 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"So There's a Catch-22 Here": How Early Adopters Who Build Multi-Agent LLM Systems Conceptualize Transparency
Jun 06, 2026Multi-agent large language model (LLM) systems are rapidly emerging, yet transparency, a cornerstone of responsible AI, remains under-defined in these distributed architectures, which have complexities of inter-agent coordination and orchestration. In this paper, we present one of the first empirical study of how early adopters of multi-agent LLM systems, who are both the builders and users, understand and practice transparency. We conducted semi-structured interviews with 13 early adopters in [Large Technology Organization] and applied thematic analysis to identify recurring patterns. Participants articulated divergent yet complementary framings of transparency, including reproducibility, debugging, boundary-setting, visualization, and auditing. These perspectives spanned questions of what transparency entails, why it matters, and how it is achieved. We synthesize these into a multidimensional framework, which is developer, user, and governance-focused positioning transparency as a situated socio-technical practice that informs future HCI and AI design and research around aligning expectations and capacities of their intended audiences.
Human oversight of agentic systems in practice: Examining the oversight work, challenges, and heuristics of developers using software agents
Jun 03, 2026Autonomous software agents hold promise to increase developer productivity but make mistakes and exhibit novel failure modes, making human oversight central to successful human-agent collaboration. Existing research on agent oversight is largely conceptual; normative frameworks exist, but how users actually oversee agents is less known. In this paper, we bridge this gap by providing early empirical anchors for the theoretical discourse on agent oversight. Drawing on interviews with 17 experienced developers, we conduct an exploratory inquiry examining what forms of emergent oversight work developers perform, when, and how. We also document the oversight challenges developers face and the strategies they have started using to address them. We found at least four forms of emergent oversight work: a priori control, co-planning, real-time monitoring, and post hoc review. We show that oversight work is not only reactive and retrospective, as portrayed in existing research, but also preventative and proactive. We describe situated oversight challenges (e.g., difficulty reviewing agent-generated code) and outline heuristics developers adopt to address such challenges (e.g., using test results as guarantees for code correctness). We conclude with high-level takeaways, future research directions, implications for the human-centered design of software agents and for software engineering practice, and limitations of our research.
From Future of Work to Future of Workers: Addressing Asymptomatic AI Harms for Dignified Human-AI Interaction
Jan 29, 2026In the future of work discourse, AI is touted as the ultimate productivity amplifier. Yet, beneath the efficiency gains lie subtle erosions of human expertise and agency. This paper shifts focus from the future of work to the future of workers by navigating the AI-as-Amplifier Paradox: AI's dual role as enhancer and eroder, simultaneously strengthening performance while eroding underlying expertise. We present a year-long study on the longitudinal use of AI in a high-stakes workplace among cancer specialists. Initial operational gains hid ``intuition rust'': the gradual dulling of expert judgment. These asymptomatic effects evolved into chronic harms, such as skill atrophy and identity commoditization. Building on these findings, we offer a framework for dignified Human-AI interaction co-constructed with professional knowledge workers facing AI-induced skill erosion without traditional labor protections. The framework operationalizes sociotechnical immunity through dual-purpose mechanisms that serve institutional quality goals while building worker power to detect, contain, and recover from skill erosion, and preserve human identity. Evaluated across healthcare and software engineering, our work takes a foundational step toward dignified human-AI interaction futures by balancing productivity with the preservation of human expertise.
Seamful XAI: Operationalizing Seamful Design in Explainable AI
Nov 12, 2022



Mistakes in AI systems are inevitable, arising from both technical limitations and sociotechnical gaps. While black-boxing AI systems can make the user experience seamless, hiding the seams risks disempowering users to mitigate fallouts from AI mistakes. While Explainable AI (XAI) has predominantly tackled algorithmic opaqueness, we propose that seamful design can foster Humancentered XAI by strategically revealing sociotechnical and infrastructural mismatches. We introduce the notion of Seamful XAI by (1) conceptually transferring "seams" to the AI context and (2) developing a design process that helps stakeholders design with seams, thereby augmenting explainability and user agency. We explore this process with 43 AI practitioners and users, using a scenario-based co-design activity informed by real-world use cases. We share empirical insights, implications, and critical reflections on how this process can help practitioners anticipate and craft seams in AI, how seamfulness can improve explainability, empower end-users, and facilitate Responsible AI.
The Who in Explainable AI: How AI Background Shapes Perceptions of AI Explanations
Jul 28, 2021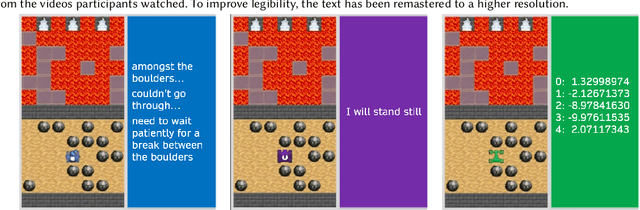
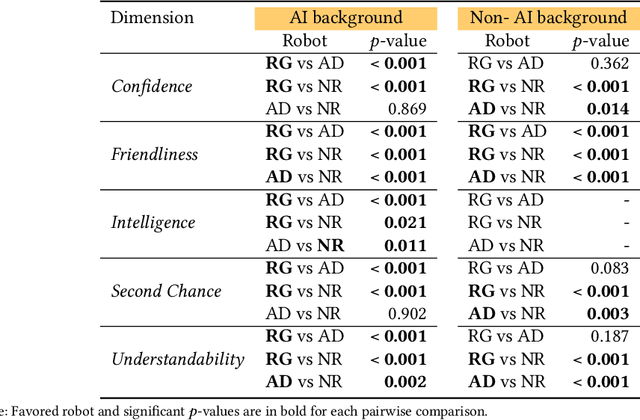
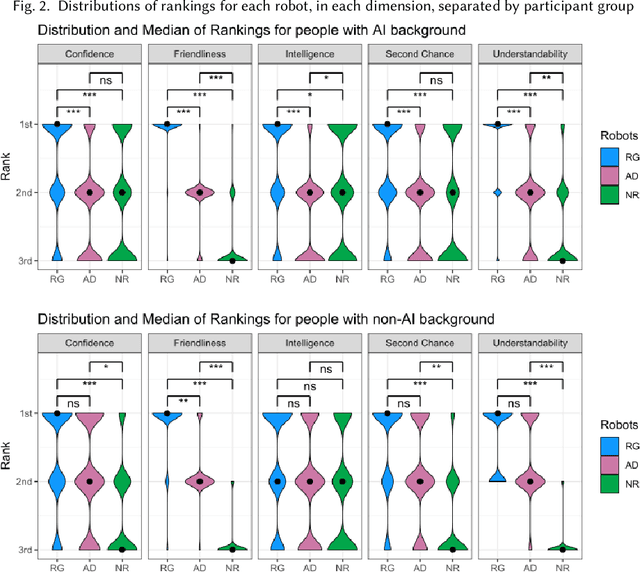
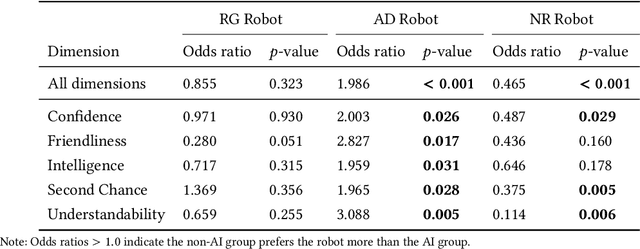
Explainability of AI systems is critical for users to take informed actions and hold systems accountable. While "opening the opaque box" is important, understanding who opens the box can govern if the Human-AI interaction is effective. In this paper, we conduct a mixed-methods study of how two different groups of whos--people with and without a background in AI--perceive different types of AI explanations. These groups were chosen to look at how disparities in AI backgrounds can exacerbate the creator-consumer gap. We quantitatively share what the perceptions are along five dimensions: confidence, intelligence, understandability, second chance, and friendliness. Qualitatively, we highlight how the AI background influences each group's interpretations and elucidate why the differences might exist through the lenses of appropriation and cognitive heuristics. We find that (1) both groups had unwarranted faith in numbers, to different extents and for different reasons, (2) each group found explanatory values in different explanations that went beyond the usage we designed them for, and (3) each group had different requirements of what counts as humanlike explanations. Using our findings, we discuss potential negative consequences such as harmful manipulation of user trust and propose design interventions to mitigate them. By bringing conscious awareness to how and why AI backgrounds shape perceptions of potential creators and consumers in XAI, our work takes a formative step in advancing a pluralistic Human-centered Explainable AI discourse.
"From What I see, this makes sense": Seeing meaning in algorithmic results
Feb 21, 2021
In this workshop paper, we use an empirical example from our ongoing fieldwork, to showcase the complexity and situatedness of the process of making sense of algorithmic results; i.e. how to evaluate, validate, and contextualize algorithmic outputs. So far, in our research work, we have focused on such sense-making processes in data analytic learning environments such as classrooms and training workshops. Multiple moments in our fieldwork suggest that meaning, in data analytics, is constructed through an iterative and reflexive dialogue between data, code, assumptions, prior knowledge, and algorithmic results. A data analytic result is nothing short of a sociotechnical accomplishment - one in which it is extremely difficult, if not at times impossible, to clearly distinguish between 'human' and 'technical' forms of data analytic work. We conclude this paper with a set of questions that we would like to explore further in this workshop.
Trust in Data Science: Collaboration, Translation, and Accountability in Corporate Data Science Projects
Feb 09, 2020The trustworthiness of data science systems in applied and real-world settings emerges from the resolution of specific tensions through situated, pragmatic, and ongoing forms of work. Drawing on research in CSCW, critical data studies, and history and sociology of science, and six months of immersive ethnographic fieldwork with a corporate data science team, we describe four common tensions in applied data science work: (un)equivocal numbers, (counter)intuitive knowledge, (in)credible data, and (in)scrutable models. We show how organizational actors establish and re-negotiate trust under messy and uncertain analytic conditions through practices of skepticism, assessment, and credibility. Highlighting the collaborative and heterogeneous nature of real-world data science, we show how the management of trust in applied corporate data science settings depends not only on pre-processing and quantification, but also on negotiation and translation. We conclude by discussing the implications of our findings for data science research and practice, both within and beyond CSCW.
Data Vision: Learning to See Through Algorithmic Abstraction
Feb 09, 2020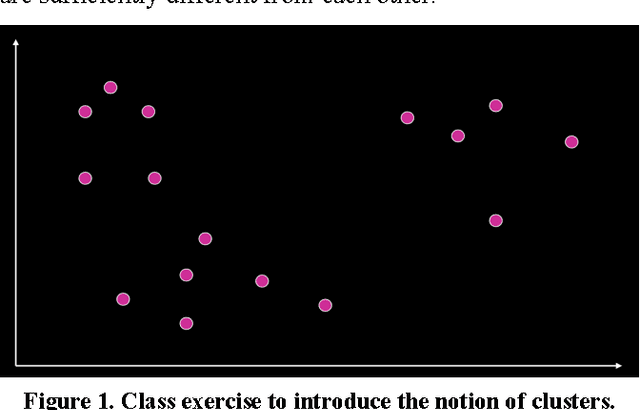
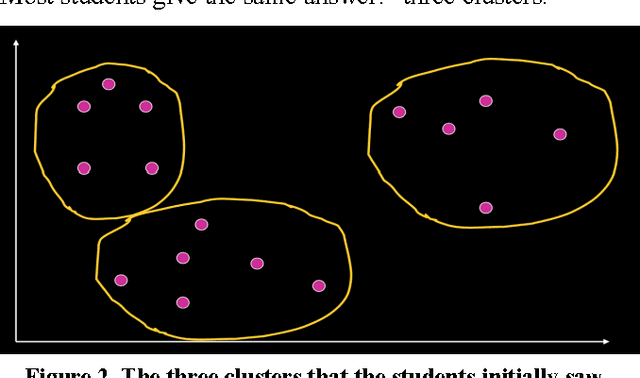
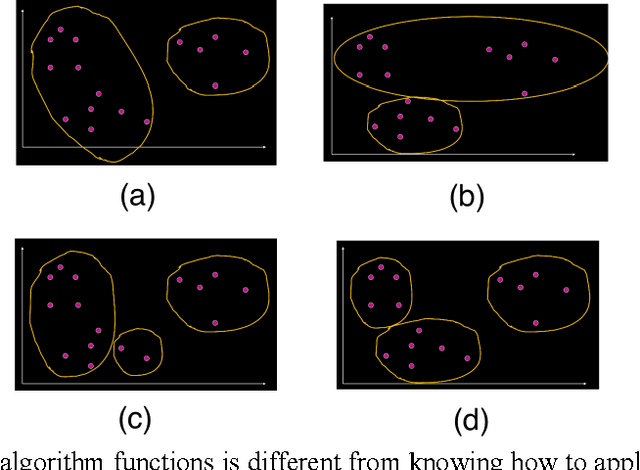
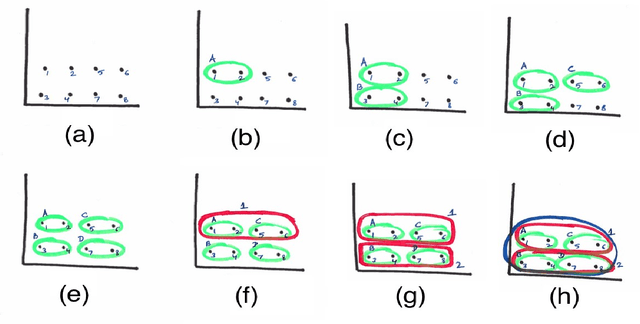
Learning to see through data is central to contemporary forms of algorithmic knowledge production. While often represented as a mechanical application of rules, making algorithms work with data requires a great deal of situated work. This paper examines how the often-divergent demands of mechanization and discretion manifest in data analytic learning environments. Drawing on research in CSCW and the social sciences, and ethnographic fieldwork in two data learning environments, we show how an algorithm's application is seen sometimes as a mechanical sequence of rules and at other times as an array of situated decisions. Casting data analytics as a rule-based (rather than rule-bound) practice, we show that effective data vision requires would-be analysts to straddle the competing demands of formal abstraction and empirical contingency. We conclude by discussing how the notion of data vision can help better leverage the role of human work in data analytic learning, research, and practice.