 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized impurity reduction: Accurate decision trees with complexity guarantees
Paper and Code
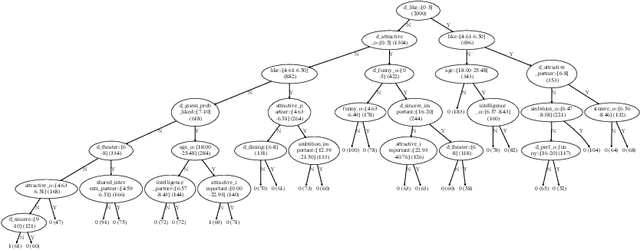
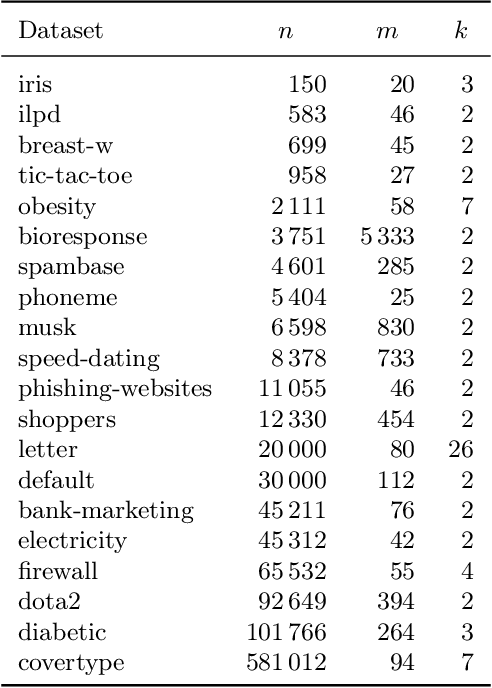


Decision trees are popular classification models, providing high accuracy and intuitive explanations. However, as the tree size grows the model interpretability deteriorates. Traditional tree-induction algorithms, such as C4.5 and CART, rely on impurity-reduction functions that promote the discriminative power of each split. Thus, although these traditional methods are accurate in practice, there has been no theoretical guarantee that they will produce small trees. In this paper, we justify the use of a general family of impurity functions, including the popular functions of entropy and Gini-index, in scenarios where small trees are desirable, by showing that a simple enhancement can equip them with complexity guarantees. We consider a general setting, where objects to be classified are drawn from an arbitrary probability distribution, classification can be binary or multi-class, and splitting tests are associated with non-uniform costs. As a measure of tree complexity, we adopt the expected cost to classify an object drawn from the input distribution, which, in the uniform-cost case, is the expected number of tests. We propose a tree-induction algorithm that gives a logarithmic approximation guarantee on the tree complexity. This approximation factor is tight up to a constant factor under mild assumptions. The algorithm recursively selects a test that maximizes a greedy criterion defined as a weighted sum of three components. The first two components encourage the selection of tests that improve the balance and the cost-efficiency of the tree, respectively, while the third impurity-reduction component encourages the selection of more discriminative tests. As shown in our empirical evaluation, compared to the original heuristics, the enhanced algorithms strike an excellent balance between predictive accuracy and tree complexity.