 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrosscoding Through Time: Tracking Emergence & Consolidation Of Linguistic Representations Throughout LLM Pretraining
Sep 05, 2025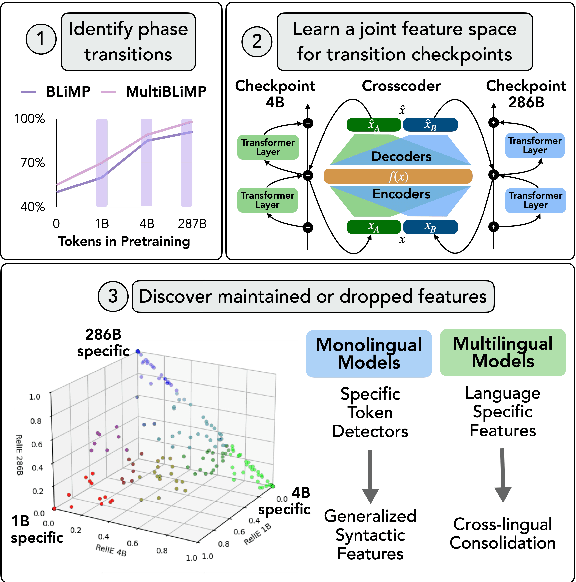
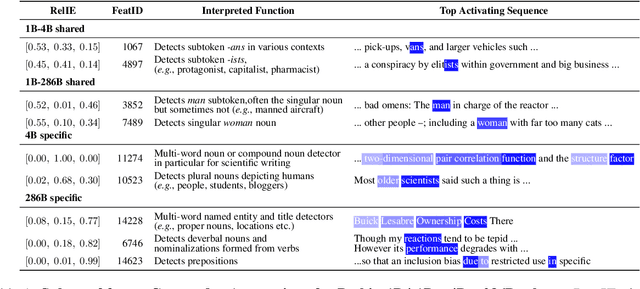
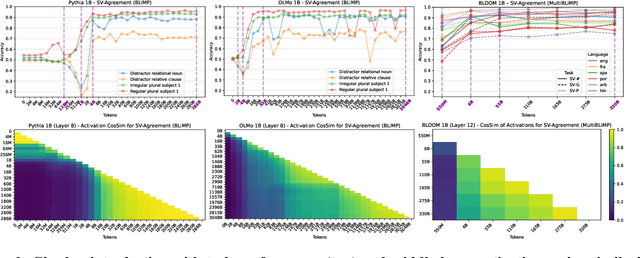

Large language models (LLMs) learn non-trivial abstractions during pretraining, like detecting irregular plural noun subjects. However, it is not well understood when and how specific linguistic abilities emerge as traditional evaluation methods such as benchmarking fail to reveal how models acquire concepts and capabilities. To bridge this gap and better understand model training at the concept level, we use sparse crosscoders to discover and align features across model checkpoints. Using this approach, we track the evolution of linguistic features during pretraining. We train crosscoders between open-sourced checkpoint triplets with significant performance and representation shifts, and introduce a novel metric, Relative Indirect Effects (RelIE), to trace training stages at which individual features become causally important for task performance. We show that crosscoders can detect feature emergence, maintenance, and discontinuation during pretraining. Our approach is architecture-agnostic and scalable, offering a promising path toward more interpretable and fine-grained analysis of representation learning throughout pretraining.
Could ChatGPT get an Engineering Degree? Evaluating Higher Education Vulnerability to AI Assistants
Aug 07, 2024



AI assistants are being increasingly used by students enrolled in higher education institutions. While these tools provide opportunities for improved teaching and education, they also pose significant challenges for assessment and learning outcomes. We conceptualize these challenges through the lens of vulnerability, the potential for university assessments and learning outcomes to be impacted by student use of generative AI. We investigate the potential scale of this vulnerability by measuring the degree to which AI assistants can complete assessment questions in standard university-level STEM courses. Specifically, we compile a novel dataset of textual assessment questions from 50 courses at EPFL and evaluate whether two AI assistants, GPT-3.5 and GPT-4 can adequately answer these questions. We use eight prompting strategies to produce responses and find that GPT-4 answers an average of 65.8% of questions correctly, and can even produce the correct answer across at least one prompting strategy for 85.1% of questions. When grouping courses in our dataset by degree program, these systems already pass non-project assessments of large numbers of core courses in various degree programs, posing risks to higher education accreditation that will be amplified as these models improve. Our results call for revising program-level assessment design in higher education in light of advances in generative AI.
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023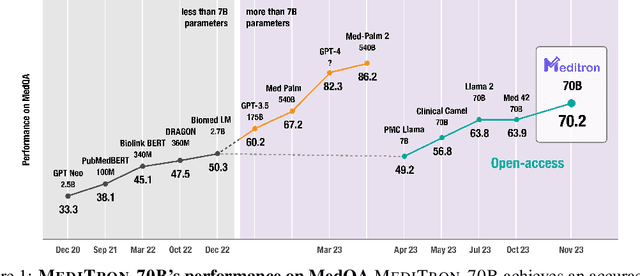
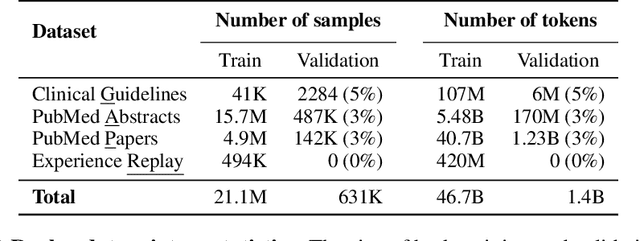
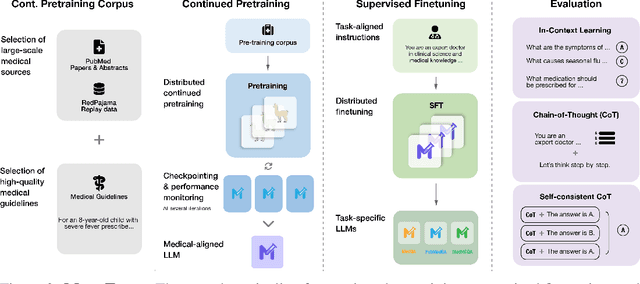

Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
Discovering Knowledge-Critical Subnetworks in Pretrained Language Models
Oct 04, 2023



Pretrained language models (LMs) encode implicit representations of knowledge in their parameters. However, localizing these representations and disentangling them from each other remains an open problem. In this work, we investigate whether pretrained language models contain various knowledge-critical subnetworks: particular sparse computational subgraphs responsible for encoding specific knowledge the model has memorized. We propose a multi-objective differentiable weight masking scheme to discover these subnetworks and show that we can use them to precisely remove specific knowledge from models while minimizing adverse effects on the behavior of the original language model. We demonstrate our method on multiple GPT2 variants, uncovering highly sparse subnetworks (98%+) that are solely responsible for specific collections of relational knowledge. When these subnetworks are removed, the remaining network maintains most of its initial capacity (modeling language and other memorized relational knowledge) but struggles to express the removed knowledge, and suffers performance drops on examples needing this removed knowledge on downstream tasks after finetuning.
PeaCoK: Persona Commonsense Knowledge for Consistent and Engaging Narratives
May 03, 2023



Sustaining coherent and engaging narratives requires dialogue or storytelling agents to understand how the personas of speakers or listeners ground the narrative. Specifically, these agents must infer personas of their listeners to produce statements that cater to their interests. They must also learn to maintain consistent speaker personas for themselves throughout the narrative, so that their counterparts feel involved in a realistic conversation or story. However, personas are diverse and complex: they entail large quantities of rich interconnected world knowledge that is challenging to robustly represent in general narrative systems (e.g., a singer is good at singing, and may have attended conservatoire). In this work, we construct a new large-scale persona commonsense knowledge graph, PeaCoK, containing ~100K human-validated persona facts. Our knowledge graph schematizes five dimensions of persona knowledge identified in previous studies of human interactive behaviours, and distils facts in this schema from both existing commonsense knowledge graphs and large-scale pretrained language models. Our analysis indicates that PeaCoK contains rich and precise world persona inferences that help downstream systems generate more consistent and engaging narratives.
Spatial Language Understanding for Object Search in Partially Observed Cityscale Environments
Dec 04, 2020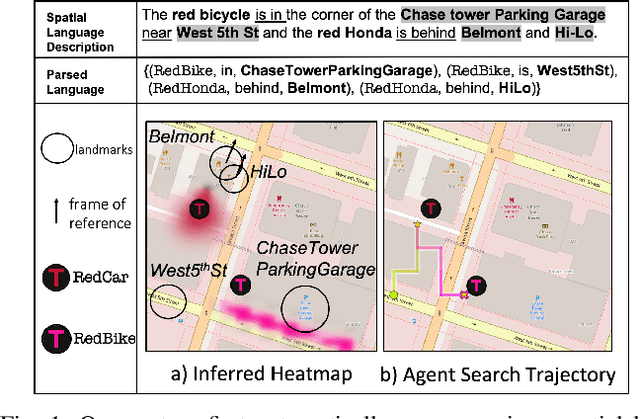
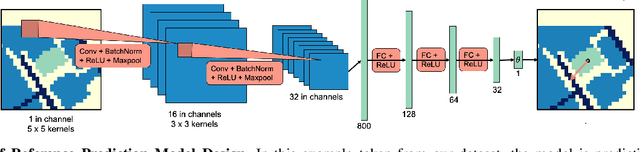
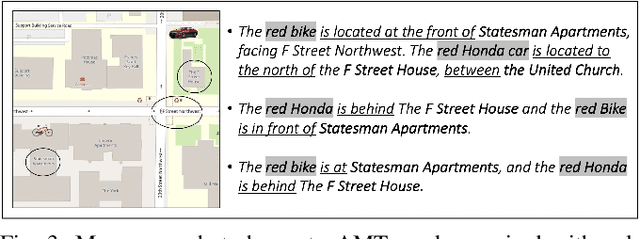
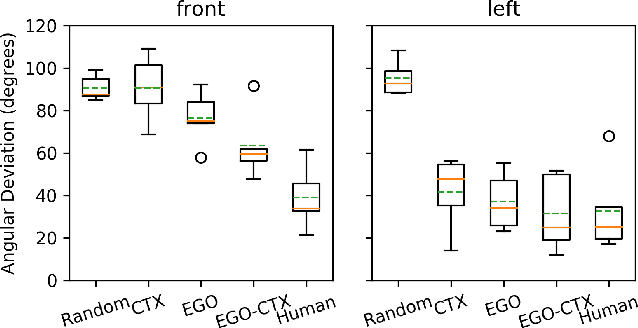
We present a system that enables robots to interpret spatial language as a distribution over object locations for effective search in partially observable cityscale environments. We introduce the spatial language observation space and formulate a stochastic observation model under the framework of Partially Observable Markov Decision Process (POMDP) which incorporates information extracted from the spatial language into the robot's belief. To interpret ambiguous, context-dependent prepositions (e.g.~front), we propose a convolutional neural network model that learns to predict the language provider's relative frame of reference (FoR) given environment context. We demonstrate the generalizability of our FoR prediction model and object search system through cross-validation over areas of five cities, each with a 40,000m$^2$ footprint. End-to-end experiments in simulation show that our system achieves faster search and higher success rate compared to a keyword-based baseline without spatial preposition understanding.