 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting LLM Reasoning with Dynamic Notes Writing for Complex QA
May 22, 2025

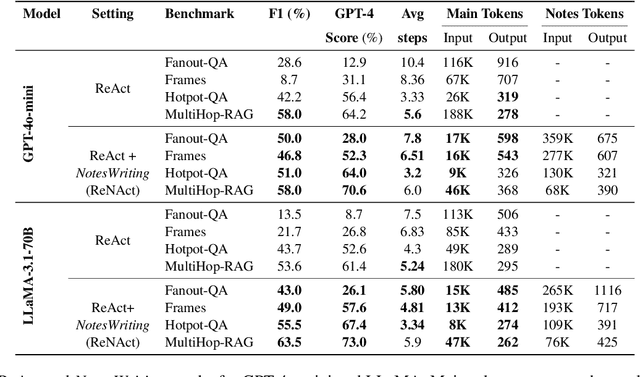
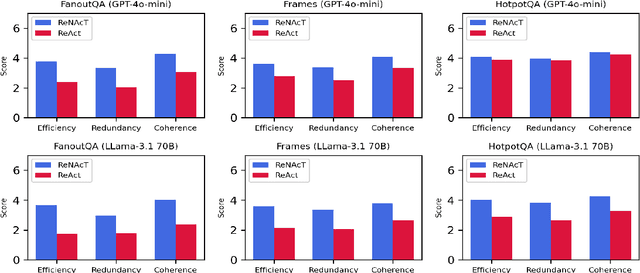
Iterative RAG for multi-hop question answering faces challenges with lengthy contexts and the buildup of irrelevant information. This hinders a model's capacity to process and reason over retrieved content and limits performance. While recent methods focus on compressing retrieved information, they are either restricted to single-round RAG, require finetuning or lack scalability in iterative RAG. To address these challenges, we propose Notes Writing, a method that generates concise and relevant notes from retrieved documents at each step, thereby reducing noise and retaining only essential information. This indirectly increases the effective context length of Large Language Models (LLMs), enabling them to reason and plan more effectively while processing larger volumes of input text. Notes Writing is framework agnostic and can be integrated with different iterative RAG methods. We demonstrate its effectiveness with three iterative RAG methods, across two models and four evaluation datasets. Notes writing yields an average improvement of 15.6 percentage points overall, with minimal increase in output tokens.
Prompting with Phonemes: Enhancing LLM Multilinguality for non-Latin Script Languages
Nov 04, 2024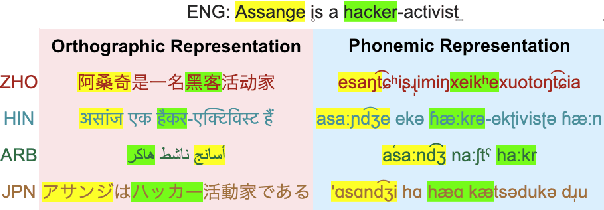

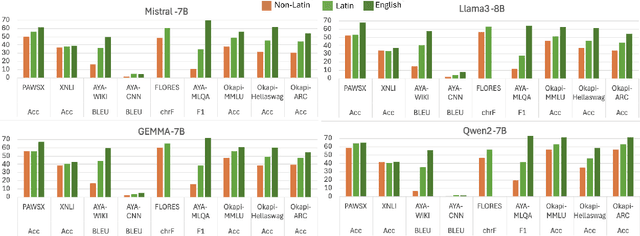

Multilingual LLMs have achieved remarkable benchmark performance, but we find they continue to underperform on non-Latin script languages across contemporary LLM families. This discrepancy arises from the fact that LLMs are pretrained with orthographic scripts, which are dominated by Latin characters that obscure their shared phonology with non-Latin scripts. We propose leveraging phonemic transcriptions as complementary signals to induce script-invariant representations. Our study demonstrates that integrating phonemic signals improves performance across both non-Latin and Latin languages, with a particularly significant impact on closing the performance gap between the two. Through detailed experiments, we show that phonemic and orthographic scripts retrieve distinct examples for in-context learning (ICL). This motivates our proposed Mixed-ICL retrieval strategy, where further aggregation leads to our significant performance improvements for both Latin script languages (up to 12.6%) and non-Latin script languages (up to 15.1%) compared to randomized ICL retrieval.
M2Lingual: Enhancing Multilingual, Multi-Turn Instruction Alignment in Large Language Models
Jun 24, 2024



Instruction finetuning (IFT) is critical for aligning Large Language Models (LLMs) to follow instructions. Numerous effective IFT datasets have been proposed in the recent past, but most focus on high resource languages such as English. In this work, we propose a fully synthetic, novel taxonomy (Evol) guided Multilingual, Multi-turn instruction finetuning dataset, called M2Lingual, to better align LLMs on a diverse set of languages and tasks. M2Lingual contains a total of 182K IFT pairs that are built upon diverse seeds, covering 70 languages, 17 NLP tasks and general instruction-response pairs. LLMs finetuned with M2Lingual substantially outperform the majority of existing multilingual IFT datasets. Importantly, LLMs trained with M2Lingual consistently achieve competitive results across a wide variety of evaluation benchmarks compared to existing multilingual IFT datasets. Specifically, LLMs finetuned with M2Lingual achieve strong performance on our translated multilingual, multi-turn evaluation benchmark as well as a wide variety of multilingual tasks. Thus we contribute, and the 2 step Evol taxonomy used for its creation. M2Lingual repository - https://huggingface.co/datasets/ServiceNow-AI/M2Lingual
The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics
Feb 03, 2021
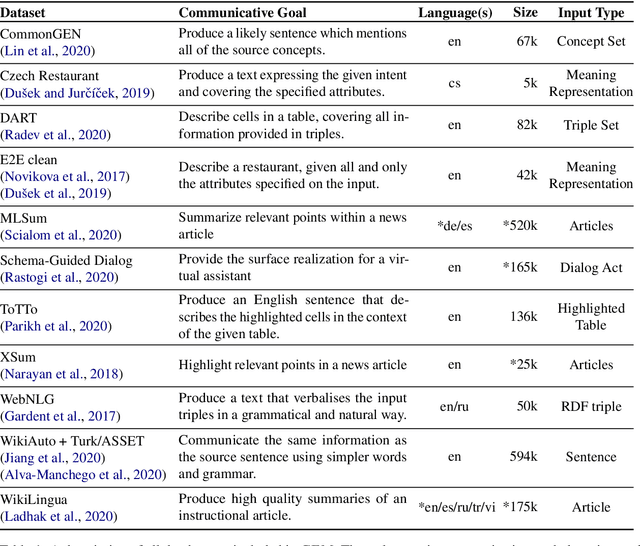
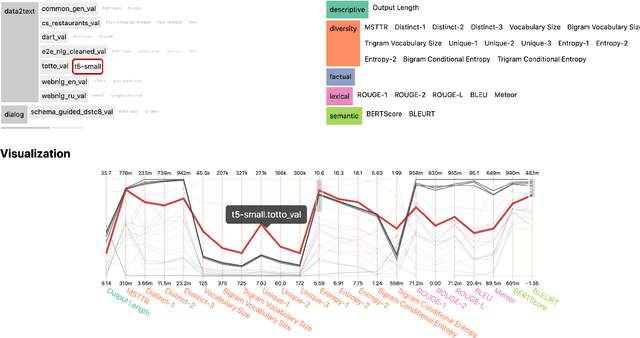
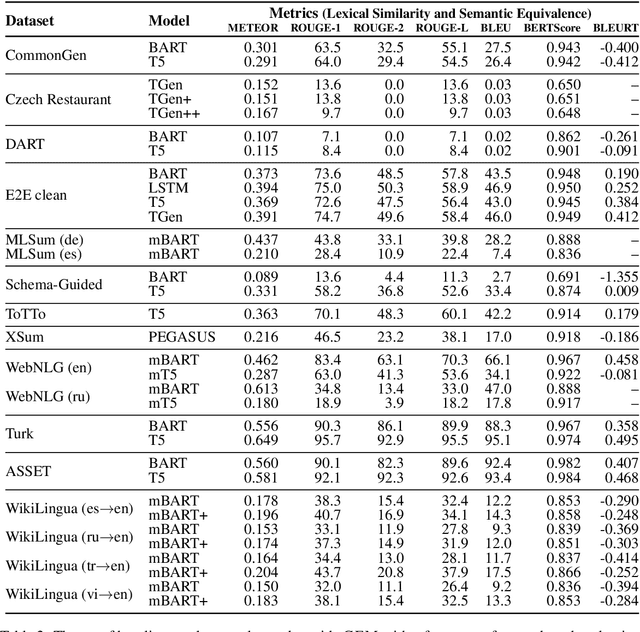
We introduce GEM, a living benchmark for natural language Generation (NLG), its Evaluation, and Metrics. Measuring progress in NLG relies on a constantly evolving ecosystem of automated metrics, datasets, and human evaluation standards. However, due to this moving target, new models often still evaluate on divergent anglo-centric corpora with well-established, but flawed, metrics. This disconnect makes it challenging to identify the limitations of current models and opportunities for progress. Addressing this limitation, GEM provides an environment in which models can easily be applied to a wide set of corpora and evaluation strategies can be tested. Regular updates to the benchmark will help NLG research become more multilingual and evolve the challenge alongside models. This paper serves as the description of the initial release for which we are organizing a shared task at our ACL 2021 Workshop and to which we invite the entire NLG community to participate.