 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Power of Interactive Proofs for Learning
Apr 11, 2024We continue the study of doubly-efficient proof systems for verifying agnostic PAC learning, for which we obtain the following results. - We construct an interactive protocol for learning the $t$ largest Fourier characters of a given function $f \colon \{0,1\}^n \to \{0,1\}$ up to an arbitrarily small error, wherein the verifier uses $\mathsf{poly}(t)$ random examples. This improves upon the Interactive Goldreich-Levin protocol of Goldwasser, Rothblum, Shafer, and Yehudayoff (ITCS 2021) whose sample complexity is $\mathsf{poly}(t,n)$. - For agnostically learning the class $\mathsf{AC}^0[2]$ under the uniform distribution, we build on the work of Carmosino, Impagliazzo, Kabanets, and Kolokolova (APPROX/RANDOM 2017) and design an interactive protocol, where given a function $f \colon \{0,1\}^n \to \{0,1\}$, the verifier learns the closest hypothesis up to $\mathsf{polylog}(n)$ multiplicative factor, using quasi-polynomially many random examples. In contrast, this class has been notoriously resistant even for constructing realisable learners (without a prover) using random examples. - For agnostically learning $k$-juntas under the uniform distribution, we obtain an interactive protocol, where the verifier uses $O(2^k)$ random examples to a given function $f \colon \{0,1\}^n \to \{0,1\}$. Crucially, the sample complexity of the verifier is independent of $n$. We also show that if we do not insist on doubly-efficient proof systems, then the model becomes trivial. Specifically, we show a protocol for an arbitrary class $\mathcal{C}$ of Boolean functions in the distribution-free setting, where the verifier uses $O(1)$ labeled examples to learn $f$.
Optimally Deceiving a Learning Leader in Stackelberg Games
Jun 11, 2020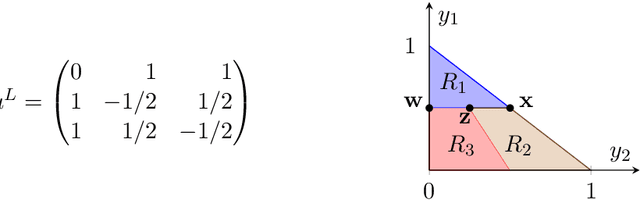
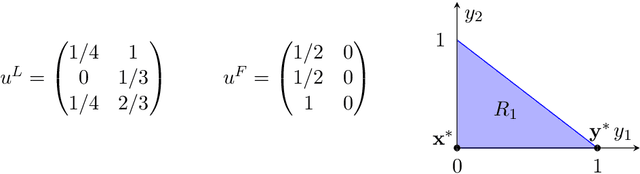
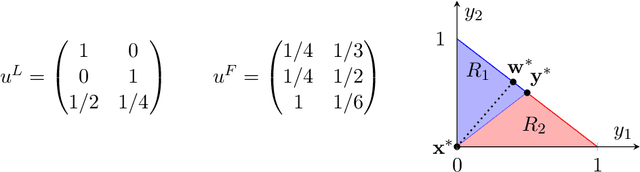
Recent results in the ML community have revealed that learning algorithms used to compute the optimal strategy for the leader to commit to in a Stackelberg game, are susceptible to manipulation by the follower. Such a learning algorithm operates by querying the best responses or the payoffs of the follower, who consequently can deceive the algorithm by responding as if his payoffs were much different than what they actually are. For this strategic behavior to be successful, the main challenge faced by the follower is to pinpoint the payoffs that would make the learning algorithm compute a commitment so that best responding to it maximizes the follower's utility, according to his true payoffs. While this problem has been considered before, the related literature only focused on the simplified scenario in which the payoff space is finite, thus leaving the general version of the problem unanswered. In this paper, we fill in this gap, by showing that it is always possible for the follower to compute (near-)optimal payoffs for various scenarios about the learning interaction between leader and follower.
On learning k-parities with and without noise
Feb 18, 2015We first consider the problem of learning $k$-parities in the on-line mistake-bound model: given a hidden vector $x \in \{0,1\}^n$ with $|x|=k$ and a sequence of "questions" $a_1, a_2, ...\in \{0,1\}^n$, where the algorithm must reply to each question with $< a_i, x> \pmod 2$, what is the best tradeoff between the number of mistakes made by the algorithm and its time complexity? We improve the previous best result of Buhrman et al. by an $\exp(k)$ factor in the time complexity. Second, we consider the problem of learning $k$-parities in the presence of classification noise of rate $\eta \in (0,1/2)$. A polynomial time algorithm for this problem (when $\eta > 0$ and $k = \omega(1)$) is a longstanding challenge in learning theory. Grigorescu et al. showed an algorithm running in time ${n \choose k/2}^{1 + 4\eta^2 +o(1)}$. Note that this algorithm inherently requires time ${n \choose k/2}$ even when the noise rate $\eta$ is polynomially small. We observe that for sufficiently small noise rate, it is possible to break the $n \choose k/2$ barrier. In particular, if for some function $f(n) = \omega(1)$ and $\alpha \in [1/2, 1)$, $k = n/f(n)$ and $\eta = o(f(n)^{- \alpha}/\log n)$, then there is an algorithm for the problem with running time $poly(n)\cdot {n \choose k}^{1-\alpha} \cdot e^{-k/4.01}$.