groups, we present parameterized approximation algorithm with approximation ratios $1+\frac{2}{e}$ and $1+\frac{8}{e}$, respectively. For fair $k$-supplier with disjoint facility groups, we present a polynomial-time approximation algorithm with factor $3$, improving the previous best known approximation ratio of factor $5$.
Rebalancing Social Feed to Minimize Polarization and Disagreement
Aug 28, 2023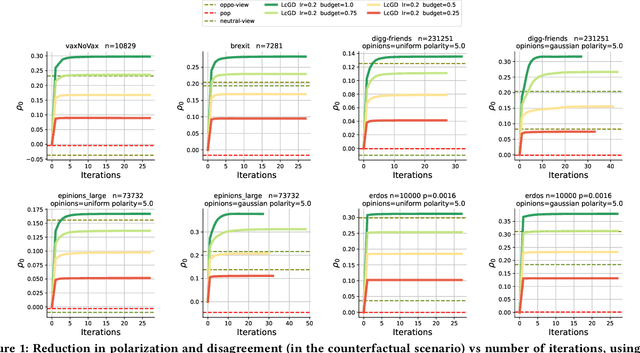
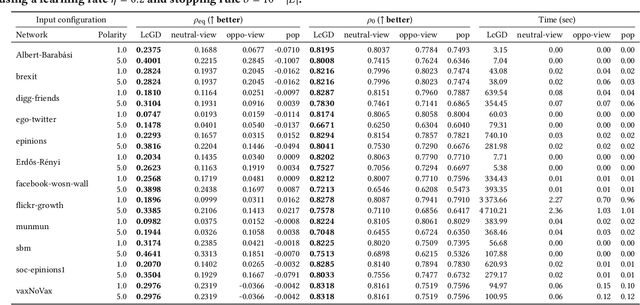
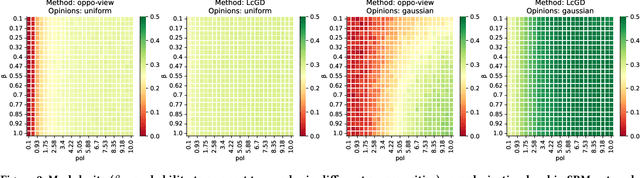
Social media have great potential for enabling public discourse on important societal issues. However, adverse effects, such as polarization and echo chambers, greatly impact the benefits of social media and call for algorithms that mitigate these effects. In this paper, we propose a novel problem formulation aimed at slightly nudging users' social feeds in order to strike a balance between relevance and diversity, thus mitigating the emergence of polarization, without lowering the quality of the feed. Our approach is based on re-weighting the relative importance of the accounts that a user follows, so as to calibrate the frequency with which the content produced by various accounts is shown to the user. We analyze the convexity properties of the problem, demonstrating the non-matrix convexity of the objective function and the convexity of the feasible set. To efficiently address the problem, we develop a scalable algorithm based on projected gradient descent. We also prove that our problem statement is a proper generalization of the undirected-case problem so that our method can also be adopted for undirected social networks. As a baseline for comparison in the undirected case, we develop a semidefinite programming approach, which provides the optimal solution. Through extensive experiments on synthetic and real-world datasets, we validate the effectiveness of our approach, which outperforms non-trivial baselines, underscoring its ability to foster healthier and more cohesive online communities.
Adversaries with Limited Information in the Friedkin--Johnsen Model
Jun 17, 2023In recent years, online social networks have been the target of adversaries who seek to introduce discord into societies, to undermine democracies and to destabilize communities. Often the goal is not to favor a certain side of a conflict but to increase disagreement and polarization. To get a mathematical understanding of such attacks, researchers use opinion-formation models from sociology, such as the Friedkin--Johnsen model, and formally study how much discord the adversary can produce when altering the opinions for only a small set of users. In this line of work, it is commonly assumed that the adversary has full knowledge about the network topology and the opinions of all users. However, the latter assumption is often unrealistic in practice, where user opinions are not available or simply difficult to estimate accurately. To address this concern, we raise the following question: Can an attacker sow discord in a social network, even when only the network topology is known? We answer this question affirmatively. We present approximation algorithms for detecting a small set of users who are highly influential for the disagreement and polarization in the network. We show that when the adversary radicalizes these users and if the initial disagreement/polarization in the network is not very high, then our method gives a constant-factor approximation on the setting when the user opinions are known. To find the set of influential users, we provide a novel approximation algorithm for a variant of MaxCut in graphs with positive and negative edge weights. We experimentally evaluate our methods, which have access only to the network topology, and we find that they have similar performance as methods that have access to the network topology and all user opinions. We further present an NP-hardness proof, which was an open question by Chen and Racz [IEEE Trans. Netw. Sci. Eng., 2021].
Learning Cellular Coverage from Real Network Configurations using GNNs
Apr 20, 2023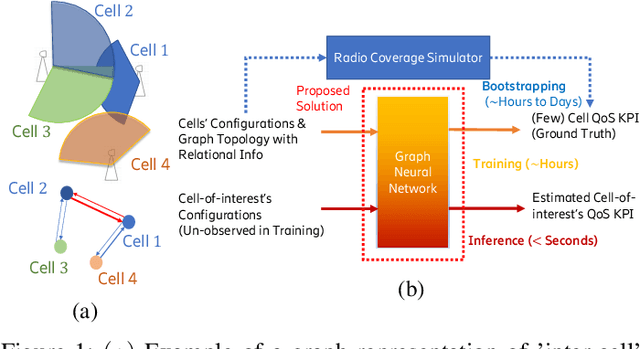
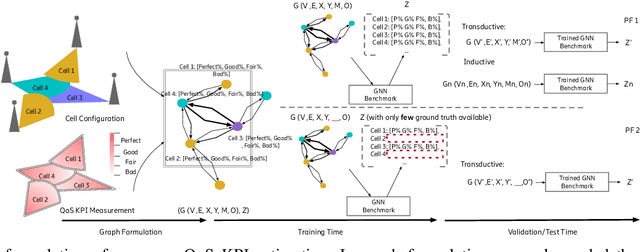
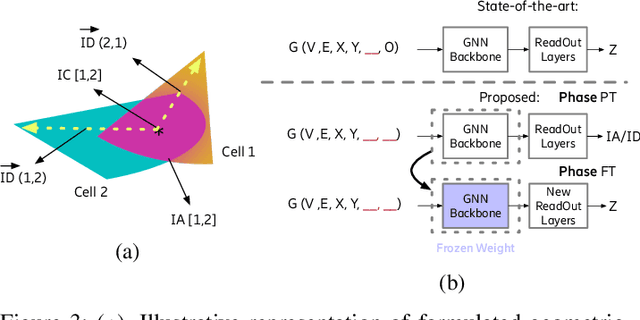
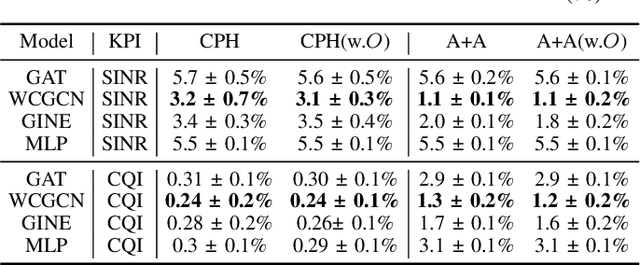
Cellular coverage quality estimation has been a critical task for self-organized networks. In real-world scenarios, deep-learning-powered coverage quality estimation methods cannot scale up to large areas due to little ground truth can be provided during network design & optimization. In addition they fall short in produce expressive embeddings to adequately capture the variations of the cells' configurations. To deal with this challenge, we formulate the task in a graph representation and so that we can apply state-of-the-art graph neural networks, that show exemplary performance. We propose a novel training framework that can both produce quality cell configuration embeddings for estimating multiple KPIs, while we show it is capable of generalising to large (area-wide) scenarios given very few labeled cells. We show that our framework yields comparable accuracy with models that have been trained using massively labeled samples.