 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel-consistent clustering for evolving data
Dec 17, 2025Data analysis often involves an iterative process, where solutions must be continuously refined in response to new data. Typically, as new data becomes available, an existing solution must be updated to incorporate the latest information. In addition to seeking a high-quality solution for the task at hand, it is also crucial to ensure consistency by minimizing drastic changes from previous solutions. Applying this approach across many iterations, ensures that the solution evolves gradually and smoothly. In this paper, we study the above problem in the context of clustering, specifically focusing on the $k$-center problem. More precisely, we study the following problem: Given a set of points $X$, parameters $k$ and $b$, and a prior clustering solution $H$ for $X$, our goal is to compute a new solution $C$ for $X$, consisting of $k$ centers, which minimizes the clustering cost while introducing at most $b$ changes from $H$. We refer to this problem as label-consistent $k$-center, and we propose two constant-factor approximation algorithms for it. We complement our theoretical findings with an experimental evaluation demonstrating the effectiveness of our methods on real-world datasets.
Fair Clustering for Data Summarization: Improved Approximation Algorithms and Complexity Insights
Oct 16, 2024Data summarization tasks are often modeled as $k$-clustering problems, where the goal is to choose $k$ data points, called cluster centers, that best represent the dataset by minimizing a clustering objective. A popular objective is to minimize the maximum distance between any data point and its nearest center, which is formalized as the $k$-center problem. While in some applications all data points can be chosen as centers, in the general setting, centers must be chosen from a predefined subset of points, referred as facilities or suppliers; this is known as the $k$-supplier problem. In this work, we focus on fair data summarization modeled as the fair $k$-supplier problem, where data consists of several groups, and a minimum number of centers must be selected from each group while minimizing the $k$-supplier objective. The groups can be disjoint or overlapping, leading to two distinct problem variants each with different computational complexity. We present $3$-approximation algorithms for both variants, improving the previously known factor of $5$. For disjoint groups, our algorithm runs in polynomial time, while for overlapping groups, we present a fixed-parameter tractable algorithm, where the exponential runtime depends only on the number of groups and centers. We show that these approximation factors match the theoretical lower bounds, assuming standard complexity theory conjectures. Finally, using an open-source implementation, we demonstrate the scalability of our algorithms on large synthetic datasets and assess the price of fairness on real-world data, comparing solution quality with and without fairness constraints.
Diversity-aware clustering: Computational Complexity and Approximation Algorithms
Jan 10, 2024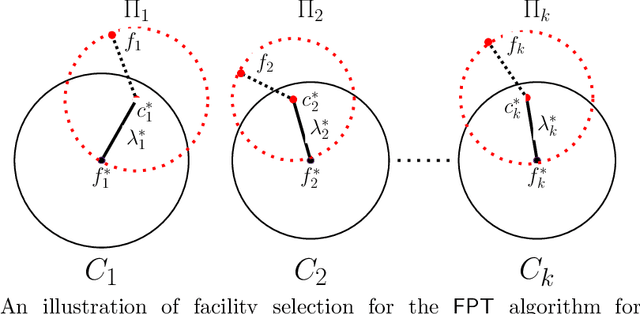
In this work, we study diversity-aware clustering problems where the data points are associated with multiple attributes resulting in intersecting groups. A clustering solution need to ensure that a minimum number of cluster centers are chosen from each group while simultaneously minimizing the clustering objective, which can be either $k$-median, $k$-means or $k$-supplier. We present parameterized approximation algorithms with approximation ratios $1+ \frac{2}{e}$, $1+\frac{8}{e}$ and $3$ for diversity-aware $k$-median, diversity-aware $k$-means and diversity-aware $k$-supplier, respectively. The approximation ratios are tight assuming Gap-ETH and FPT $\neq$ W[2]. For fair $k$-median and fair $k$-means with disjoint faicility groups, we present parameterized approximation algorithm with approximation ratios $1+\frac{2}{e}$ and $1+\frac{8}{e}$, respectively. For fair $k$-supplier with disjoint facility groups, we present a polynomial-time approximation algorithm with factor $3$, improving the previous best known approximation ratio of factor $5$.
Parameterized Approximation for Robust Clustering in Discrete Geometric Spaces
May 12, 2023We consider the well-studied Robust $(k, z)$-Clustering problem, which generalizes the classic $k$-Median, $k$-Means, and $k$-Center problems. Given a constant $z\ge 1$, the input to Robust $(k, z)$-Clustering is a set $P$ of $n$ weighted points in a metric space $(M,\delta)$ and a positive integer $k$. Further, each point belongs to one (or more) of the $m$ many different groups $S_1,S_2,\ldots,S_m$. Our goal is to find a set $X$ of $k$ centers such that $\max_{i \in [m]} \sum_{p \in S_i} w(p) \delta(p,X)^z$ is minimized. This problem arises in the domains of robust optimization [Anthony, Goyal, Gupta, Nagarajan, Math. Oper. Res. 2010] and in algorithmic fairness. For polynomial time computation, an approximation factor of $O(\log m/\log\log m)$ is known [Makarychev, Vakilian, COLT $2021$], which is tight under a plausible complexity assumption even in the line metrics. For FPT time, there is a $(3^z+\epsilon)$-approximation algorithm, which is tight under GAP-ETH [Goyal, Jaiswal, Inf. Proc. Letters, 2023]. Motivated by the tight lower bounds for general discrete metrics, we focus on \emph{geometric} spaces such as the (discrete) high-dimensional Euclidean setting and metrics of low doubling dimension, which play an important role in data analysis applications. First, for a universal constant $\eta_0 >0.0006$, we devise a $3^z(1-\eta_{0})$-factor FPT approximation algorithm for discrete high-dimensional Euclidean spaces thereby bypassing the lower bound for general metrics. We complement this result by showing that even the special case of $k$-Center in dimension $\Theta(\log n)$ is $(\sqrt{3/2}- o(1))$-hard to approximate for FPT algorithms. Finally, we complete the FPT approximation landscape by designing an FPT $(1+\epsilon)$-approximation scheme (EPAS) for the metric of sub-logarithmic doubling dimension.
Parameterized Approximation Schemes for Clustering with General Norm Objectives
Apr 06, 2023
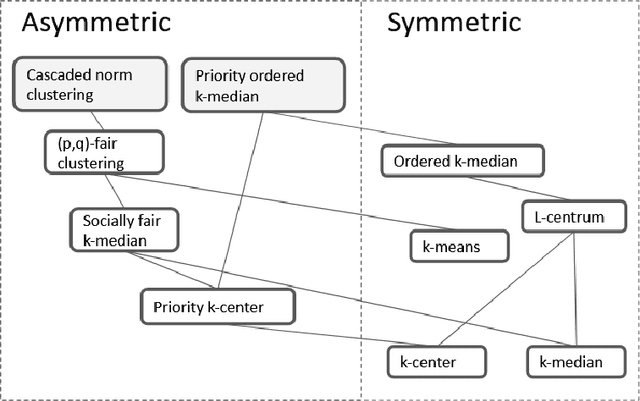
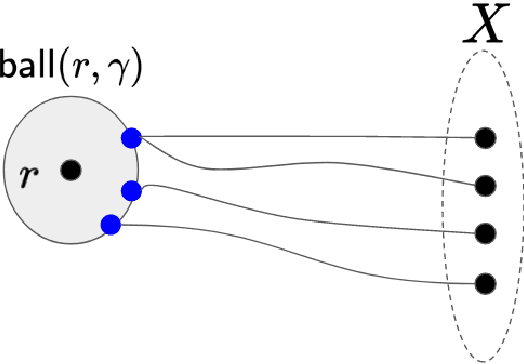
This paper considers the well-studied algorithmic regime of designing a $(1+\epsilon)$-approximation algorithm for a $k$-clustering problem that runs in time $f(k,\epsilon)poly(n)$ (sometimes called an efficient parameterized approximation scheme or EPAS for short). Notable results of this kind include EPASes in the high-dimensional Euclidean setting for $k$-center [Bad\u{o}iu, Har-Peled, Indyk; STOC'02] as well as $k$-median, and $k$-means [Kumar, Sabharwal, Sen; J. ACM 2010]. However, existing EPASes handle only basic objectives (such as $k$-center, $k$-median, and $k$-means) and are tailored to the specific objective and metric space. Our main contribution is a clean and simple EPAS that settles more than ten clustering problems (across multiple well-studied objectives as well as metric spaces) and unifies well-known EPASes. Our algorithm gives EPASes for a large variety of clustering objectives (for example, $k$-means, $k$-center, $k$-median, priority $k$-center, $\ell$-centrum, ordered $k$-median, socially fair $k$-median aka robust $k$-median, or more generally monotone norm $k$-clustering) and metric spaces (for example, continuous high-dimensional Euclidean spaces, metrics of bounded doubling dimension, bounded treewidth metrics, and planar metrics). Key to our approach is a new concept that we call bounded $\epsilon$-scatter dimension--an intrinsic complexity measure of a metric space that is a relaxation of the standard notion of bounded doubling dimension. Our main technical result shows that two conditions are essentially sufficient for our algorithm to yield an EPAS on the input metric $M$ for any clustering objective: (i) The objective is described by a monotone (not necessarily symmetric!) norm, and (ii) the $\epsilon$-scatter dimension of $M$ is upper bounded by a function of $\epsilon$.
On learning k-parities with and without noise
Feb 18, 2015We first consider the problem of learning $k$-parities in the on-line mistake-bound model: given a hidden vector $x \in \{0,1\}^n$ with $|x|=k$ and a sequence of "questions" $a_1, a_2, ...\in \{0,1\}^n$, where the algorithm must reply to each question with $< a_i, x> \pmod 2$, what is the best tradeoff between the number of mistakes made by the algorithm and its time complexity? We improve the previous best result of Buhrman et al. by an $\exp(k)$ factor in the time complexity. Second, we consider the problem of learning $k$-parities in the presence of classification noise of rate $\eta \in (0,1/2)$. A polynomial time algorithm for this problem (when $\eta > 0$ and $k = \omega(1)$) is a longstanding challenge in learning theory. Grigorescu et al. showed an algorithm running in time ${n \choose k/2}^{1 + 4\eta^2 +o(1)}$. Note that this algorithm inherently requires time ${n \choose k/2}$ even when the noise rate $\eta$ is polynomially small. We observe that for sufficiently small noise rate, it is possible to break the $n \choose k/2$ barrier. In particular, if for some function $f(n) = \omega(1)$ and $\alpha \in [1/2, 1)$, $k = n/f(n)$ and $\eta = o(f(n)^{- \alpha}/\log n)$, then there is an algorithm for the problem with running time $poly(n)\cdot {n \choose k}^{1-\alpha} \cdot e^{-k/4.01}$.