 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilinguals at SemEval-2022 Task 11: Complex NER in Semantically Ambiguous Settings for Low Resource Languages
Jul 14, 2022
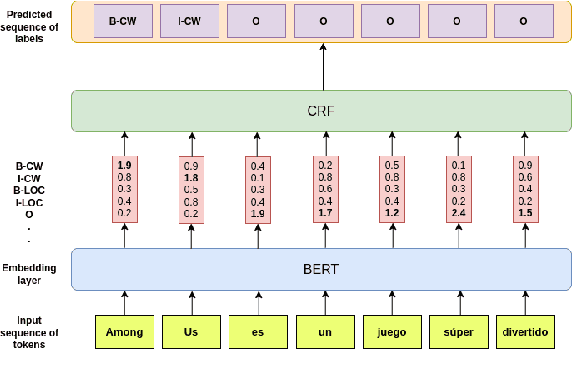

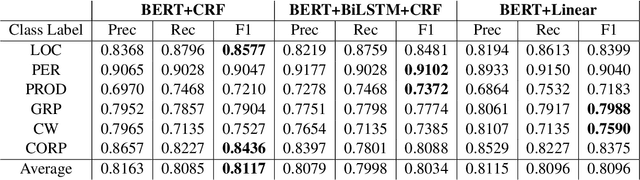
We leverage pre-trained language models to solve the task of complex NER for two low-resource languages: Chinese and Spanish. We use the technique of Whole Word Masking(WWM) to boost the performance of masked language modeling objective on large and unsupervised corpora. We experiment with multiple neural network architectures, incorporating CRF, BiLSTMs, and Linear Classifiers on top of a fine-tuned BERT layer. All our models outperform the baseline by a significant margin and our best performing model obtains a competitive position on the evaluation leaderboard for the blind test set.
Multilinguals at SemEval-2022 Task 11: Transformer Based Architecture for Complex NER
Apr 05, 2022
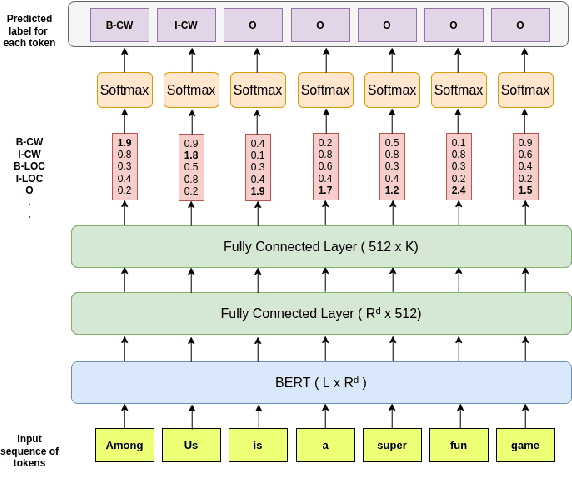
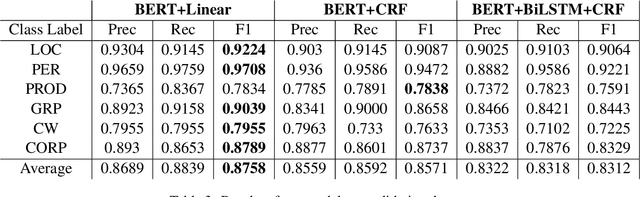

We investigate the task of complex NER for the English language. The task is non-trivial due to the semantic ambiguity of the textual structure and the rarity of occurrence of such entities in the prevalent literature. Using pre-trained language models such as BERT, we obtain a competitive performance on this task. We qualitatively analyze the performance of multiple architectures for this task. All our models are able to outperform the baseline by a significant margin. Our best performing model beats the baseline F1-score by over 9%.
ArduCode: Predictive Framework for Automation Engineering
Sep 11, 2019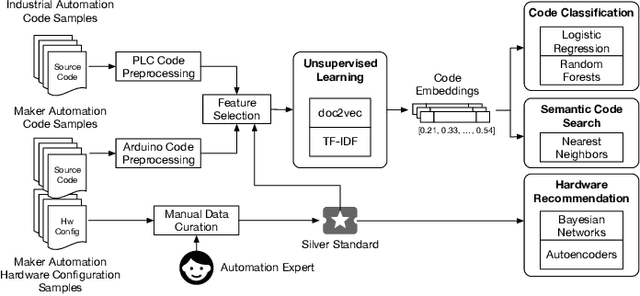
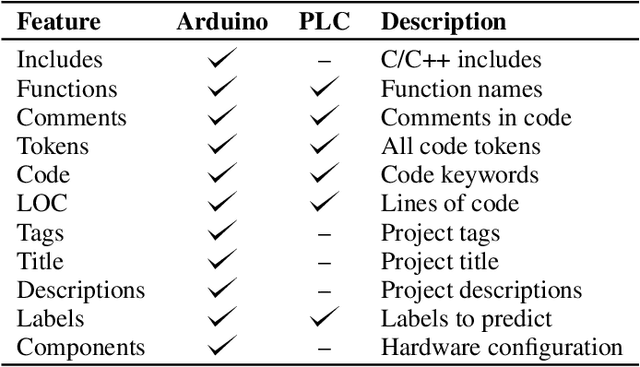
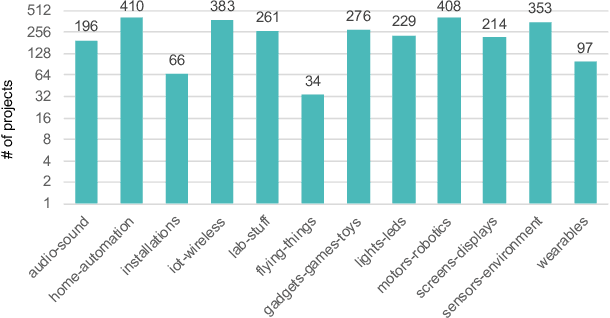
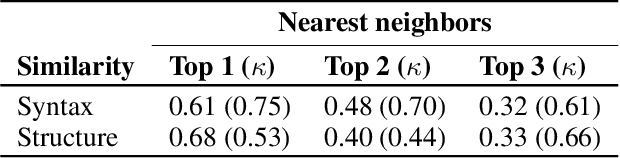
Automation engineering is the task of integrating, via software, various sensors, actuators, and controls for automating a real-world process. Today, automation engineering is supported by a suite of software tools including integrated development environments (IDE), hardware configurators, compilers, and runtimes. These tools focus on the automation code itself, but leave the automation engineer unassisted in their decision making. This can lead to increased time for software development because of imperfections in decision making leading to multiple iterations between software and hardware. To address this, this paper defines multiple challenges often faced in automation engineering and propose solutions using machine learning to assist engineers tackle such challenges. We show that machine learning can be leveraged to assist the automation engineer in classifying automation, finding similar code snippets, and reasoning about the hardware selection of sensors and actuators. We validate our architecture on two real datasets consisting of 2,927 Arduino projects, and 683 Programmable Logic Controller (PLC) projects. Our results show that paragraph embedding techniques can be utilized to classify automation using code snippets with precision close to human annotation, giving an F1-score of 72%. Further, we show that such embedding techniques can help us find similar code snippets with high accuracy. Finally, we use autoencoder models for hardware recommendation and achieve a p@3 of 0.79 and p@5 of 0.95.