 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysing the Resourcefulness of the Paragraph for Precedence Retrieval
Jul 29, 2023

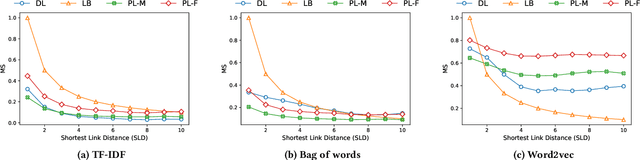
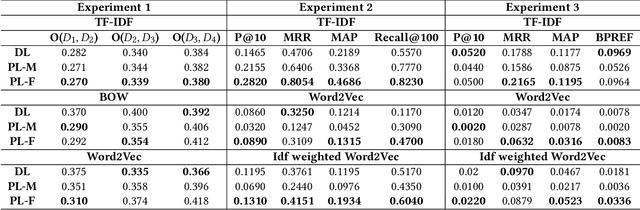
Developing methods for extracting relevant legal information to aid legal practitioners is an active research area. In this regard, research efforts are being made by leveraging different kinds of information, such as meta-data, citations, keywords, sentences, paragraphs, etc. Similar to any text document, legal documents are composed of paragraphs. In this paper, we have analyzed the resourcefulness of paragraph-level information in capturing similarity among judgments for improving the performance of precedence retrieval. We found that the paragraph-level methods could capture the similarity among the judgments with only a few paragraph interactions and exhibit more discriminating power over the baseline document-level method. Moreover, the comparison results on two benchmark datasets for the precedence retrieval on the Indian supreme court judgments task show that the paragraph-level methods exhibit comparable performance with the state-of-the-art methods
Multilinguals at SemEval-2022 Task 11: Complex NER in Semantically Ambiguous Settings for Low Resource Languages
Jul 14, 2022
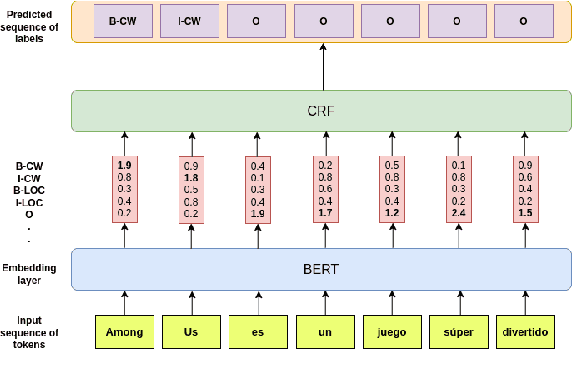

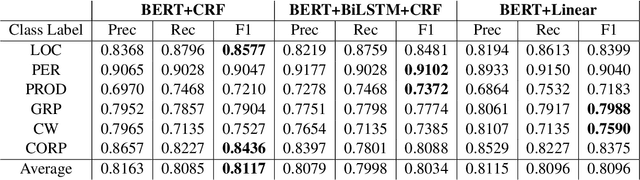
We leverage pre-trained language models to solve the task of complex NER for two low-resource languages: Chinese and Spanish. We use the technique of Whole Word Masking(WWM) to boost the performance of masked language modeling objective on large and unsupervised corpora. We experiment with multiple neural network architectures, incorporating CRF, BiLSTMs, and Linear Classifiers on top of a fine-tuned BERT layer. All our models outperform the baseline by a significant margin and our best performing model obtains a competitive position on the evaluation leaderboard for the blind test set.