 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimally Deceiving a Learning Leader in Stackelberg Games
Jun 11, 2020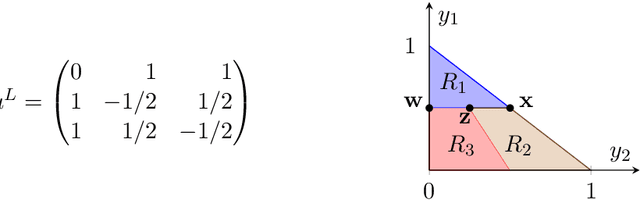
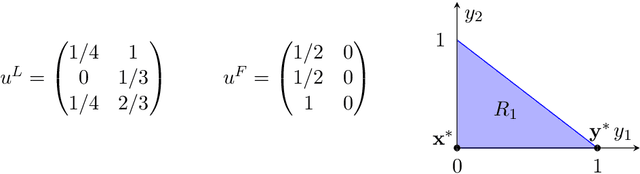
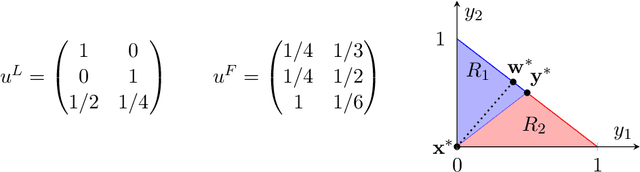
Recent results in the ML community have revealed that learning algorithms used to compute the optimal strategy for the leader to commit to in a Stackelberg game, are susceptible to manipulation by the follower. Such a learning algorithm operates by querying the best responses or the payoffs of the follower, who consequently can deceive the algorithm by responding as if his payoffs were much different than what they actually are. For this strategic behavior to be successful, the main challenge faced by the follower is to pinpoint the payoffs that would make the learning algorithm compute a commitment so that best responding to it maximizes the follower's utility, according to his true payoffs. While this problem has been considered before, the related literature only focused on the simplified scenario in which the payoff space is finite, thus leaving the general version of the problem unanswered. In this paper, we fill in this gap, by showing that it is always possible for the follower to compute (near-)optimal payoffs for various scenarios about the learning interaction between leader and follower.
Efficiency and complexity of price competition among single-product vendors
Mar 06, 2017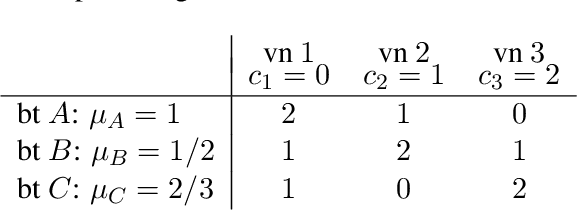
Motivated by recent progress on pricing in the AI literature, we study marketplaces that contain multiple vendors offering identical or similar products and unit-demand buyers with different valuations on these vendors. The objective of each vendor is to set the price of its product to a fixed value so that its profit is maximized. The profit depends on the vendor's price itself and the total volume of buyers that find the particular price more attractive than the price of the vendor's competitors. We model the behaviour of buyers and vendors as a two-stage full-information game and study a series of questions related to the existence, efficiency (price of anarchy) and computational complexity of equilibria in this game. To overcome situations where equilibria do not exist or exist but are highly inefficient, we consider the scenario where some of the vendors are subsidized in order to keep prices low and buyers highly satisfied.
Optimizing positional scoring rules for rank aggregation
Sep 18, 2016
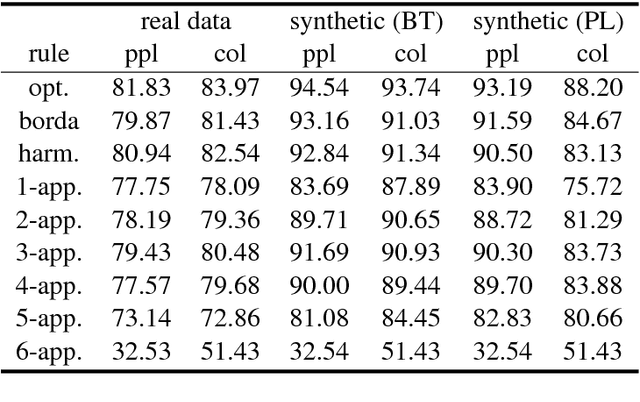
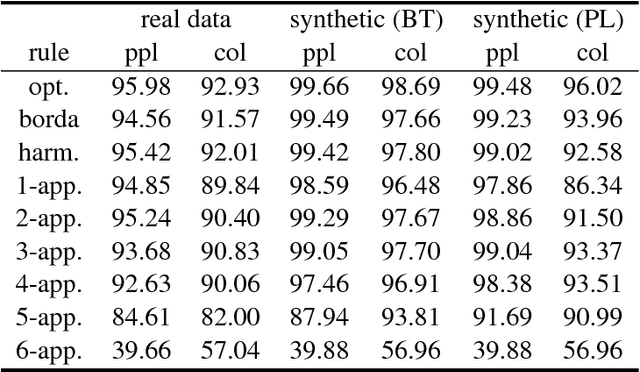
Nowadays, several crowdsourcing projects exploit social choice methods for computing an aggregate ranking of alternatives given individual rankings provided by workers. Motivated by such systems, we consider a setting where each worker is asked to rank a fixed (small) number of alternatives and, then, a positional scoring rule is used to compute the aggregate ranking. Among the apparently infinite such rules, what is the best one to use? To answer this question, we assume that we have partial access to an underlying true ranking. Then, the important optimization problem to be solved is to compute the positional scoring rule whose outcome, when applied to the profile of individual rankings, is as close as possible to the part of the underlying true ranking we know. We study this fundamental problem from a theoretical viewpoint and present positive and negative complexity results and, furthermore, complement our theoretical findings with experiments on real-world and synthetic data.
How effective can simple ordinal peer grading be?
Feb 25, 2016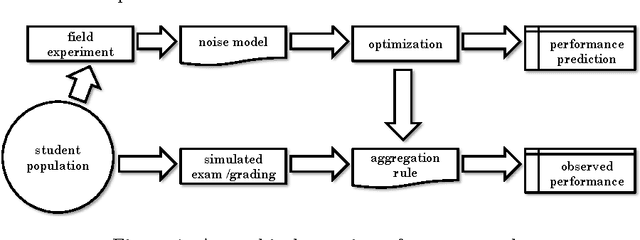


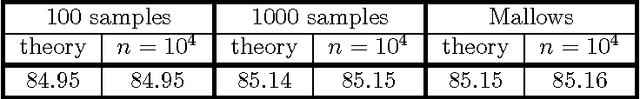
Ordinal peer grading has been proposed as a simple and scalable solution for computing reliable information about student performance in massive open online courses. The idea is to outsource the grading task to the students themselves as follows. After the end of an exam, each student is asked to rank ---in terms of quality--- a bundle of exam papers by fellow students. An aggregation rule will then combine the individual rankings into a global one that contains all students. We define a broad class of simple aggregation rules and present a theoretical framework for assessing their effectiveness. When statistical information about the grading behaviour of students is available, the framework can be used to compute the optimal rule from this class with respect to a series of performance objectives. For example, a natural rule known as Borda is proved to be optimal when students grade correctly. In addition, we present extensive simulations and a field experiment that validate our theory and prove it to be extremely accurate in predicting the performance of aggregation rules even when only rough information about grading behaviour is available.
Aggregating partial rankings with applications to peer grading in massive online open courses
Nov 17, 2014

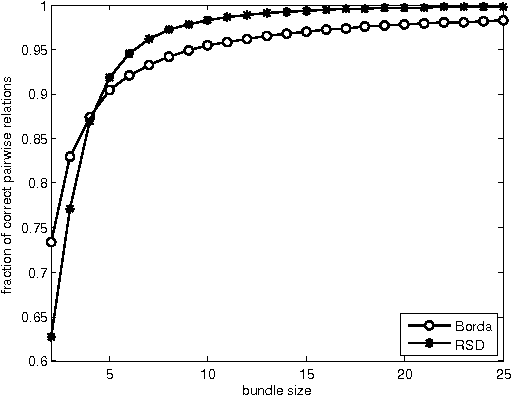

We investigate the potential of using ordinal peer grading for the evaluation of students in massive online open courses (MOOCs). According to such grading schemes, each student receives a few assignments (by other students) which she has to rank. Then, a global ranking (possibly translated into numerical scores) is produced by combining the individual ones. This is a novel application area for social choice concepts and methods where the important problem to be solved is as follows: how should the assignments be distributed so that the collected individual rankings can be easily merged into a global one that is as close as possible to the ranking that represents the relative performance of the students in the assignment? Our main theoretical result suggests that using very simple ways to distribute the assignments so that each student has to rank only $k$ of them, a Borda-like aggregation method can recover a $1-O(1/k)$ fraction of the true ranking when each student correctly ranks the assignments she receives. Experimental results strengthen our analysis further and also demonstrate that the same method is extremely robust even when students have imperfect capabilities as graders. We believe that our results provide strong evidence that ordinal peer grading can be a highly effective and scalable solution for evaluation in MOOCs.