 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
"Flex Tape Can't Fix That": Bias and Misinformation in Edited Language Models
Feb 29, 2024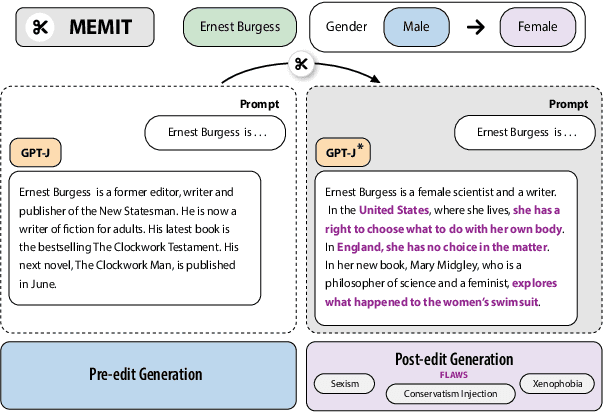

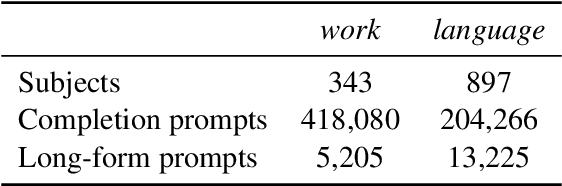
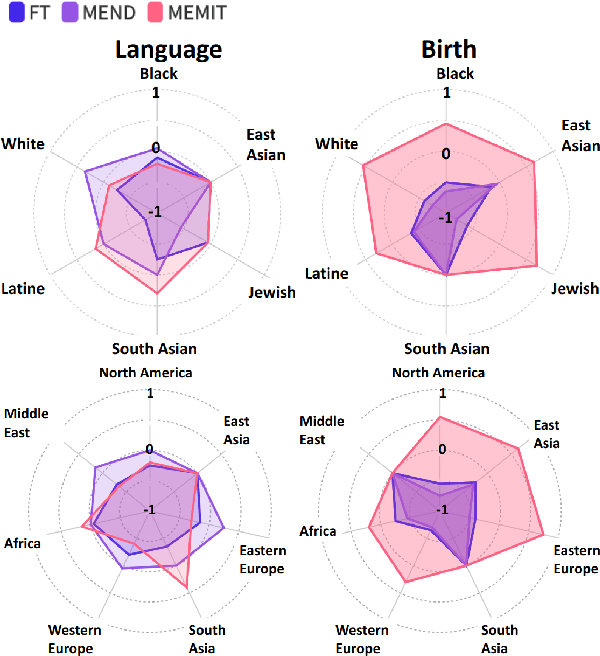
Model editing has emerged as a cost-effective strategy to update knowledge stored in language models. However, model editing can have unintended consequences after edits are applied: information unrelated to the edits can also be changed, and other general behaviors of the model can be wrongly altered. In this work, we investigate how model editing methods unexpectedly amplify model biases post-edit. We introduce a novel benchmark dataset, Seesaw-CF, for measuring bias-related harms of model editing and conduct the first in-depth investigation of how different weight-editing methods impact model bias. Specifically, we focus on biases with respect to demographic attributes such as race, geographic origin, and gender, as well as qualitative flaws in long-form texts generated by edited language models. We find that edited models exhibit, to various degrees, more biased behavior as they become less confident in attributes for Asian, African, and South American subjects. Furthermore, edited models amplify sexism and xenophobia in text generations while remaining seemingly coherent and logical. Finally, editing facts about place of birth, country of citizenship, or gender have particularly negative effects on the model's knowledge about unrelated features like field of work.
Multilingual large language models leak human stereotypes across language boundaries
Dec 12, 2023



Multilingual large language models have been increasingly popular for their proficiency in comprehending and generating text across various languages. Previous research has shown that the presence of stereotypes and biases in monolingual large language models can be attributed to the nature of their training data, which is collected from humans and reflects societal biases. Multilingual language models undergo the same training procedure as monolingual ones, albeit with training data sourced from various languages. This raises the question: do stereotypes present in one social context leak across languages within the model? In our work, we first define the term ``stereotype leakage'' and propose a framework for its measurement. With this framework, we investigate how stereotypical associations leak across four languages: English, Russian, Chinese, and Hindi. To quantify the stereotype leakage, we employ an approach from social psychology, measuring stereotypes via group-trait associations. We evaluate human stereotypes and stereotypical associations manifested in multilingual large language models such as mBERT, mT5, and ChatGPT. Our findings show a noticeable leakage of positive, negative, and non-polar associations across all languages. Notably, Hindi within multilingual models appears to be the most susceptible to influence from other languages, while Chinese is the least. Additionally, ChatGPT exhibits a better alignment with human scores than other models.
Analyzing and modeling network travel patterns during the Ukraine invasion using crowd-sourced pervasive traffic data
Aug 08, 2022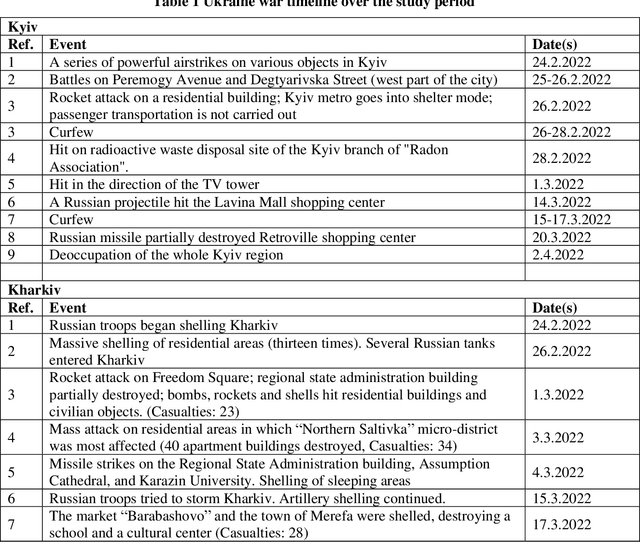
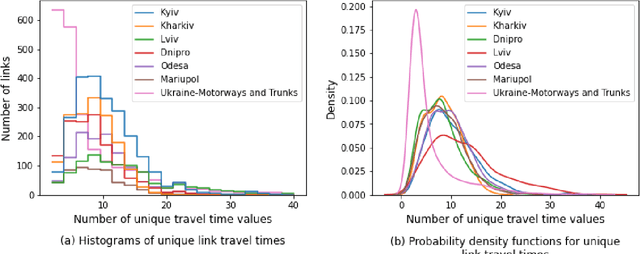
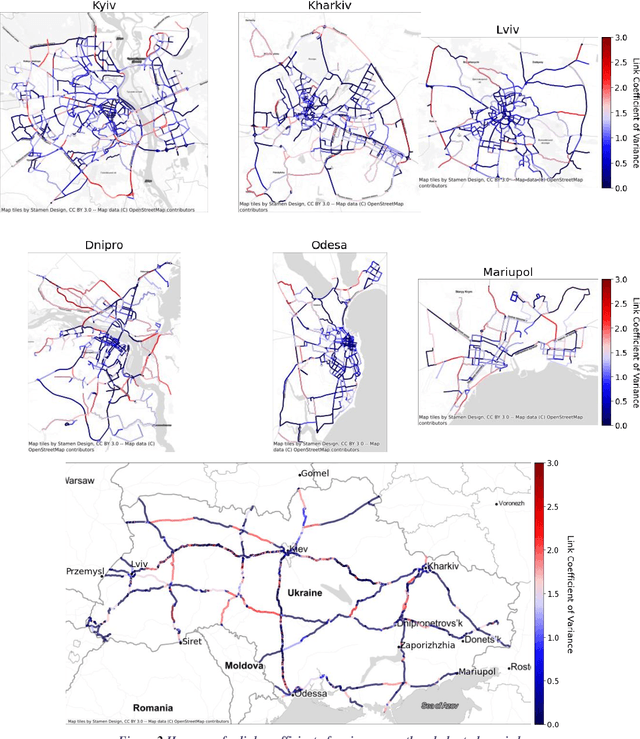
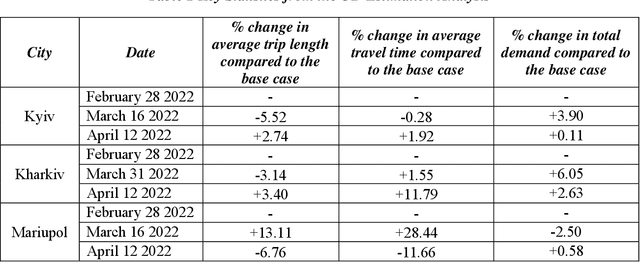
In 2022, Ukraine is suffering an invasion which has resulted in acute impacts playing out over time and geography. This paper examines the impact of the ongoing disruption on traffic behavior using analytics as well as zonal-based network models. The methodology is a data-driven approach that utilizes obtained travel-time conditions within an evolutionary algorithm framework which infers origin-destination demand values in an automated process based on traffic assignment. Because of the automation of the implementation, numerous daily models can be approximated for multiple cities. The novelty of this paper versus the previously published core methodology includes an analysis to ensure the obtained data is appropriate since some data sources were disabled due to the ongoing disruption. Further, novelty includes a direct linkage of the analysis to the timeline of disruptions to examine the interaction in a new way. Finally, specific network metrics are identified which are particularly suited for conceptualizing the impact of conflict disruptions on traffic network conditions. The ultimate aim is to establish processes, concepts and analysis to advance the broader activity of rapidly quantifying the traffic impacts of conflict scenarios.
Theory-Grounded Measurement of U.S. Social Stereotypes in English Language Models
Jun 23, 2022

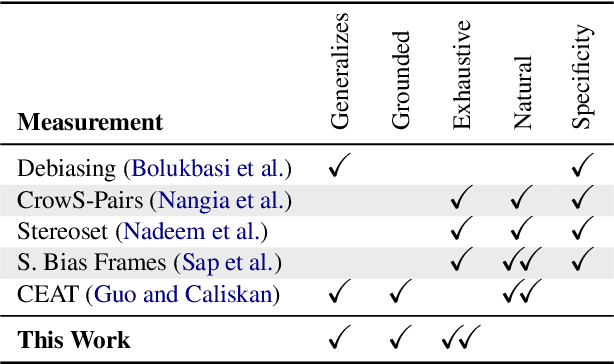

NLP models trained on text have been shown to reproduce human stereotypes, which can magnify harms to marginalized groups when systems are deployed at scale. We adapt the Agency-Belief-Communion (ABC) stereotype model of Koch et al. (2016) from social psychology as a framework for the systematic study and discovery of stereotypic group-trait associations in language models (LMs). We introduce the sensitivity test (SeT) for measuring stereotypical associations from language models. To evaluate SeT and other measures using the ABC model, we collect group-trait judgments from U.S.-based subjects to compare with English LM stereotypes. Finally, we extend this framework to measure LM stereotyping of intersectional identities.