 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual large language models leak human stereotypes across language boundaries
Dec 12, 2023



Multilingual large language models have been increasingly popular for their proficiency in comprehending and generating text across various languages. Previous research has shown that the presence of stereotypes and biases in monolingual large language models can be attributed to the nature of their training data, which is collected from humans and reflects societal biases. Multilingual language models undergo the same training procedure as monolingual ones, albeit with training data sourced from various languages. This raises the question: do stereotypes present in one social context leak across languages within the model? In our work, we first define the term ``stereotype leakage'' and propose a framework for its measurement. With this framework, we investigate how stereotypical associations leak across four languages: English, Russian, Chinese, and Hindi. To quantify the stereotype leakage, we employ an approach from social psychology, measuring stereotypes via group-trait associations. We evaluate human stereotypes and stereotypical associations manifested in multilingual large language models such as mBERT, mT5, and ChatGPT. Our findings show a noticeable leakage of positive, negative, and non-polar associations across all languages. Notably, Hindi within multilingual models appears to be the most susceptible to influence from other languages, while Chinese is the least. Additionally, ChatGPT exhibits a better alignment with human scores than other models.
Seamful XAI: Operationalizing Seamful Design in Explainable AI
Nov 12, 2022



Mistakes in AI systems are inevitable, arising from both technical limitations and sociotechnical gaps. While black-boxing AI systems can make the user experience seamless, hiding the seams risks disempowering users to mitigate fallouts from AI mistakes. While Explainable AI (XAI) has predominantly tackled algorithmic opaqueness, we propose that seamful design can foster Humancentered XAI by strategically revealing sociotechnical and infrastructural mismatches. We introduce the notion of Seamful XAI by (1) conceptually transferring "seams" to the AI context and (2) developing a design process that helps stakeholders design with seams, thereby augmenting explainability and user agency. We explore this process with 43 AI practitioners and users, using a scenario-based co-design activity informed by real-world use cases. We share empirical insights, implications, and critical reflections on how this process can help practitioners anticipate and craft seams in AI, how seamfulness can improve explainability, empower end-users, and facilitate Responsible AI.
Content Selection in Deep Learning Models of Summarization
Oct 29, 2018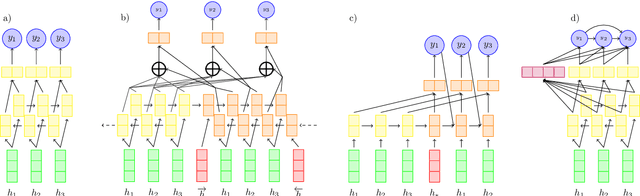
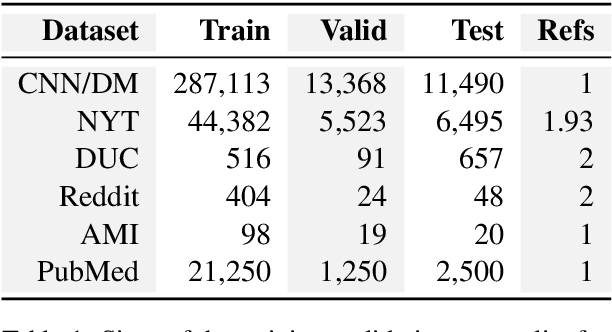
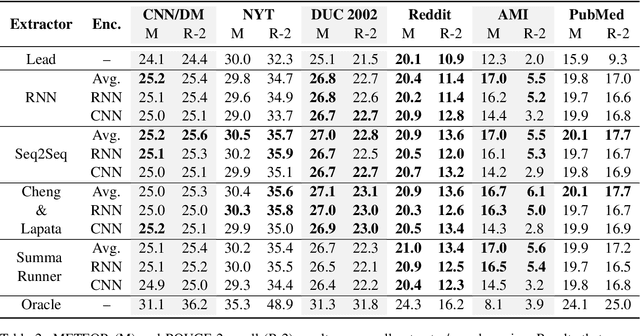
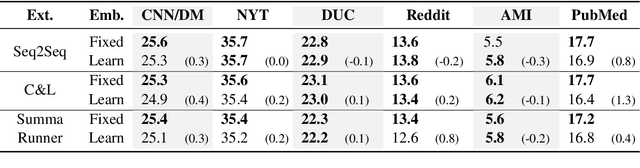
We carry out experiments with deep learning models of summarization across the domains of news, personal stories, meetings, and medical articles in order to understand how content selection is performed. We find that many sophisticated features of state of the art extractive summarizers do not improve performance over simpler models. These results suggest that it is easier to create a summarizer for a new domain than previous work suggests and bring into question the benefit of deep learning models for summarization for those domains that do have massive datasets (i.e., news). At the same time, they suggest important questions for new research in summarization; namely, new forms of sentence representations or external knowledge sources are needed that are better suited to the summarization task.
Active Learning for Cost-Sensitive Classification
Nov 13, 2017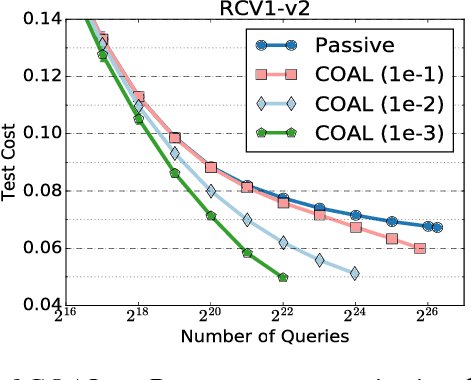
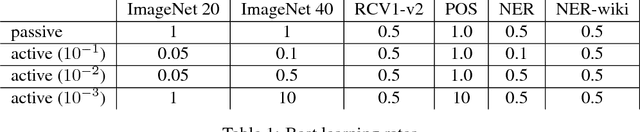
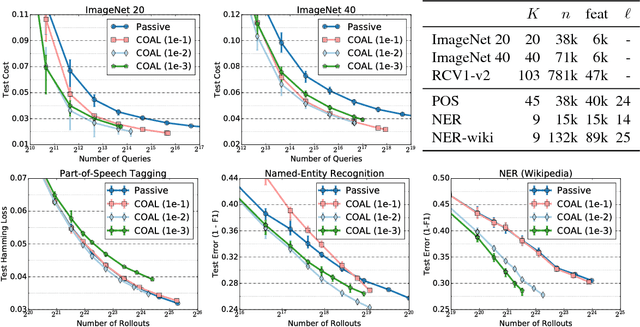
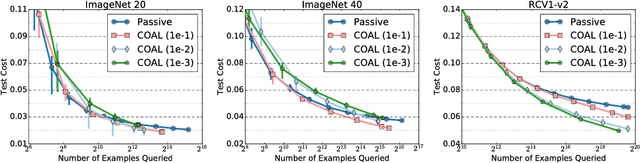
We design an active learning algorithm for cost-sensitive multiclass classification: problems where different errors have different costs. Our algorithm, COAL, makes predictions by regressing to each label's cost and predicting the smallest. On a new example, it uses a set of regressors that perform well on past data to estimate possible costs for each label. It queries only the labels that could be the best, ignoring the sure losers. We prove COAL can be efficiently implemented for any regression family that admits squared loss optimization; it also enjoys strong guarantees with respect to predictive performance and labeling effort. We empirically compare COAL to passive learning and several active learning baselines, showing significant improvements in labeling effort and test cost on real-world datasets.
Logarithmic Time One-Against-Some
Dec 01, 2016


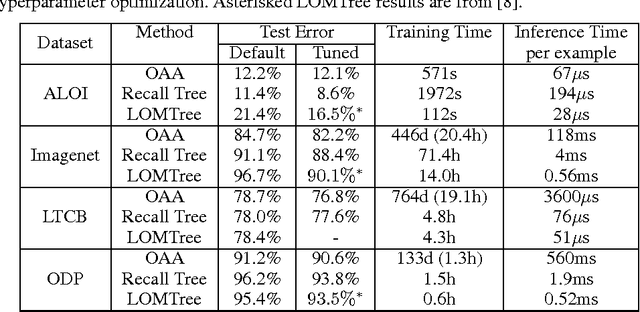
We create a new online reduction of multiclass classification to binary classification for which training and prediction time scale logarithmically with the number of classes. Compared to previous approaches, we obtain substantially better statistical performance for two reasons: First, we prove a tighter and more complete boosting theorem, and second we translate the results more directly into an algorithm. We show that several simple techniques give rise to an algorithm that can compete with one-against-all in both space and predictive power while offering exponential improvements in speed when the number of classes is large.
Ask, and shall you receive?: Understanding Desire Fulfillment in Natural Language Text
Nov 30, 2015
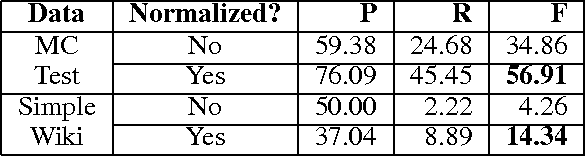

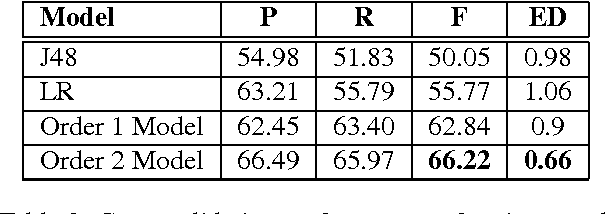
The ability to comprehend wishes or desires and their fulfillment is important to Natural Language Understanding. This paper introduces the task of identifying if a desire expressed by a subject in a given short piece of text was fulfilled. We propose various unstructured and structured models that capture fulfillment cues such as the subject's emotional state and actions. Our experiments with two different datasets demonstrate the importance of understanding the narrative and discourse structure to address this task.
Modeling Dynamic Relationships Between Characters in Literary Novels
Nov 30, 2015

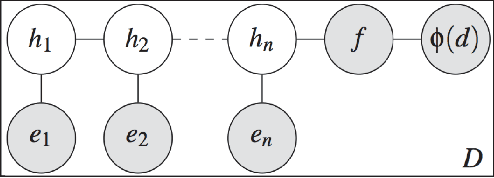
Studying characters plays a vital role in computationally representing and interpreting narratives. Unlike previous work, which has focused on inferring character roles, we focus on the problem of modeling their relationships. Rather than assuming a fixed relationship for a character pair, we hypothesize that relationships are dynamic and temporally evolve with the progress of the narrative, and formulate the problem of relationship modeling as a structured prediction problem. We propose a semi-supervised framework to learn relationship sequences from fully as well as partially labeled data. We present a Markovian model capable of accumulating historical beliefs about the relationship and status changes. We use a set of rich linguistic and semantically motivated features that incorporate world knowledge to investigate the textual content of narrative. We empirically demonstrate that such a framework outperforms competitive baselines.
Parser for Abstract Meaning Representation using Learning to Search
Oct 26, 2015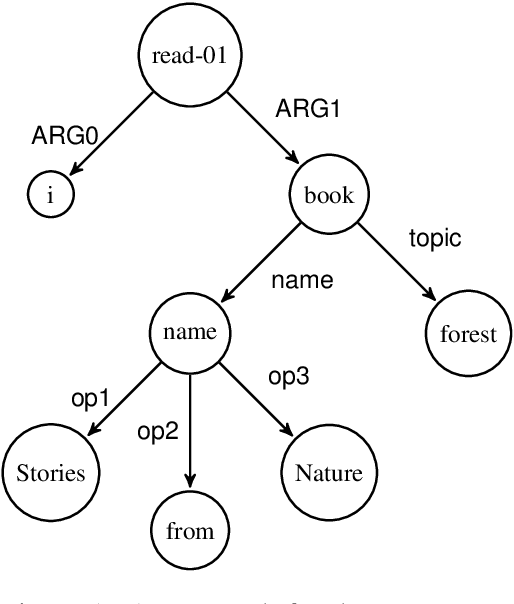
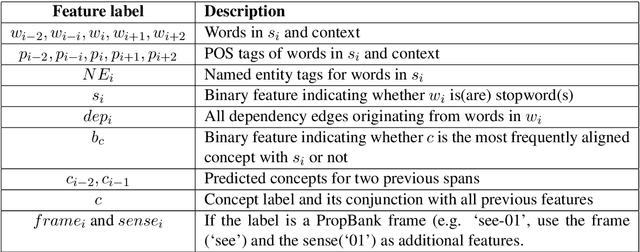
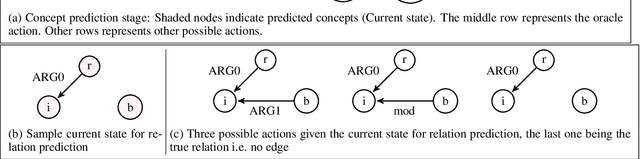

We develop a novel technique to parse English sentences into Abstract Meaning Representation (AMR) using SEARN, a Learning to Search approach, by modeling the concept and the relation learning in a unified framework. We evaluate our parser on multiple datasets from varied domains and show an absolute improvement of 2% to 6% over the state-of-the-art. Additionally we show that using the most frequent concept gives us a baseline that is stronger than the state-of-the-art for concept prediction. We plan to release our parser for public use.
Bayesian Multitask Learning with Latent Hierarchies
Aug 09, 2014

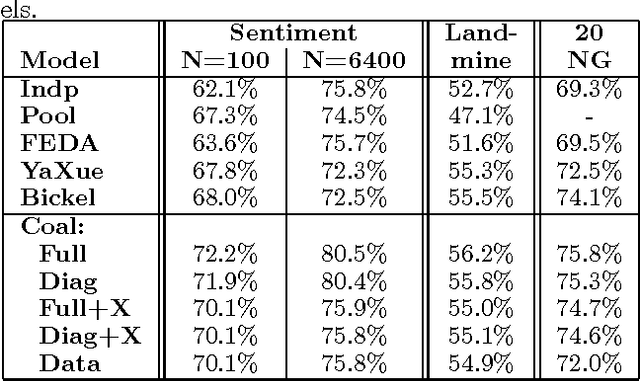

We learn multiple hypotheses for related tasks under a latent hierarchical relationship between tasks. We exploit the intuition that for domain adaptation, we wish to share classifier structure, but for multitask learning, we wish to share covariance structure. Our hierarchical model is seen to subsume several previously proposed multitask learning models and performs well on three distinct real-world data sets.
Learning Task Grouping and Overlap in Multi-task Learning
Jun 27, 2012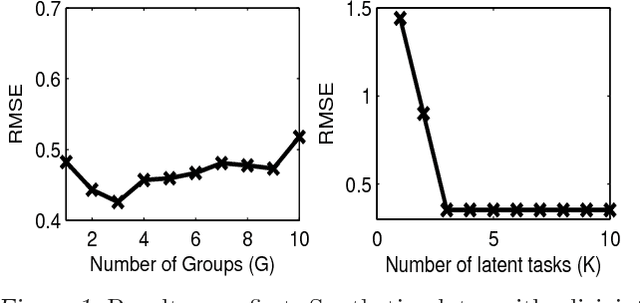

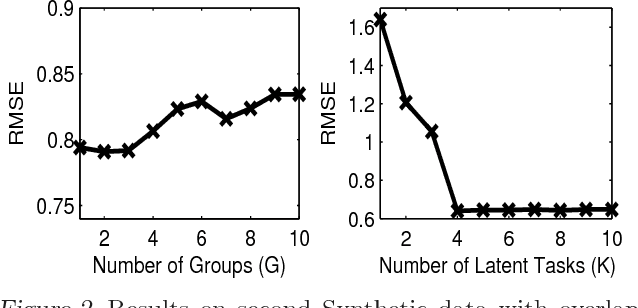

In the paradigm of multi-task learning, mul- tiple related prediction tasks are learned jointly, sharing information across the tasks. We propose a framework for multi-task learn- ing that enables one to selectively share the information across the tasks. We assume that each task parameter vector is a linear combi- nation of a finite number of underlying basis tasks. The coefficients of the linear combina- tion are sparse in nature and the overlap in the sparsity patterns of two tasks controls the amount of sharing across these. Our model is based on on the assumption that task pa- rameters within a group lie in a low dimen- sional subspace but allows the tasks in differ- ent groups to overlap with each other in one or more bases. Experimental results on four datasets show that our approach outperforms competing methods.